This is the text version of my talk last Monday at AWS London. We are strong believers that a disruptive change on EO is not only here, but will significantly advance the promise we've made for decades to understand Earth. Yes, faster better, cheaper, but also much more than that. Nothing new if you follow me :D
My key message on Monday at the geo day at AWS in London was that a fundamental shift in how we approach Earth Observation (EO) data is not just possible, but essential, with Geo Embeddings at its core. Phil Cooper, the host, introduced the session around the question of wether GIS has an identify crisis. I think that is not only true, but also that is because GIS has had an EO product problem for decades and finally AI seems to provide the stack to solve it... We must change GIS EO from pixel math and widgets, to frictionless semantic navigation through embeddings.
A very specific flavor of artificial intelligence --"transformers"-- is a pervasive theme across domains, and it application to Earth data seem lagging on real operationally impact. The central thesis of my talk, and indeed much of our work, with Clay and LGND AI, Inc. , revolves around the transformative power of these transformer embeddings on Earth data....
"embeddings, embeddings, embeddings"
The paradox of EO data is its simultaneous abundance and inaccessibility. Open-source streams and commercial imagery provide an unprecedented view of Earth. Geospatial experts can interpret this data for critical tasks, yet this granular analysis confronts an immediate barrier: scale. This limitation is, in my opinion, a primary reason why the EO market, despite a World Economic Forum projection suggesting a 1% increase in adoption could yield $9 billion annually, still punches below its economic weight. Also the reason why we've kept promising essentially the same dream of understanding Earth, and why that dream host not arrived yet, despite significant progress.
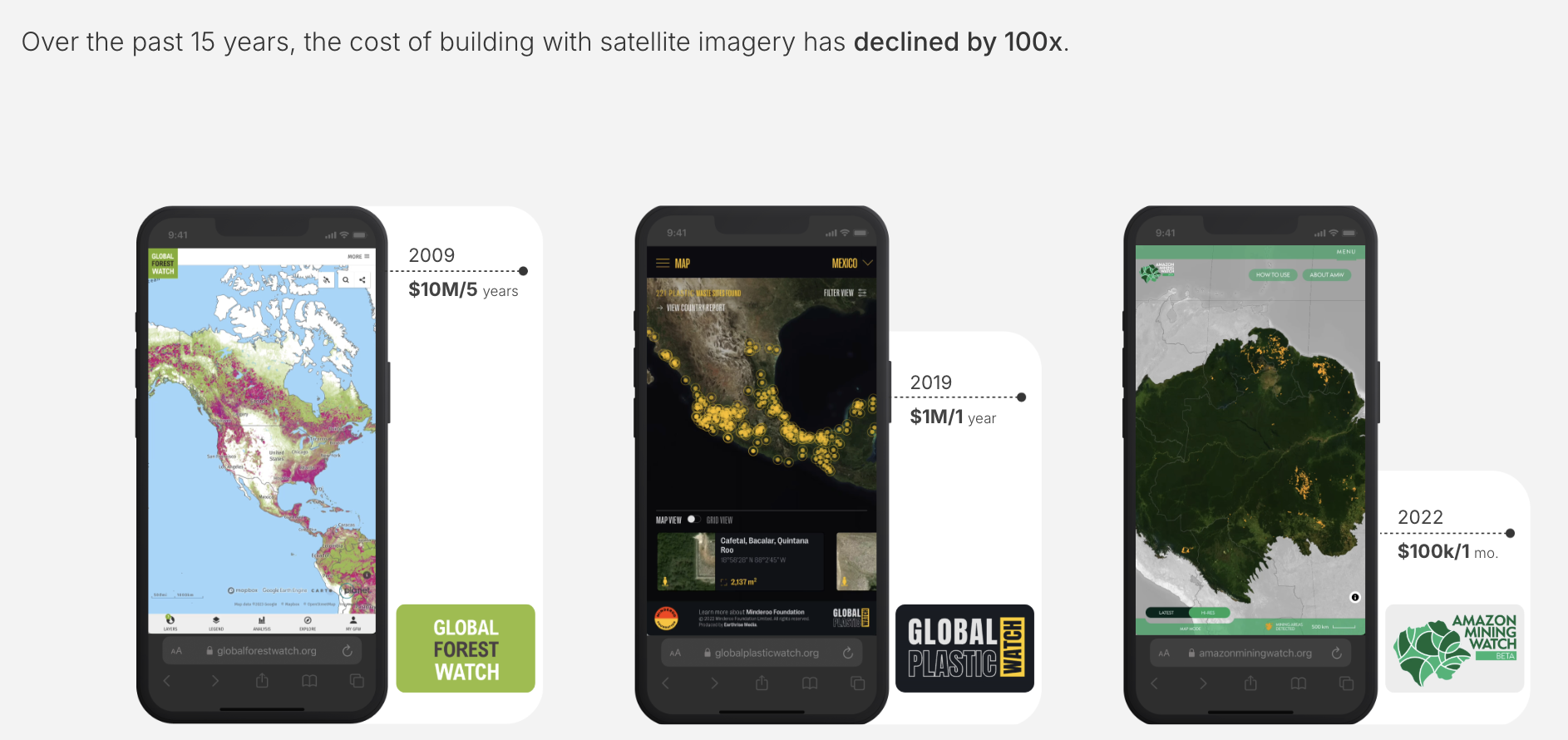
For many, the equation has been stark, regardless of how much you know about this field: the perceived costs of EO analysis have historically dwarfed the benefits. While specific application expenses have decreased (from $10 million over five years for Global Forest Watch in 2009 to $100k for a month's Amazon Mining Watch in 2022), a more profound efficiency leap is required. Beyond cost, we also need a "100x reduction" of skills if we want to meet the demand for answers. And beyond cost and skills, a "semantic" gap persists. Even sophisticated platforms can struggle with conceptually simple queries (try looking for grass in Google Maps), and text-based LLMs, for all their prowess, do not inherently "know" a place from satellite data in the way a dedicated GeoAI model might. Is like reading a travel book and claim you know that place.
