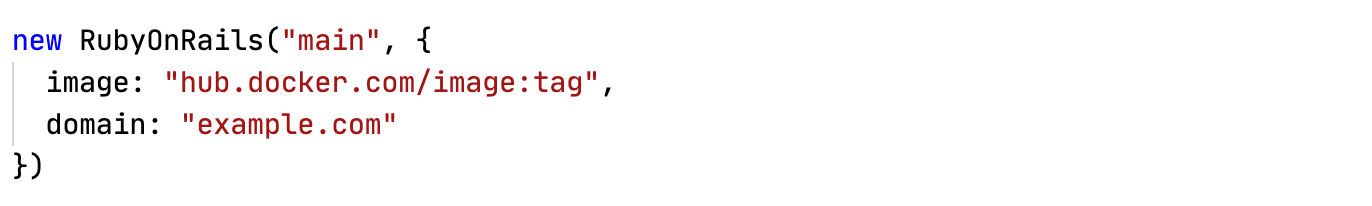За первые пару недель работы в Evil Martians, насмотрелся на кубовые ямлы и вспомнил на сколько же это все печально выглядит. Кажется, что YAML это просто, но на самом деле работа с ними создает в разы больше когнитивной нагрузки, чем это если это был бы код на языке программирования.
Прежде чем я раскрою мысль про сложность, сначала признаю общие преимущества модели управления инфраструктурой, которую нам дал Kubernetes:
1. Код описывает результат(декларативность), а не то как прийти к результату(императивность) 2. Есть базовые объекты, которые все понимают одинаково 3. Объекты работают одинаково в любой инфраструктуре и компании
Где возникает сложность
По отдельности и сами объекты выглядят и читаются довольно просто. Вот, например, Service. Все выглядит просто и понятно. Слушаем 80 порт, направляем трафик на поды app: MyApp на порт с названием http.
Пока мы используем один объект, все хорошо, но как только мы начинаем собирать из всех кубиков инфраструктуру приложения, сталкиваемся с необходимостью удерживать огромное количество контекста, чтобы сделать все правильно. Почему? Потому что все объекты имеют между собой связи, которыми YAML-ы никак не помогают управлять и никак их не подсвечивают.
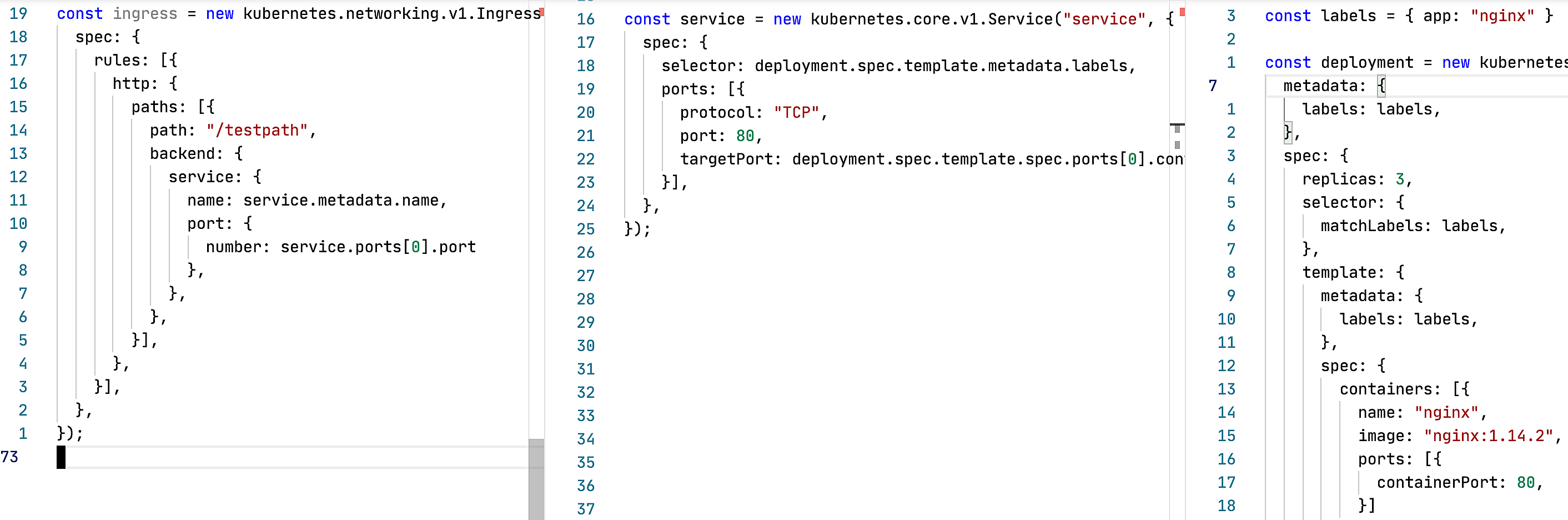
Возьмем для примера самый простой случай использования Ingress, Service и Deployment.
