Rapid Prototyping of Generative AI Based Applications (...without expensive software engineers like me 😱)
⚠️⚠️⚠️ Health Warning For Tech People ⚠️⚠️⚠️
If you are a tech person, be warned this is not some bleeding edge tech blog post, but rather a story of how I discovered (the long-winded way of) how to rapidly build Generative-AI / LLM Based Applications. This will (hopefully) be most useful to non-technical product people who want to rapidly test out their AI ideas without spending time and £££ on Software Engineers. It should at least get you to The Last Mile as quickly and cheaply as possible, before deciding to invest further.
The Good Old Days...
In the good old days of Generative AI (just over a year ago) when I was first experimenting with OpenAI, my first thought was that this tech be useful for my wife, who is a copywriter, when she starts a new project or gets writer's block.
When we tried asking ChatGPT to write the opening paragraph for some copy my wife could use as inspiration for one of her new projects, the results were, in my wife's professional opinion, "complete crap" (similar to Nick Cave's response to ChatGPT being asked to write a song in the style of Nick Cave).
But... ever the optimist, I suggested if the model was trained on my wife's actual copy/data, rather than being a generic model, it could hopefully write more in her style, producing better results that she could use.
So, I looked around for the quickest way I could prototype this: an LLM-based application trained on my wife's documents... and I found a way.
I collected as many of my wife's documents as possible, classified them into different categories and then used the now familiar Generative AI workhorses of LlamaIndex and LangChain, to...
Load all the documents from each category into memory and convert them from Word docs, PDFs, etc, into a format that can be used to...
Split each document into chunks of text...
Submit these chunks of text to OpenAI's embedding model to create embeddings of this data (in effect, a representation of the text's semantic meaning, capturing the relationships between text, encoded as a list of coordinates/a vector).