Reading about a place is NOT knowing a place. LLMs read text about Earth.
The Rise of Foundational Models in GeoAI: Promise Meets Scrutiny
The aspiration for Geospatial Foundational Models (GFMs) is to create versatile, pre-trained systems that can be adapted to a multitude of downstream tasks.
This is not new, in fact aims for the track we have seen on "text" AI: Where we used to have "custom models", make the general "Foundational model", then "Finetune" it for a task. One of these finetunes is to reinforce human preferences - aka "RLHF" Reinforced Learning Human Feedback" -. Then iterate responses to catch wider patterns in context with "Agents". As we see agents struggle to keep focused, try to fix the collapse of thought with an "MCP" (which I see as APIs for AIs, that is ways to tell an Agent how to run external processes). MCP, our latest stage seem to give best results as it build a service that combines flexible "muscle" - Agents - with hard "bones" - MCP calls).
In GeoAI it seems we go stuck in the fine-tune applications....
However, this ambition is rightly met with critical scrutiny. Recent analyses, such as Christopher Ren ’s insightful piece, "Geospatial Foundational Disappointments," raise valid concerns that resonate with many in the field.
Chris points to the performance of the latest FM, IBM's TerraMind on the PANGAEA benchmark. Despite a substantial pre-training compute budget (estimated at ~9,000 A100 GPU-hours, or ~10²¹ FLOPs), TerraMind-L reportedly edged out a supervised U-Net baseline by a modest average of approximately +2 mIoU. Crucially, it lost ground on five of the nine datasets, including a significant performance drop on AI4Farms. His analysis further suggests that many GFMs appear "under-trained" relative to their capacity, operating with far fewer training tokens per parameter (≲ 0.1) than the ~20 tokens/parameter heuristic found to be compute-optimal for language models by the Chinchilla study (there's no Chinchilla study for Earth data). The sobering conclusion, to Chris, is that a 100,000x jump in compute for TerraMind yielded only a marginal average mIoU gain, indicating that current pre-training objectives (often pixel-reconstruction or contrastive losses) may be misaligned with pixel-wise segmentation tasks and are not scaling effectively with increased compute and data. For practitioners already running tuned U-Nets, the marginal utility of adopting these early GFMs, especially given the integration costs, can seem questionable.
