When designing an HTTP API, it is tempting to look at the common HTTP methods GET, PUT, POST and DELETE as CRUD operations with JSON objects that closely match database tables. In this post I'll show why that approach breaks encapsulation and how applying object oriented design practices improves the API and makes applying REST easier. I'll also show that thinking of resources as state machines makes it easier to identify API endpoints in a REST API.
Example
For this article I'll use a blogging system back-end as an example and keep it as simple as possible. The requirements of the system are:
Posts have an Id, a title, content and an optional publication date.
Posts can be edited until they are ready to be published.
Posts can be published.
Posts can be deleted.
CRUD breaks encapsulation
A (simplified) request to a CRUD HTTP API to edit a post would look like this:
PUT /posts/1
{
"title": "Hello world",
"content": "My first post.",
"publicationDate": "2022-11-01"
}
The problem here is with the publication date. It breaks encapsulation because the client has to know about the implementation of the publication mechanism. The client also has to be modified if the blogging system uses another publication mechanism in the future, coupling the client to this specific implementation and reducing the independent evolvability of the API.
There are also other problems with using the CRUD approach: What is the intent of the request when the publication date it is set and the title and content are modified as well? What if it is set to another date compared to what we have already registered? What if it is set to a date in the future? Do we then have to schedule the publication? This all makes the implementation of the requirement "Posts can be published." unclear and unpredictable.
An object oriented approach
Before looking at how to address the previous problems, let's get back to the basics first. What does the interface of the post editor look like? A well-designed interface would at least have separate edit fields for the title and the content, a save button and a publish button. Among many things, well-designed interfaces is what REST is also about:
"The name “Representational State Transfer” is intended to evoke an image of how a well-designed Web application behaves: a network of web pages (a virtual state-machine), where the user progresses through the application by selecting links (state transitions), resulting in the next page (representing the next state of the application) being transferred to the user and rendered for their use." -- Roy T. Fielding, Architectural Styles and the Design of Network-based Software Architectures, 6.1 Standardizing the Web
So the goal is to separate the save/edit command from the publish command, because they are two different state transitions. These transitions translate directly to methods on the post class: one to an update method for the title and content and another to a publish method.
These two commands can also be translated to API endpoints. For the edit command:
PUT /posts/1
{
"title": "Hello world",
"content": "My first post."
}
And for the publish command:
POST /posts/1/publish
That's right, there's no request body. Because the publication mechanism (the publication date) is hidden by the post class, the publish endpoint doesn't need to expose it either.
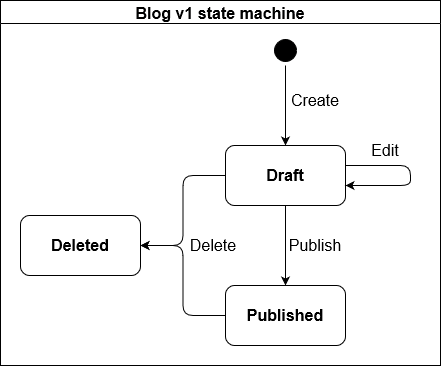
Introducing state machines
The object oriented approach naturally exposed the API endpoints for specific state transitions. Let's take it a step further and look at the entire lifecycle of a post with a state machine diagram:
It's great to see that every state transition (every arrow) translates to an API endpoint:
Create:
POST /posts
{
"title": "Hello world",
"content": "My first post."
}
Edit:
PUT /posts/1
{
"title": "Hello world",
"content": "My first post."
}
Publish:
POST /posts/1/publish
Delete:
DELETE /posts/1
This is of course besides the two endpoints to get a summary of all posts (GET /posts) and to get a full post (GET /posts/1).
Isn't this RPC?
Didn't I just replace CRUD with remote procedure calls? No. For the same reason that HTTP is not RPC and because REST is about representing state and state transitions. The redesigned API is all about that. The back-end implementation could also change radically without requiring the endpoints to change. It's just that thinking about state and state transitions is just as helpful when designing a (user) interface as it is when designing objects as it is when identifying endpoints in a REST API.
An HTTP API is not automatically a REST API. Stepping away from CRUD, thinking about the user interface and thinking about the lifecycle of an object makes it easier to apply REST.
Hey, thanks for reading. I'm a .NET developer and support specialist with over 20 years of professional experience. I blog about whatever occupies my mind the most at the time.