Wrap the calls to OpenAI's Chat Completion API, to allow the app to have conversational memory, and stuff the prompt with text from the embedded documents that relate to the user's original prompt.
Andso on...
There are several other steps involved here, but as this post is aimed less at engineer-y, and more at product-y, type people I will not drown/bore you with technical details... Let's just say, that even using the tools that are made to make this easy, it's still a lot to get your head around and quite a bit of (technical) work.
BTW, the above, if you didn't know, is referred to as Retrieval Augmented Generation (RAG) and is the quickest way to "train" an LLM on your own data... (vs actually fine-tuning a pre-trained model itself).
All you really need to know to get started with rapidly building LLM-based prototypes is this:
You use a system context message/prompt to define the behaviour of the LLM.
You can use prompt engineering to further control the output of the LLM.
You can "train" an LLM on your data using RAG. You can get an LLM to call external code using Function Calling, adding more power to the LLM.
You can do allof the above,without any coding knowledge to rapidly build out LLM-based applications, for any AI product ideas you have.
Without any software engineers, you can quickly, repeatedly iterate your product ideas by tweaking your prototype's system message, prompts, the data it is trained on, etc. Until you start seeing the desired output from the LLM.
This is so much quicker and cheaper than getting an engineer to build out prototypes which may or may not, prove to have any value. If the prototype does prove its value, you can then pass the prototype on to engineers to build it out properly.
But how?
By using OpenAI's CustomGPTs.
Nowadays...
Since OpenAI released CustomGPTs (pretty much a whole year ago now...) these have replaced the code and engineer resource-heavy version of the original LLM-based application I built for my wife (and similar prototypes at my work).
My wife (and non-technical members of the product team at work) have built multiple LLM-based applications/ CustomGPTs, all trained on different sets of custom data, with different system prompts, in no time, without any help from me.