Всего 3 простых объекта. По отдельности выглядят просто, а на самом деле при работе с каждым из них требуется удерживать в голове кучу специфики взаимодействия объектов.
Какие нюансы связей я выделил на картинке выше:
Ingress 1. backend.service.name в Ingress должен совпадать с metadata.name в Service
2. backend.service.port.number должен совпадать с spec.ports.port в Service 3. metadata.name должен быть уникален в рамках Namespace
Без этих двух пунктов Ingress не сможет направить входящий трафик на Service и его поды.
Service 3. spec.selector в Service должен совпадать с spec.template.metadata.labels в Deployment 4. spec.ports.targetPort у Service должны совпадать с containerPort в Deployment 5. metadata.name должен быть уникален в рамках Namespace
Без этих двух пунктов Service не сможет найти поды, созданные через Deployment, и сбалансировать на них трафик.
Deployment 6. selector.matchLabels должны совпадать с частью лейблов template.metadata.labels 7. metadata.name должен быть уникален в рамках Namespace 8. Тут еще есть дополнительная сложность с тем что template.metadata.labels
Deployment, без совпадающих labels, не сможет понять за количеством каких подов ему нужно следить. А еще нам еще нужно убедиться что это уникальные labels в рамках Namespace, иначе Deployment может принять поды другого Deployment за свои.
Вы только посмотрите на это! Всего 3 объекта, а уже на ровном всплыло 8 нюансов, которые нужно знать и удерживать в голове, пока пишешь это все! Мало того, это все нужно поддерживать и при изменении одной сущности, нужно убедиться что ты не разломал все эти нюансы. Ни сам Kubernetes, ни специализированные IDE не могут указать вам на эти нюансы! Все приходиться делать своей головой! А это я ведь довольно простой пример взял, без миграций через Job, нескольких Deployment в приложении, StatefulSets, Secrets, PersistenVolumeClaim и т.д.
Почему проблема именно в YAML
1. YAML-файлики это просто статичный набор структур данных, которые на уровне кода никак друг с другом не взаимодействуют и ничего друг про друга не знают.
2. Линтер или LSP написать невозможно, потому связь между сущностями слишком неявная и мы не можем автоматически определить какие сущности с какими должны быть связаны.
3. YAML не может поднять уровень абстракции и как-то упростить работу с типовыми объектами.
Операторы с большим количеством связанных между собой CRD, пытаются как-то решать эту проблему, но все безуспешно. Лучший пример, который я видел, это Flux 2. Их сущность HelmRelease ссылается на сущность HelmRepository максимально явно.
Вот такую связь уже можно как-то проверять в IDE. Однако, кроме Flux 2 так практически никто не делает, а в базовых сущностях куба ничего подобного в принципе нет.
Как эти проблемы решаются языками программирования
Полноценные языки, в отличие от статичных структур данных, дают нам инструменты управления сложностью: переиспользование кода, явные связи объектов, абстракции.