A Broader View: The Case for Continued Investment in Geo FMs
These are critical observations, and such rigorous analysis is vital. We at Clay are among those who have invested significantly in this approach, thanks in great part to the generous support and trust of our partners. My perspective, however, is that viewing FMs solely through the lens of outperforming highly specialized models on specific benchmarks can be a narrow, and perhaps unfair, assessment.
The intrinsic value of a foundational model, much like that of a stem cell, lies not in its perfected state as one specific cell type (e.g., a lung cell), but in its vast omnipotential – its capacity to differentiate into many forms. I see FMs as embodying this principle of "undifferentiated compute" upfront. The aim is to capture common, transferable semantics across a wide array of tasks. While a U-Net is meticulously trained for a specific segmentation task, an FM aims for broader understanding. Literally CNNs are designed to care about subtle pixel patterns within narrow size of their kernels, and they are unable to scale that "semantic catchment area" efficiently, even through layers... In constrast transformers, while extremely slow to learn, do attend to correlations in very far distances, while also anchoring into the pixel values.
From a pragmatic point of view, the world has committed billions of dollars to Transformers. There might be better choices, but "we" chose that one. This unparalleled effort has created an incredibly fertile ground of ideas, innovations, and experience. Any investment in "Transformers for X" – including geospatial applications – inherently benefits from this vast, cross-subsidized research (papers like that Chinchilla study were not produced without significant computational resources). It is therefore not surprising, and indeed desirable, that most Geo FMs incorporate tools and learnings from other domains. The stakes for GeoAI are immense. This alone makes EO transformers worth study over and over again.
One of the defining factors of the entire EO space is its deep roots in large defense budgets with highly skilled partitioners. But in order to expand onto the new vision and market of EO, in areas like climate change, and sustainability, for a user base without those budgets or skills, we urgently need the inverse: tools that demand minimal resources and skills, empowering the broadest possible user base. Consider the impact of ChatGPT for information access by so many people for so many great applications; this is the kind of accessibility and value we should strive for in GeoAI. Products based on AI transformers have proven, in many fields, to deliver this.
This is why we created Clay, and we never paid much attention to academic benchmarks. While benchmarks are useful, they should not become the sole arbiter of value; "when a measure becomes a target, it stops being a good measure." For practitioners, pragmatic considerations often outweigh a few extra mIoU points: Is it free? Can it run my data? What's the license? Is it hard to use? We focused on those usability and accessibility questions.
Our focus shifted strongly towards embeddings as the primary output. We believe these dense representations allow us to achieve remarkable results, such as a 0.96+ R2 land classification of California in 20 minutes, or mapping above-ground biomass, sometimes in seconds, at near-zero marginal cost for each new output. This stands in stark contrast to the skills, time, and cost required to train a new U-Net for every task.
Critiques like Chris' are invaluably important because this geoAI pursuit should not be "free play of the free intellect." If domain experts alone dictate the research agenda and its perceived utility, we risk merely curating our Google Scholar or LinkedIn profiles. This is a sentiment I explored extensively in my book "Impact Science" (Amazon or free book) With due respect to the vital role of academia, Clay priority was never an academic or research project. Clay is, in fact, a product of that academic work, taking best ideas from latest papers. And we do all our work in the open, so we can share back, just not through research outputs. Sadly we had little bandwidth to produce those outputs. Our priority, and the impetus behind our combo with LGND, is to mix latest research with partitioner needs to ensure we empower the maximum number of people using geoAI. To quote a former president of the Cancer Association on cancer research, "at some point, you need to save lives." Similarly, at some point, FMs must demonstrate critical, material impact for end-users, not just incremental gains on benchmarks. That impact can be measured in many ways alongside benchmarks ... like stories of organizations effectively applying this technology to real-world problems. One approach is not better than the other, they just have different priorities.
