Last week I taught on a PhD-level summer course on geoAI, or AI for Earth, at the University of Copenhagen. I saw other speakers give their fantastic technical talks, some on fundamentals, and some on real specific applications. The organizers made a fantastic job to equip these selected and global group of PhD students with truly the latest and best in the field; depth and breath. So after listening to other speakers, I decided to scrap my prepared presentation. I had tweaked the one I usually do about Clay with more technical parts. I was going to present our Clay v1, the choices, the architecture, the training, the results. Instead I chose to talk straight to the most important point. The "so what".
If AI is, as it is said, as disruptive to society like the discovery of electricity, I'm convinced AI for Earth is our best chance to make it shine, a chance to help most people everywhere, using extremely high quality objective data, with comparatively fewer downsides.... But AI for Earth is not on the major leagues of AI efforts. None of the main players in AI do geospatial. This is partly because, few in the world do AI, and few in the world do geo... so the intersection of people people doing geoAI is a lonely cry of unmet potential. But that room, that group in front of me is that needle in the haystack. There are just a few groups like that one in the world, so this talk has the highest concentration of skill potential of our best AI for Earth. I didn't want to skip the chance. Most in that room probably want to continue in academia, some might go to startups and some to large companies. If they were anything like me when I was in their position, most of that room craved a compass to guide their path. And I was ready to share mine. My Why, What, How and When.
To share Why should they do AI for Earth, What that even means (to me), that How we build it matters, and When. The whole process of thinking about Clay, raising funds, using them, and what we want to do next was born out of those questions. More specifically the answers we came up with were too shocking not to try doing our best.
What follows is an adapted version of our discussion (I used no slides and it was very interactive).
Why?
Because it's the missing puzzle piece
If AI is, as it is said, as disruptive to society like the discovery of electricity, I'm convinced AI for Earth is our best chance to make it shine, a chance to help most people everywhere, using extremely high quality objective data, with comparatively fewer downsides.... But AI for Earth is not on the major leagues of AI efforts. None of the main players in AI do geospatial. This is partly because, few in the world do AI, and few in the world do geo... so the intersection of people people doing geoAI is a lonely cry of unmet potential. But that room, that group in front of me is that needle in the haystack. There are just a few groups like that one in the world, so this talk has the highest concentration of skill potential of our best AI for Earth. I didn't want to skip the chance. Most in that room probably want to continue in academia, some might go to startups and some to large companies. If they were anything like me when I was in their position, most of that room craved a compass to guide their path. And I was ready to share mine. My Why, What, How and When.
To share Why should they do AI for Earth, What that even means (to me), that How we build it matters, and When. The whole process of thinking about Clay, raising funds, using them, and what we want to do next was born out of those questions. More specifically the answers we came up with were too shocking not to try doing our best.
What follows is an adapted version of our discussion (I used no slides and it was very interactive).
Why?
Because it's the missing puzzle piece
The question of "why" is always at the forefront of my mind (and "so what"). Why are we devoting our time and energy to this complex field? For me, the answer is deeply personal. I believe that AI tools, especially those working with geospatial data, hold the key to addressing some of the most pressing environmental challenges of our time. We're talking climate change, biodiversity loss, sustainable development, and more. Everything happens somewhere, after all. I envision a world where AI-powered tools can empower farmers to make informed decisions, predict and respond to disasters more accurately, and enable us all to better understand our planet.
That's nothing new. We've been chasing that dream, with those same examples, for decades. We've been selling that dream when we got Landsat as open data, when Big Data became a thing, when drones came around, when cloud adopted geo, ... but the dream was always just beyond the horizon. The world we live is not that dream, after decades. I believe that's partly because geo data is just hard... and we experts got too used to the fact that is hard, so we work to make the hard parts easier, but not to make it easy. That's a big difference. Cars are hard, but we made driving them easy. Doing geo still requires advanced skills, and each output requires a dedicated end-to-end process.
That's nothing new. We've been chasing that dream, with those same examples, for decades. We've been selling that dream when we got Landsat as open data, when Big Data became a thing, when drones came around, when cloud adopted geo, ... but the dream was always just beyond the horizon. The world we live is not that dream, after decades. I believe that's partly because geo data is just hard... and we experts got too used to the fact that is hard, so we work to make the hard parts easier, but not to make it easy. That's a big difference. Cars are hard, but we made driving them easy. Doing geo still requires advanced skills, and each output requires a dedicated end-to-end process.
What makes geospatial AI particularly exciting is its unique properties, making it both the missing puzzle piece of the geospatial revolution and a new tool for new things like semantic search or universal embeddings. I'll go into this a bit later, but just think that global geo AI, for example, has no "out-of-domain" problem. We can train on the whole Earth and we will use it only on Earth. I also argue below that AI for Earth models train faster since the data is semantically much more aligned and constrained than with voice or text. Finally (for now) we literally have Petabytes of extremely friendly data: There are vast amounts of open, cloud-ready geospatial data available, free from IP and licensing issues. This abundance of data, combined with the global scope and reduced ethical and legal concerns, makes geospatial AI fundamentally easier.
Because it's a completely new space
AI for Earth is not just a "faster, better, cheaper" song. It's also a whole new universe. We don't fully know yet, but I believe it enables what we didn't even think was possible. By definition, I don't think we really know what it will bring, but one we just recently realized is this: We can complete the map.
Take this image of Buenaventura, Colombia:

This is a satellite image. You can see an urban area, a port, water, and some greenery, possibly natural or agriculture. A transportation expert could see a million more things. So would an agricultural expert. Or defense expert. There is SO MUCH information there, and it take significant expertise to read most of it. Satellite images like this one is that starting point of so many impactful projects, information and decisions. Like a book written in a foreign language, the wealth of that image is encoded in a way that few can read. But there is simply not enough time or people to fully index all images of all earth.