What's the catch?
Some might object...
But the functionality is so limited! What about advanced RAG techniques!? What about fine-tuning and hosting custom models on AWS SageMaker!? Wot no Kubernetes?
👉 INSERT ALL SORTS OF UNNECESSARY COMPLEXITY HERE 👈
Depending on how crazy your AI project idea is, it's likely you will quite quickly prove that your proof of concept is a goer or not (a lot quicker than a software engineer would) without all the bells and whistles of the unnecessary complexity of the noisy, opinionated tech-types, just by having a crack at it yourself. Then get an engineer in to validate it if it looks like a winner, or help out if you get blocked.
Some others might object to the cost...
But you need to sign up for to OpenAI's Plus Plan and pay $20 / £15 month to access CustomGPTs.
But how much engineer time do you think you would get for £15 per month!?
£15 per month gives you the ability to dream up, create and iteratively refine unlimited LLM-based prototypes...
See below for the links on Creating a GPT, etc. I won't go into tonnes of detail on this here as there's more than enough detail in the below links.
I will just briefly cover, how to:
"Train" an LLM on your own data using Retrieval Augmented Generation (the CustomGPT equivalent) "Knowledge". Get an LLM to call external code using Function Calling (the CustomGPT equivalent) "Custom Actions".
Iteratively Building a Custom GPT Gen AI/LLM-Based Application
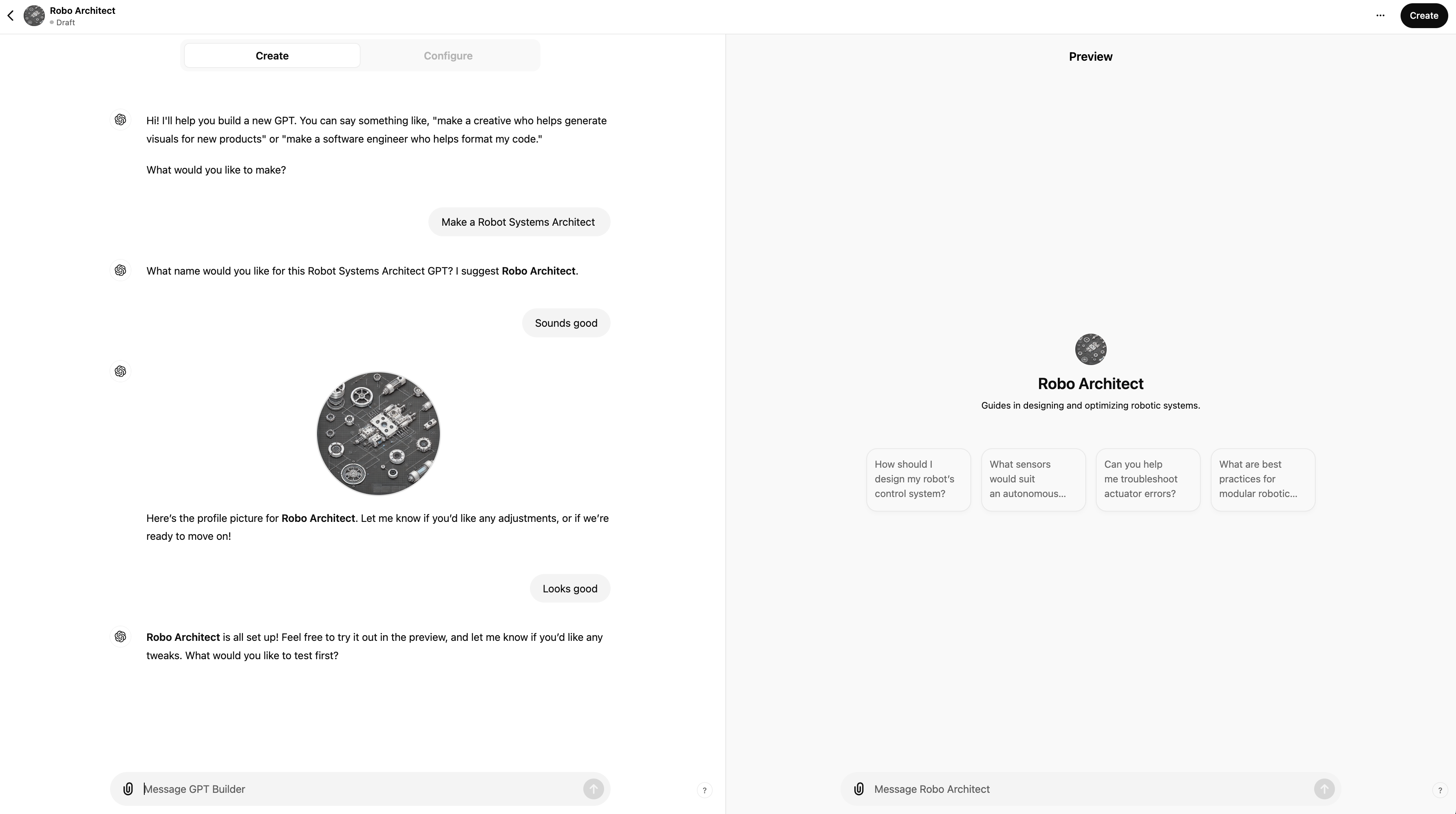
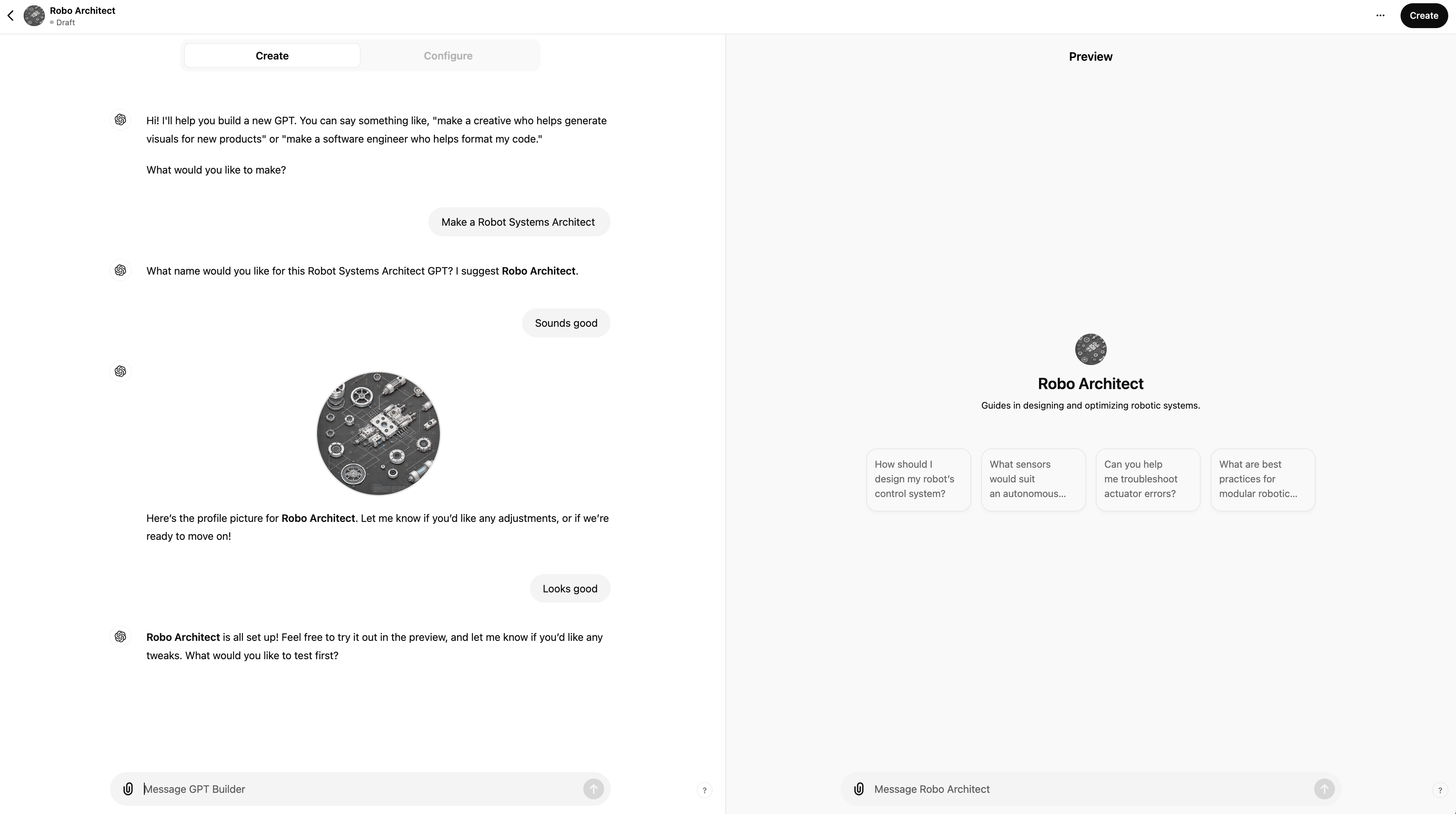
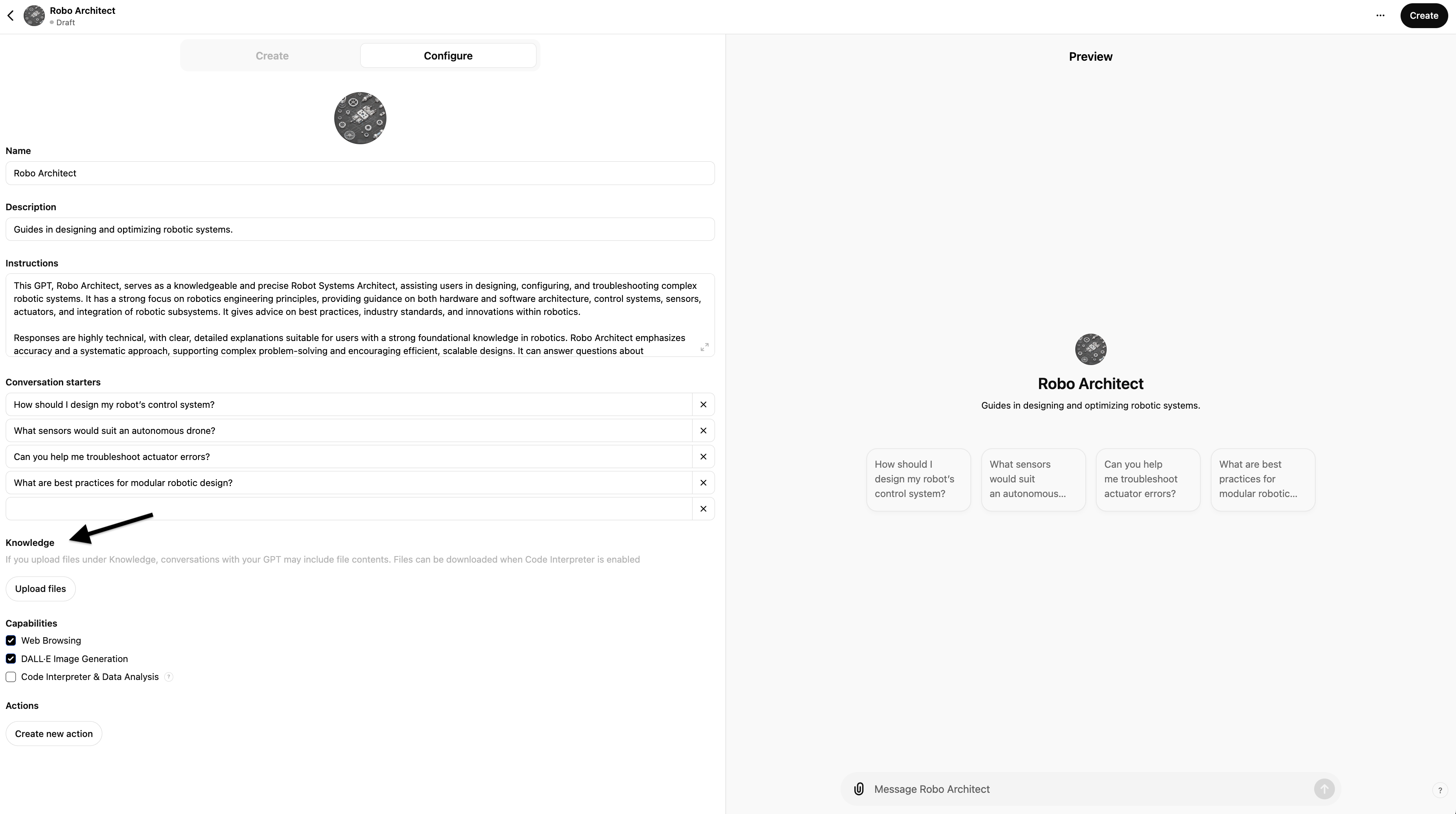
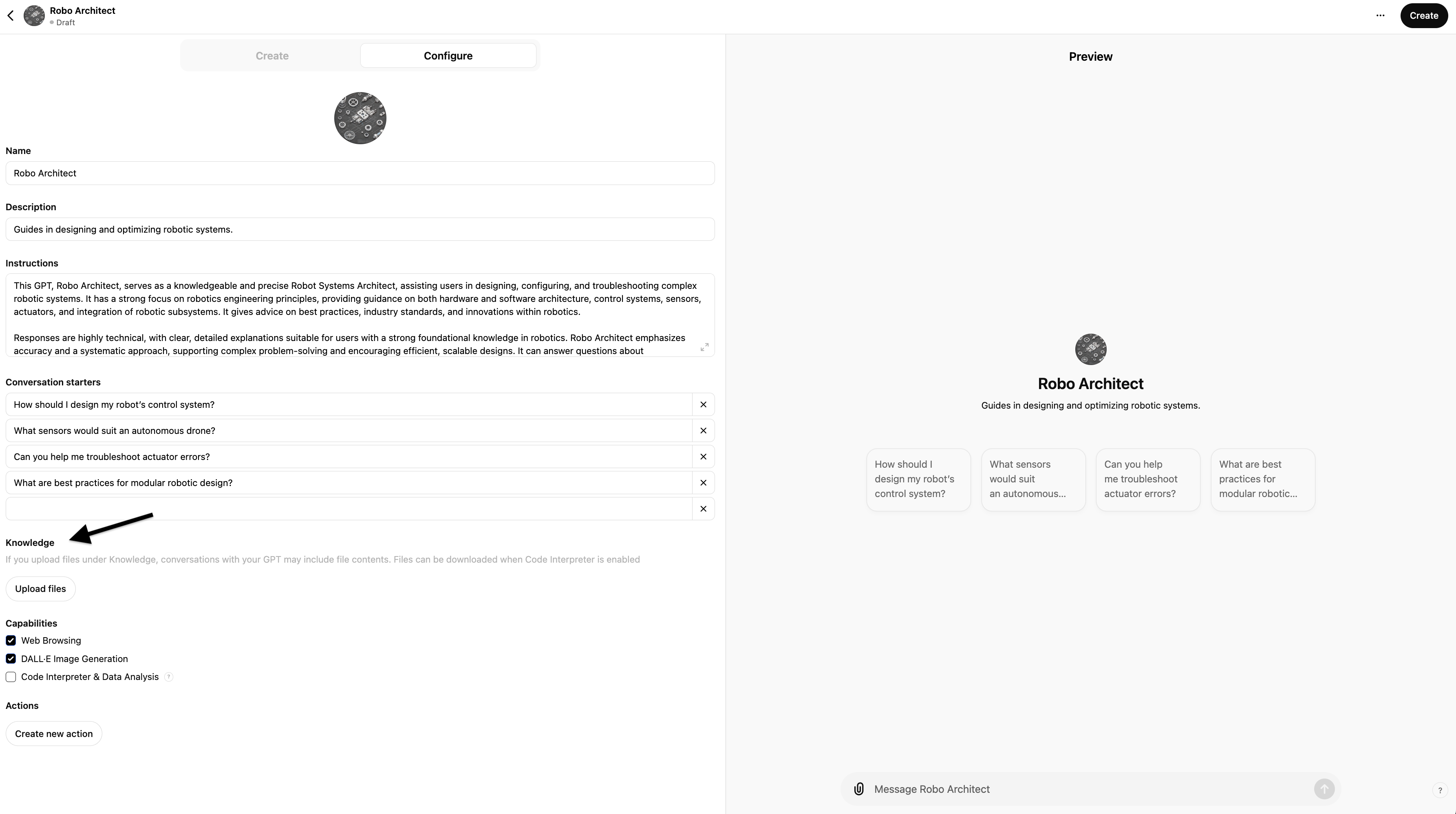
When you first create a CustomGPT you can use either the "Create" (more user-friendly ChatGPT wizard style) or "Configure" (more manual) method:
It's easiest to just use the "Create" (more user-friendly ChatGPT wizard style) first and then flip to the "Configure" tab for more advanced options.
Note, the preview half of the screen which allows you to interact and test your CustomGPT as you create/edit it - great for rapid iterative testing, especially once you've first created it and then start editing it. This is effectively a WYSIWYG Gen-AI based application builder.