Инструментов с полноценными языками для k8s хватает. Для кода на jsonnet: tanka, jsonnet, kapitan. Для кода на typescript, javascript, python: cdk8s от AWS и Pulumi. Pulumi так же позволяет писать код на Go и C#.
Terraform тоже пытается делать шаги в сторону языков программирования в terraform-cdk, но оно сейчас в экспериментальном состоянии, пока не могу рекомендовать им пользоваться.
Я приведу пару примеров решения проблем кодом на Typescript, в качестве инструмента -- Pulumi. Просто потому что эта комбинация мне нравится больше других ¯\_(ツ)_/¯
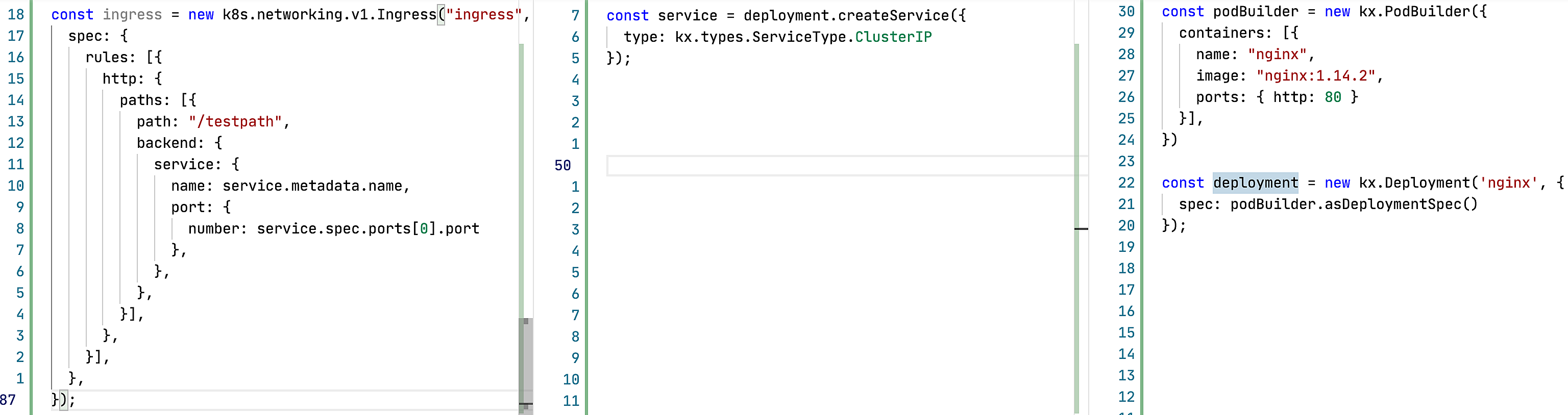
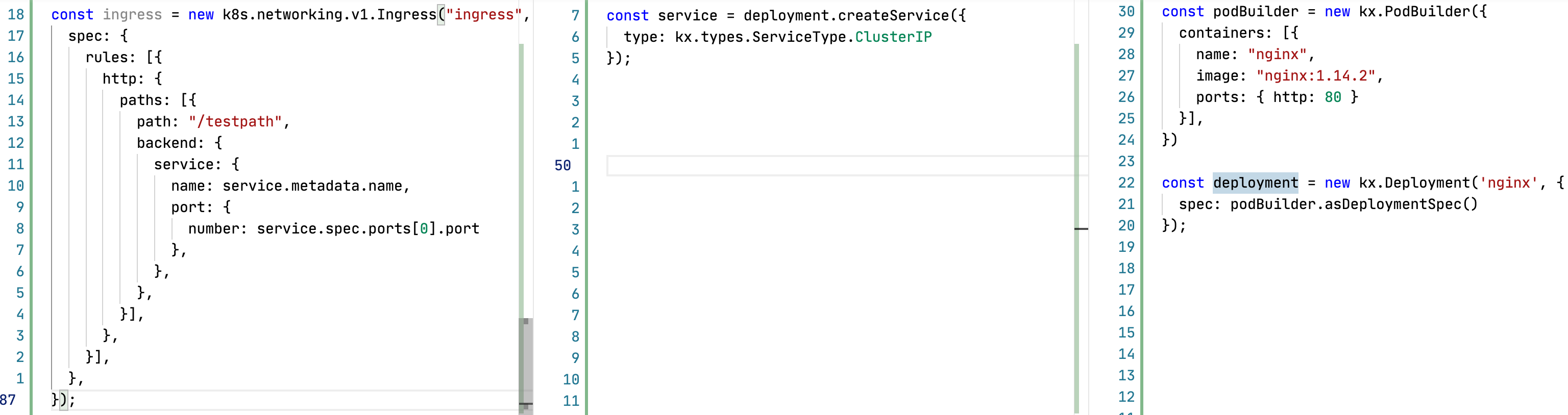
В данном примере я написал максимально близкий к оригинальным ямлам код, но уже решающий часть проблем.