Our bet on embeddings is a high-risk, high-reward endeavor, and we are immensely grateful to partners who share this vision. Both on the model side to reduce the CAPEX as an open asset through a non-profit Clay , and to reduce the OPEX for users through the servicing layer with LGND AI, Inc. .
Geeky addendum: I have a hunch that the Chinchilla scaling laws for text, suggesting ~20 tokens per parameter, may not directly translate to Earth data. Text is unconstrained, encompassing fiction, errors, and myriad styles. Earth data, by contrast, is almost entirely grounded in physical reality. I suspect Earth is "semantically denser and ergodic," meaning there's significant spatio-temporal repetition, allowing models to learn robust representations with potentially fewer tokens per parameter – perhaps an order of magnitude less. Vision Transformer (ViT) patches are also "anchored" spatially, unlike free-floating text tokens, which might greatly accelerate learning dynamics. ... I predict that within 2-3 years, most new Geo FMs will converge on broadly similar semantic understandings, which is another compelling reason to foster openness and drive these models towards becoming a commodity, or even a utility.
From finetune to embeddings
All along the AI stack we have embeddings, which are simply vectors that encode the input. They are not perfect but they are orders of magnitude smaller, so to the degree they are correct, they unlock huge value. For many applications and domains, they are simply part of the internal pipes of the AI stack, subject to academic studies as a way to understand the internal brain of a model.
I conceptually imagine embeddings as a cloud of dots, each a datapoint representing a semantic. Then all input data falls into these dots, connected as a path. The AI then needs to figure out how to locate those dots so the paths are simple, reused, predictable. Those paths become reality encoded. Those paths allow to navigate reality through semantics, bringing along space and time, which unlocks an entire new paradigm of finding stuff, monitoring stuff, causality, ...
For geoAI we started to look at them more closely, since Earth data is crucially different. Not only we have a large but limited surface, Earth, but we encode many similar semantics in place and time, which is turn represent most of the work for most of the outputs users need.
This embedding-centric methodology represents a significant departure from traditional GeoAI workflows, forgoing the reduced but still intense finetune workflow. In fact, through experience, we ended up not only promoting them as perhaps the new center of value for geo, but also the basis to build a service provider Lgnd: Leveraging pre-trained embeddings from models like Clay, potentially with Retrieval Augmented Generation (RAG) and minimal labeling, yields actionable insights in seconds. This finally democratizes access to sophisticated EO analysis.
The Embedded Future of Earth Observation
The true significance of this shift lies in unlocking value from EO data that has remained latent. One can envision climate models achieving new hyperlocal accuracy or conservation efforts gaining unprecedented timeliness. This is an evolving field; questions remain about representing homogenous features or integrating diverse geospatial data at scale.
Nevertheless, the path forward is clear. The capacity to create and utilize these imperfect yet remarkably detailed mathematical summaries of our planet offers in our opinion the most promising avenue for the next generation of geospatial innovation. It is about transcending pixel-level analysis to achieve a profound, semantic understanding of Earth. The question often posed is, "What is the ChatGPT equivalent for Geo?" Perhaps a more pertinent inquiry is how we can equip a diverse community with foundational tools, like these embeddings, to construct a multitude of tailored solutions that work with least clicks, least effort and least time. That prospect, I submit, is worth the risk that we are wrong.
PS: Thanks Samuel Barrett for the feedback on the draft!
About Bruno Sánchez-Andrade Nuño
Scientist. Impact Architect. Intellectually promiscuous. Stoic optimist… all that you need when working on tech innovation for climate change, socioeconomic development and biodiversity. By training PhD Astrophysics and rocket scientist. By way of #PlanetaryComputer