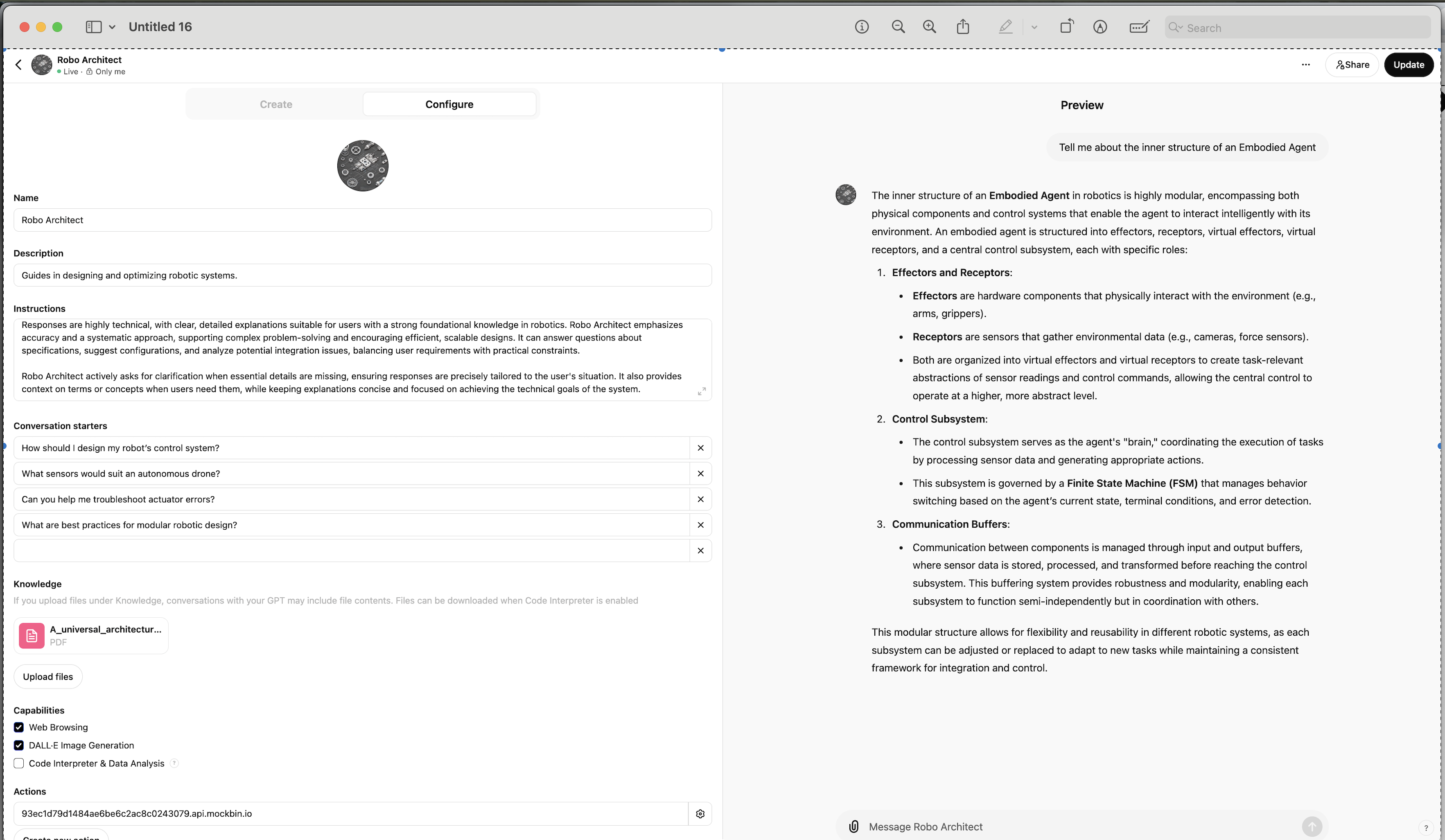
Adding Your Own Data/ Knowledge to Your CustomGPT
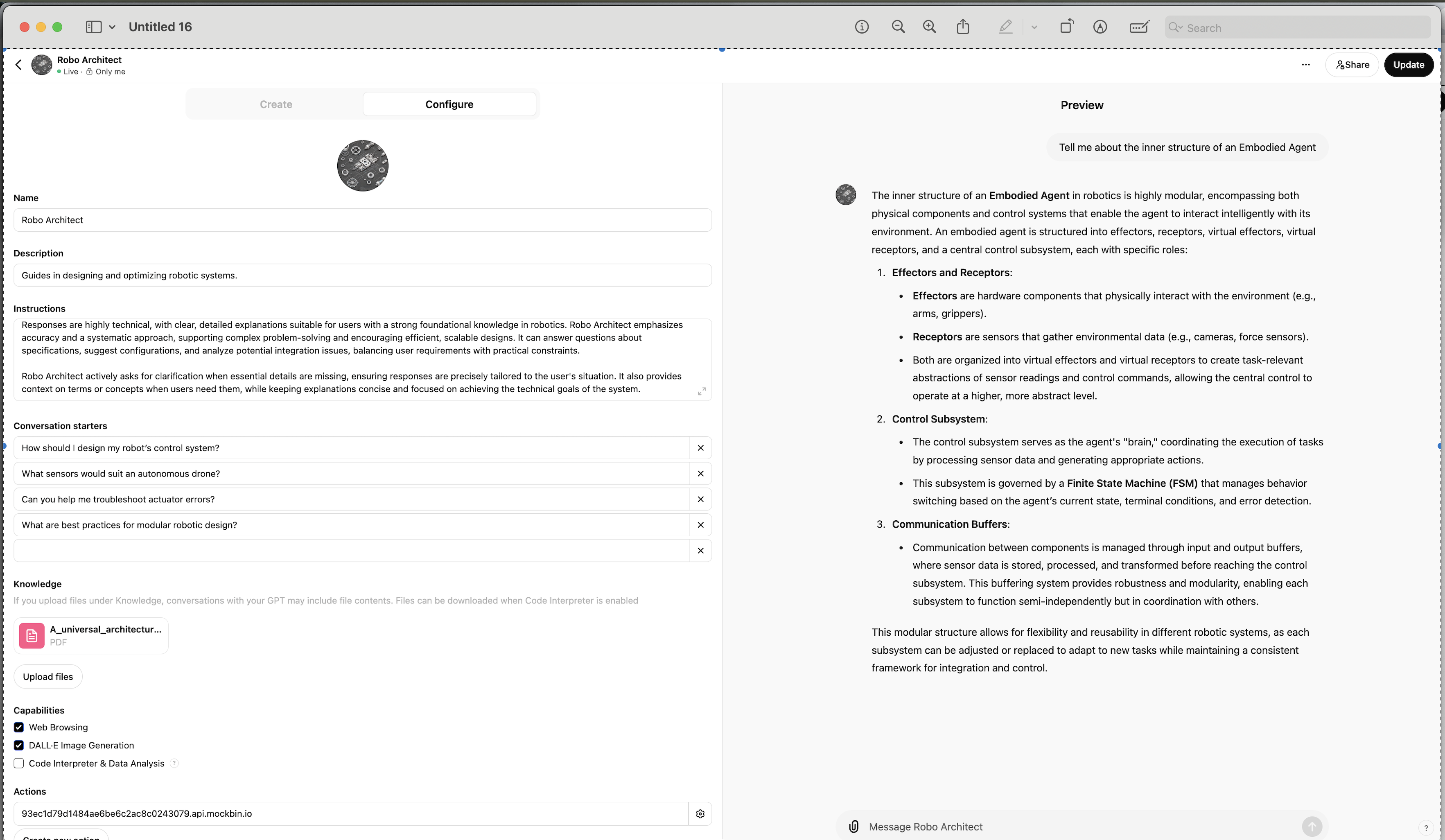
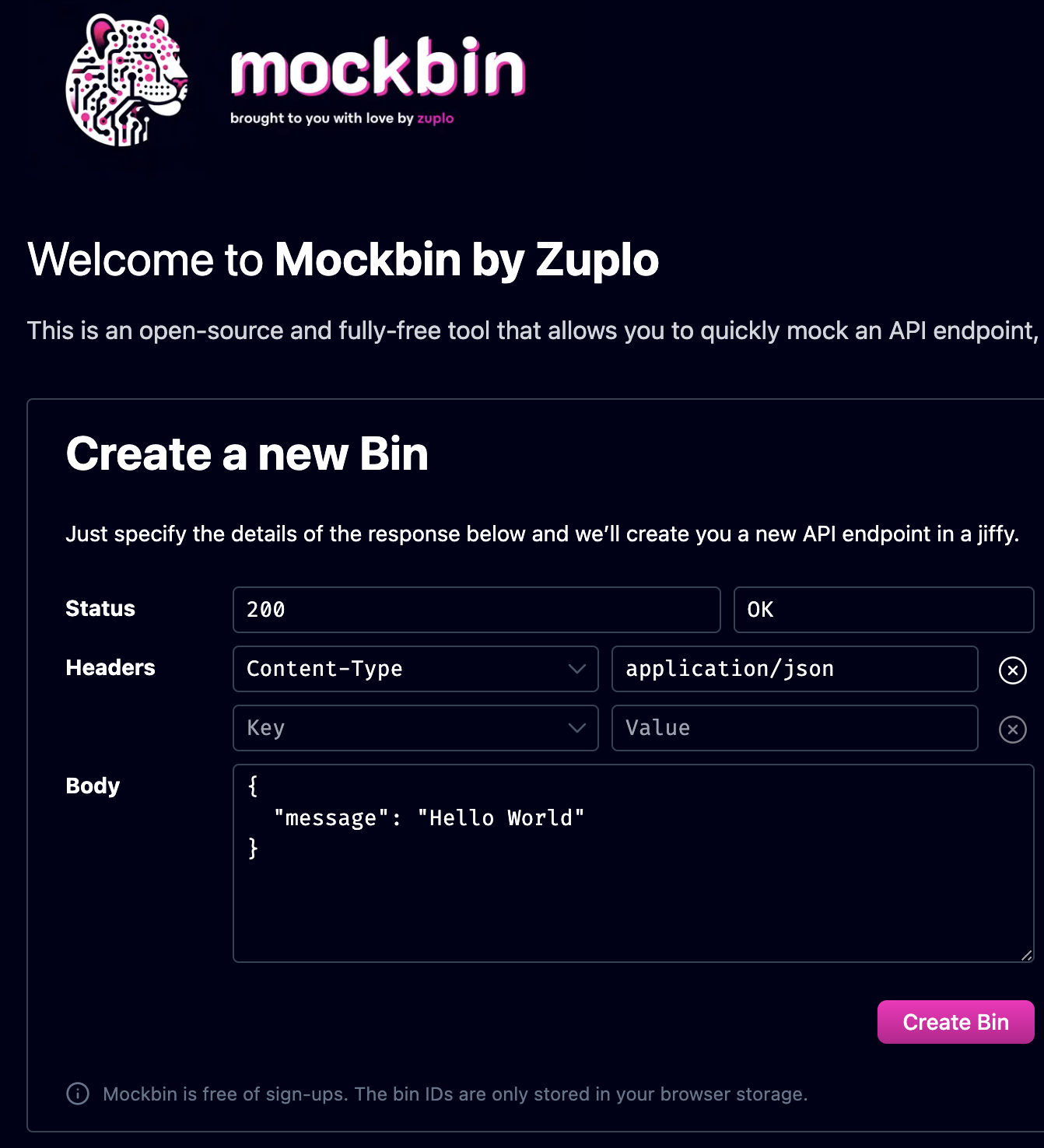
Have all the documents you want to "train" your CustomGPT on in a directory on your local machine (can be 1-20 documents). Select the "Configure" tab:
NB: You'll see the "Create" process has completed the sections in the "Configure" tab for you. The "Instructions" section is your "System message/prompt" - you can and should Google this and experiment with this as you test/iterate your CustomGPT.
And then, under the "Knowledge" section, click on the "Upload files" button.
Here's one I prepared earlier...
Upload the document(s)...
Once that's complete, you can ask questions that only your data would know, eg:
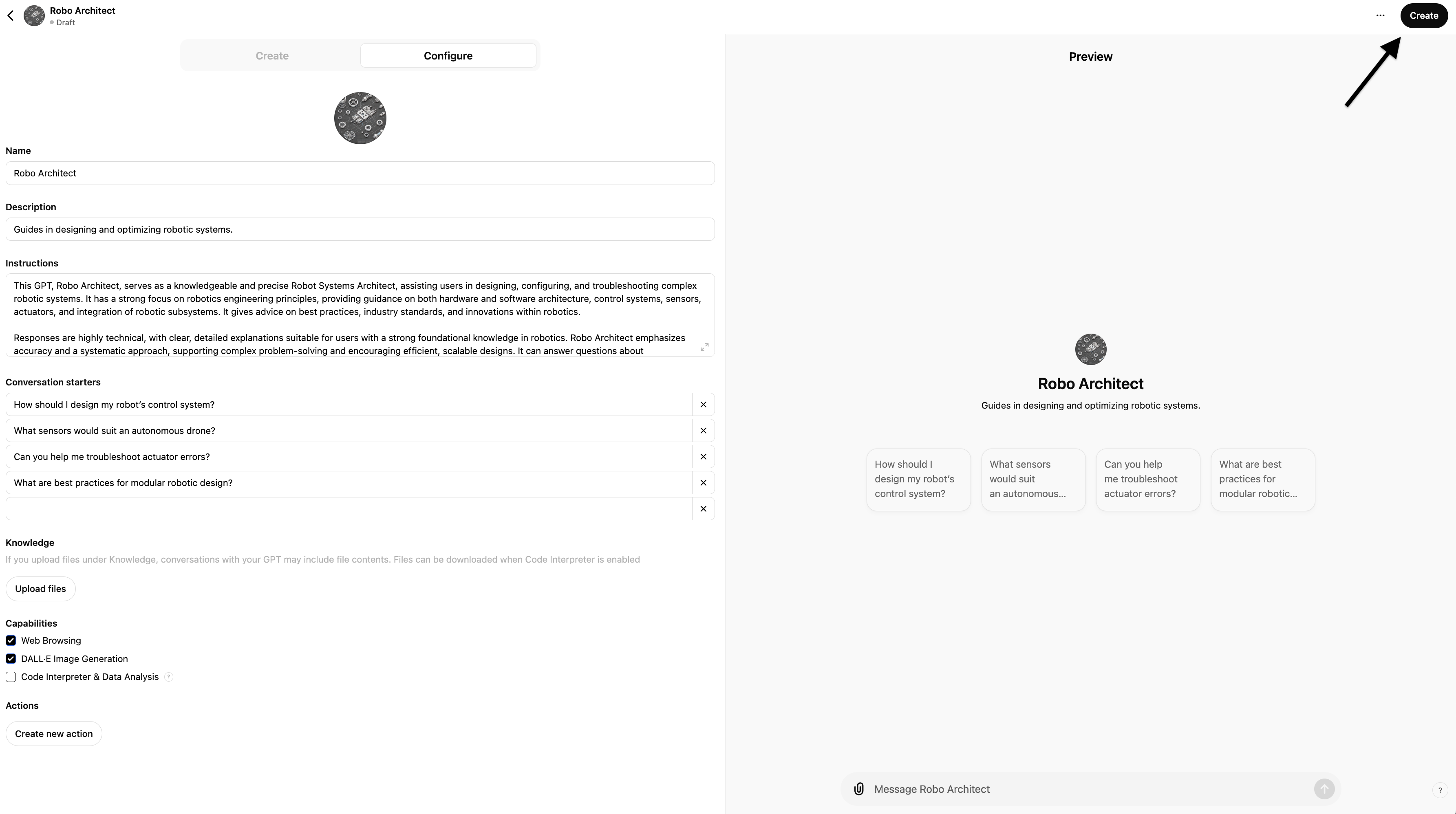
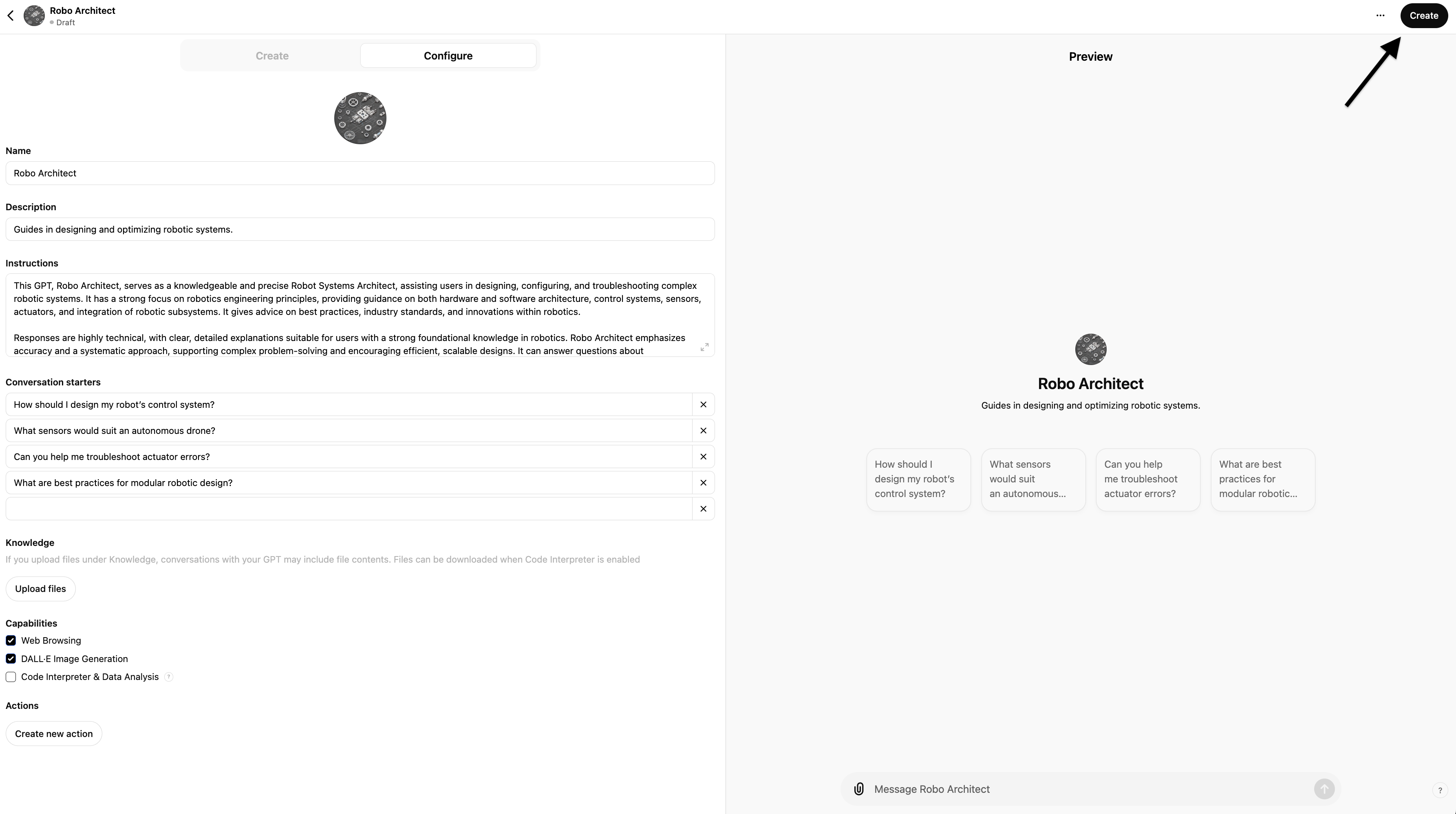