Ingress Ingress забирает service name и port прямиком из Service. Это позволяет нам явно видеть связь этих двух сущностей, изменения в Service сами прилетают в Ingress, любая IDE или редактор подскажет, если мы как-то сломаем эту связь. Будет ошибка о несовпадении типов, попытку кидать из Ingress трафик в Service, которого не существует, и т.д.
Service В Service аналогичная история. Нужные данные берутся прямиком из Deployment, связь явная, меняем только в одном месте, IDE и компилятор не дадут нам совершить ошибку.
Deployment Одинаковые лейблы гарантируются через вынесение их в константу.
Таким образом я уже решил большую часть проблем, голове нужно думать о гораздо меньшем количестве нюансов, менять код стало сильно проще. Осталась только необходимость помнить о том что labels в Deployment должны быть уникальными в рамках Namespace, да и получение номера портов я сделал не очень красиво. Текущее решение потенциально может стрельнуть, но даже в таком виде тут гораздо меньше для совершения ошибки.
К счастью, это не предел того что можно сделать! Pulumi развивает библиотеку kubernetesx, которая поднимает уровень абстракции, забирает на себя сложности управления всем этим ужасом.
Это пример на kubernetesx. Кода гораздо меньше, он описывает только то что нам реально важно, все остальное библиотека взяла на себя. Описали как выглядит pod, дальше kubernetesx сам сгенерирует Deployment и Service.
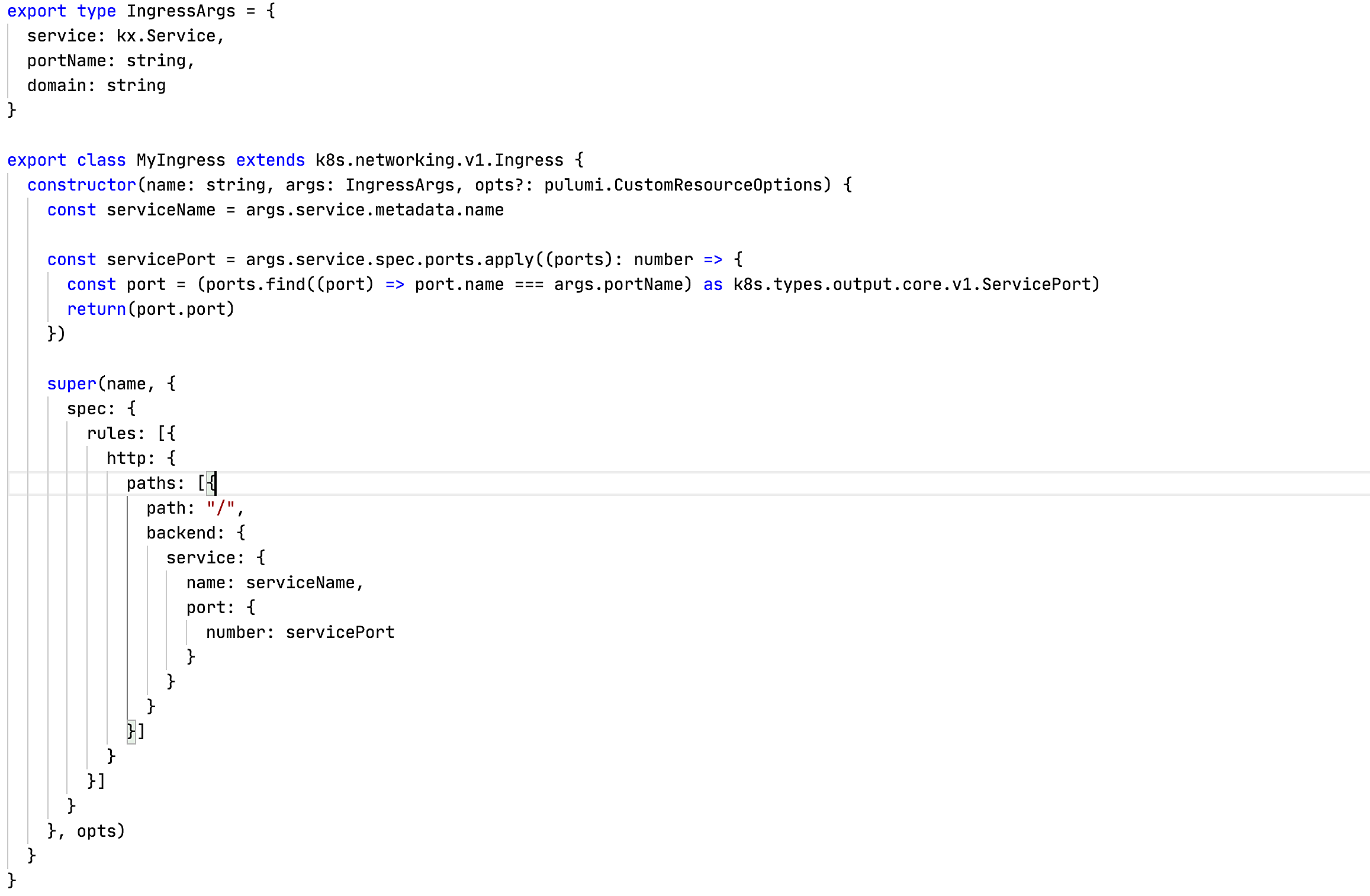
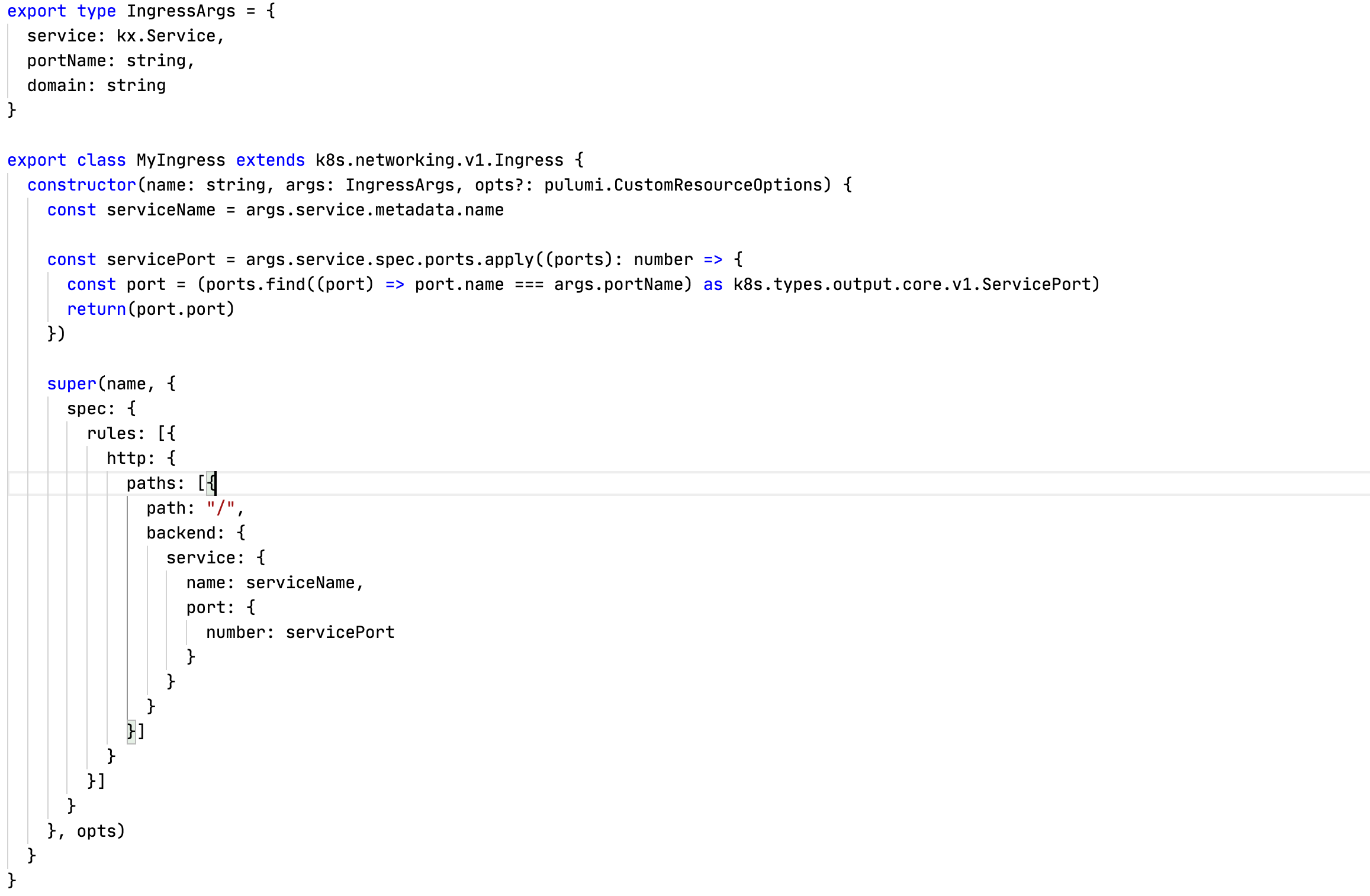
Да, для Ingress в kubernetesx еще не придумали хорошей абстракции, но можно сделать свою. Набросал простенький вариант для примера:
На описание этой абстракции у меня ушло примерно 5 минут. Да, она не идеальна, но уже снимает с бедной головы часть проблем.