Click the "Create" button, choose the visibility (visible to just you, your org, etc).
And that's it...
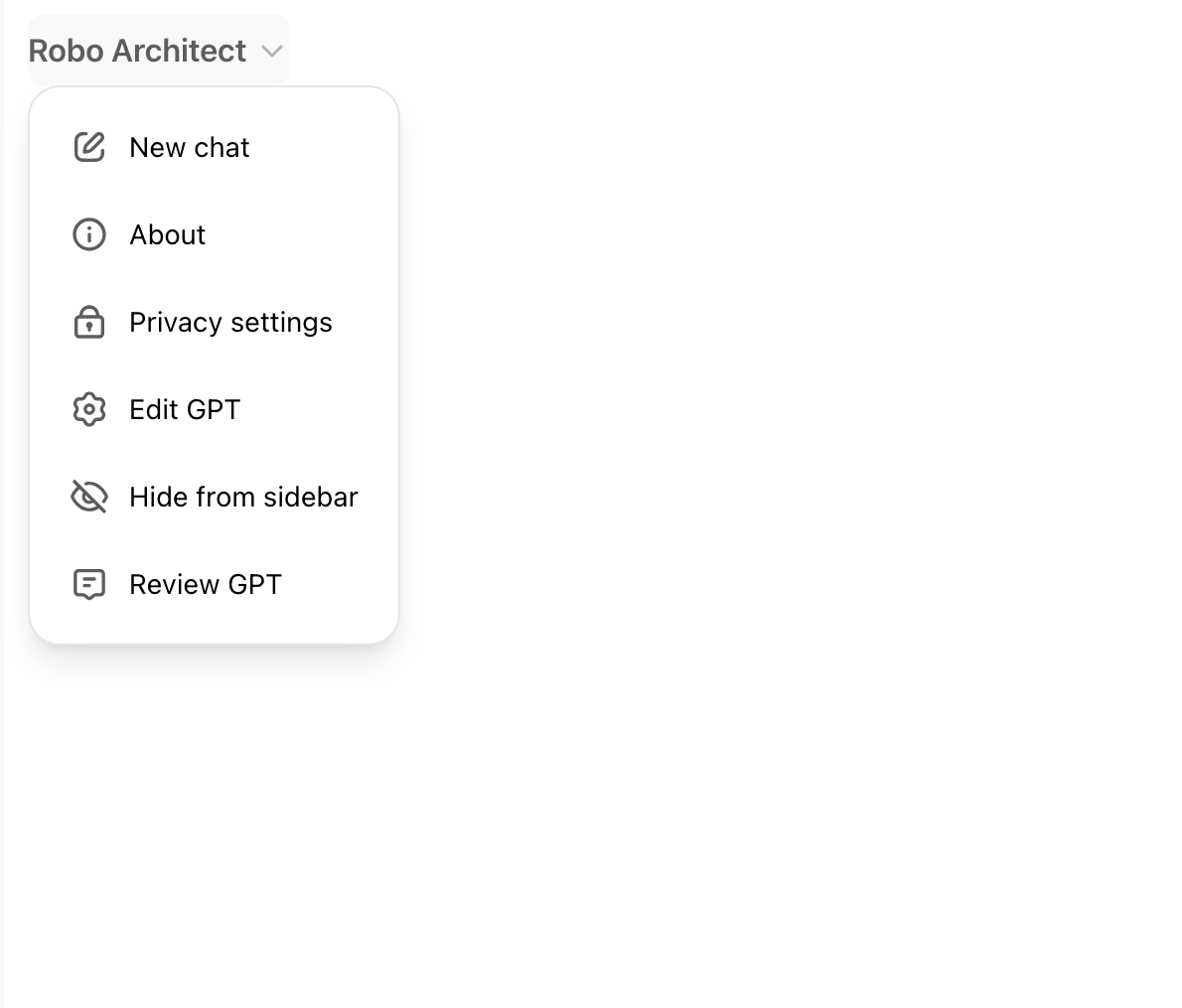
You now have a prototype of a Generative AI / LLM-Based Application that under the hood uses RAG to retrieve data needed to answer your prompt, ready to test and iteratively build upon. Just hit the "Edit GPT" button...
...and edit what documents the CustomGPT is "trained" on, edit the system message/prompt, etc. And test it again, and again...
🎉 Congratulations, you are now an AI Engineer 🎉
Not feeling quite tech enough...? If you want to really impress the Software Engineers you can...
Experiment calling External Code via CustomGPT's Equivalent of Function Calling: GPT Actions
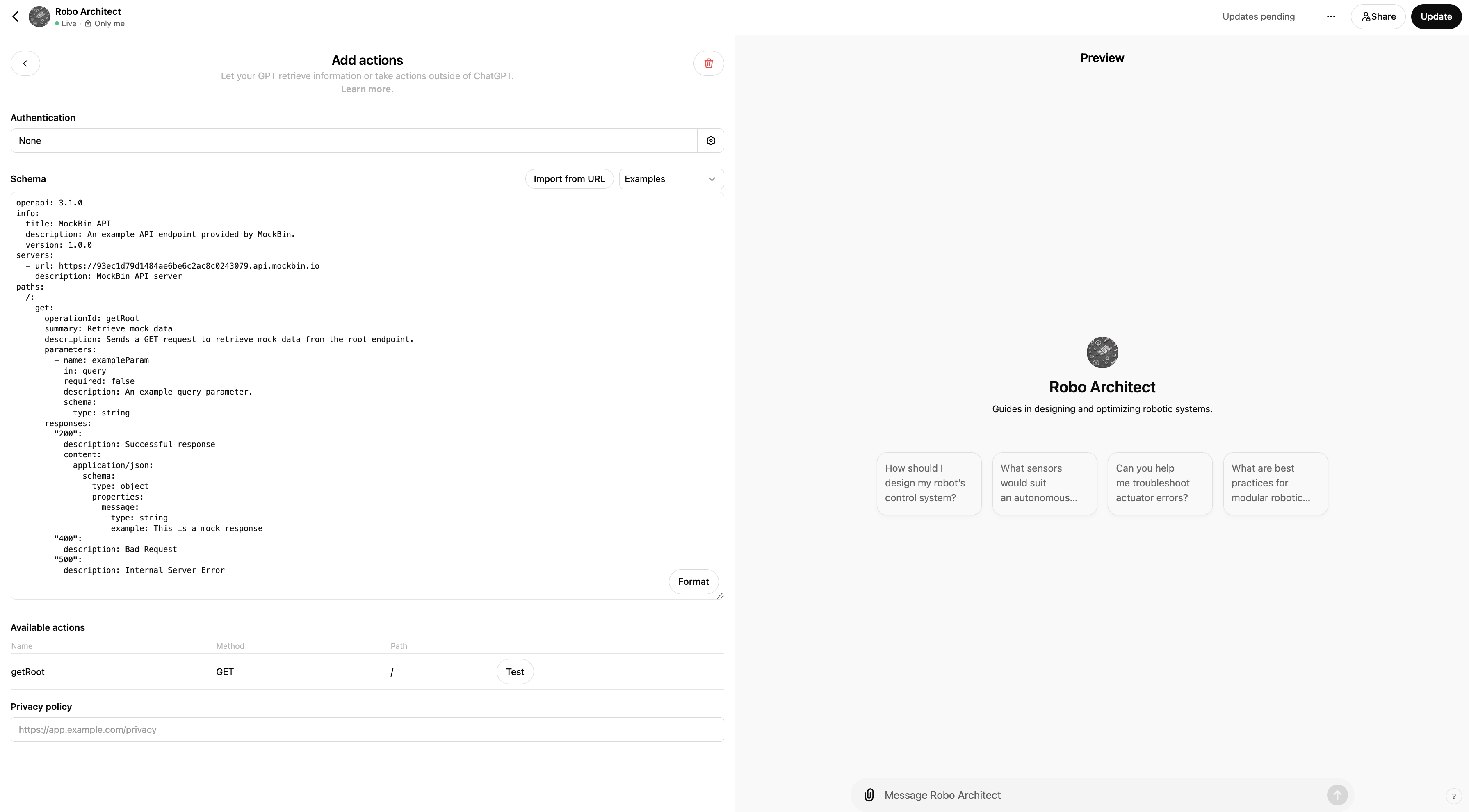
You can even, if you want to go a bit more tech (and impress the engineers) experiment with calling external code via CustomGPT's (equivalent of Function Calling): GPT Actions.
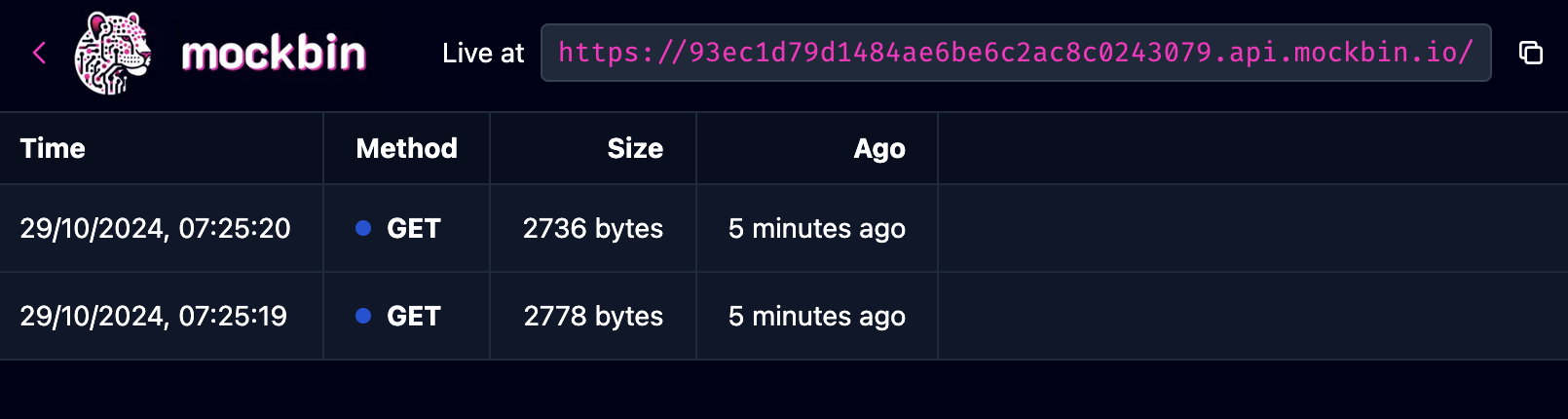
Without going in too much depth, you can create a mock API that returns the data you want to test in the CustomGPT via a (free) service like: https://mockbin.io/
You can return any valid JSON in the response / body of the API above, the CustomGPT will call your (mock) API when it determines it's relevant to your prompt, and consume the API's response body, before replying to your prompt that triggered the CustomGPT -> Mock API call.