С такой абстракцией кода стало совсем мало, и нам совсем не нужно думать про специфику взаимодействия между объектами. Код забрал все сложности на себя.
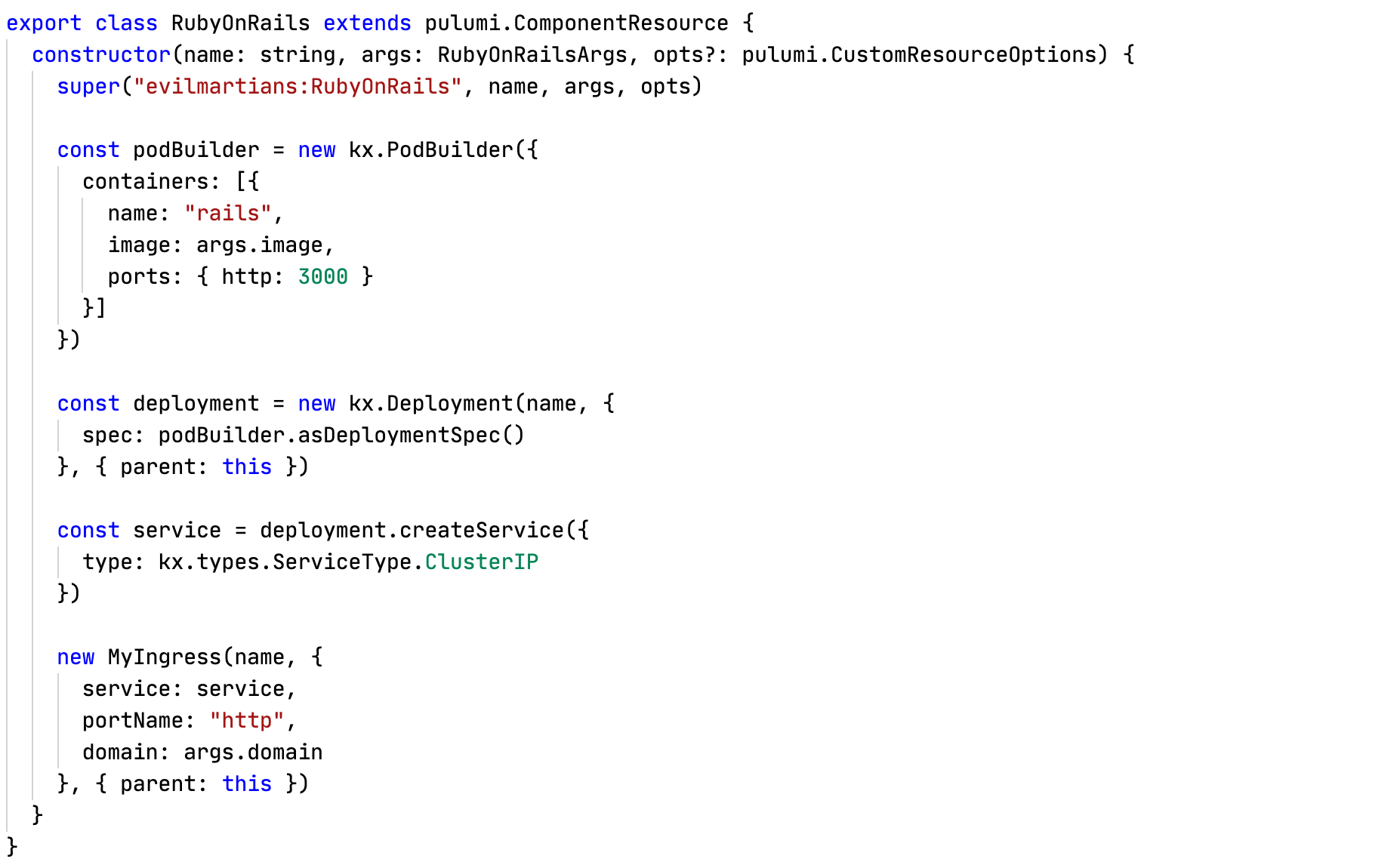
Раз уж я разошелся и начал писать кастомные примеры, давай пойдем еще дальше и сделаем абстракцию для типового приложения. В Evil Martians, например, большинство сервисов написаны на RubyOnRails, можно сделать для них абстракцию, которая прячет от разработчика всю сложность куба и оставляет только интересный ему контекст. Эта абстракция просто обертка над кодом выше, я ее написал буквально за 1-2 минуты. Разработку теперь вообще не нужно думать о кубе! Да, в реальном мире абстракция будет чуть сложнее. Например, в нее нужно будет добавить применение миграций, параметры sidekiq: true | false и requests/limits, но код от этого не станет сложнее :)
Код абстракции для Ruby On Rails:
Мой вывод
Сущности Kubernetes довольно сложные, из-за того что между ними много неявных связей, YAML никак не помогает нам управлять этим. Инструменты с полноценными языками программирования позволяют уменьшить количество специфики, которую приходиться держать в голове, через явные связи с помощью переменных, типизации, создания дополнительных абстракций. Чем меньше тебе нужно думать о том как оно работает, тем меньше когнитивная нагрузка и тем меньше ты устаешь от работы со всем этим бардаком!
При желании, можно очень быстро наклепать абстракций для разработчиков и облегчить и их жизнь тоже!
Ссылки
Инструменты с полноценными языками программирования
Уже после публикации я заметил что в примерах кода на YAML у меня отличается selector в Service от labels в Deployment. Вот видишь на сколько все плохо! 🤣