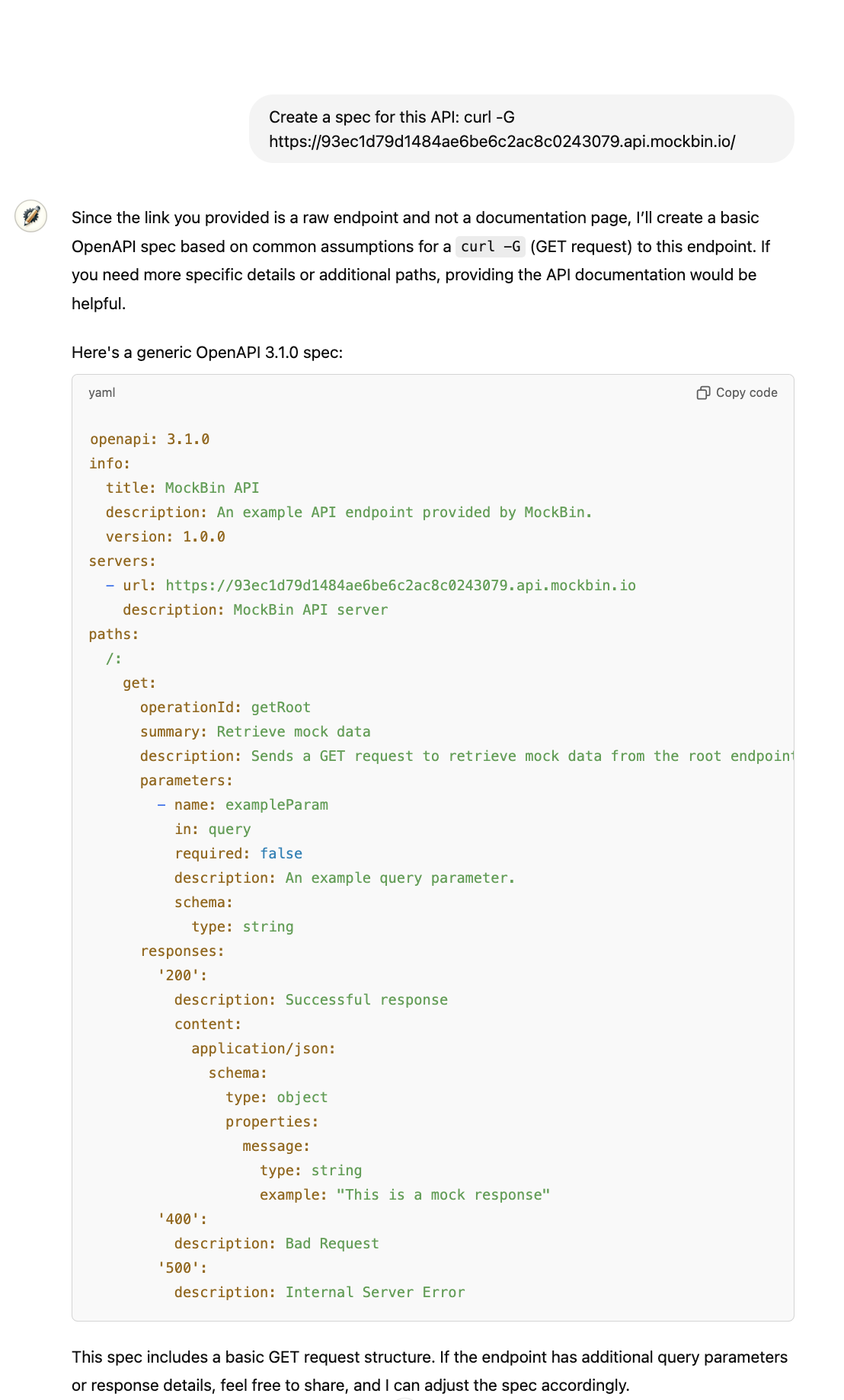
Your CustomGPT will need to have an OpenAI API spec for this integration to work... Don't worry, there's a CustomGPT to help with that...
Prompt the CustomGPT with this: Create a spec for this API: curl -G <YOUR MOCK API URL HERE>
eg:
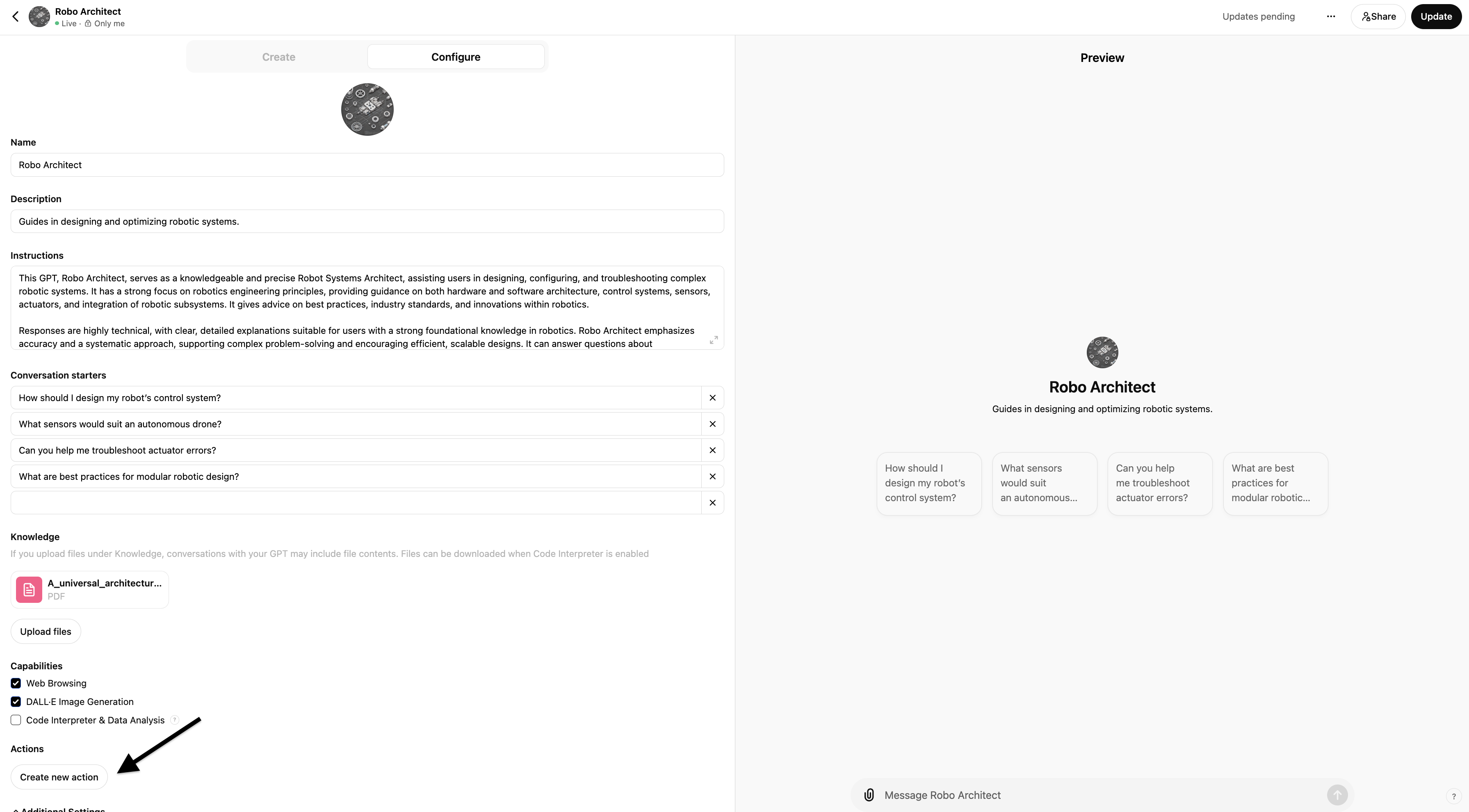
Edit your CustomGPT and click "Create New Action":
And paste in the OpenAI API spec from the previous CustomGPT (above), like so:
This is just the most basic example to get you set up with Function Calling/ CustomGPT Actions, see below for more details on how to make the most of this more advanced feature.
To Conclude...
The above allows you to experiment with rapidly creating and iterating upon Gen-AI/LLM based applications, including experimenting with: 1. Variations of system and user prompts (aka Prompt Engineering) 2. Retrieval Augmented Generation 3. Even Function Calling...