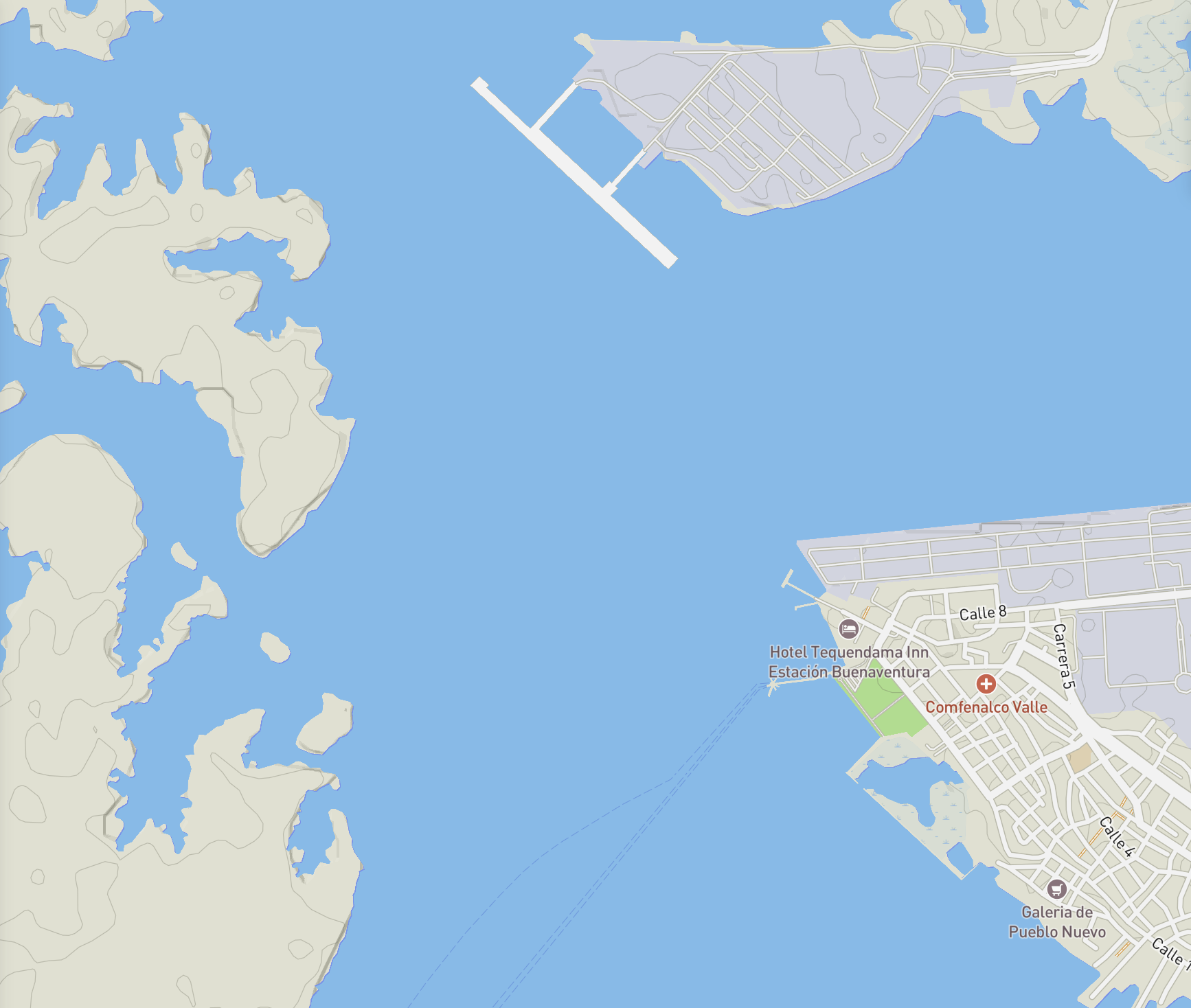
This is the same location, but this time as what most people would imagine as a "map". The one that tries to convey the essentials. That there's a city with streets, and water. There are pins with supermarkets, hotels, and a hospital. The rest is a green and blue blob. We need these simplification so we can read maps better, but to make those maps we had to make choices and assumptions of the final use of that map. On the flip side, anything on that online map is now indexed, searchable. You can type type it on the search box, or click on it, and anyone can get the information that made that thing into the "map". More than a place, this is the interpretation of the map maker of that place so you can use it easily.
The second map was actually made by me using Mapbox, a company I helped start. They provide the means for experts to tweaks a million pre-defined knobs and switched to fully customize the map. Imagine now, a map where with everything any expert on any field could read. Where you can search for "hotel" but also "muddy waters" or "flood prone area" or "container ship docked".
That is what we are building with Clay. We train our model to automatically detect any semantic on satellite images, and then we train another model to name that concept in words. (We feel fairly confident of the performance of the first step -- "Clay model v1" --; and we are working now on the second one -- "Clay text2earth v0"--.)
Maps matter. Did you know that nearly 2 billion people use Google Maps every month? That it directly and significantly grew tourism in Thailand, and many other places? Now imagine a world where anyone has extremely easy access to search anything anywhere on Earth. That world is easier, more friendly, better world. Like a world with and without books or Wikipedia. Where searching for floods is as easy as searching for a hotel. Where monitoring erosion is as easy as setting a news alert. Climate change, biodiversity collapse, agriculture, ... all that becomes one search away. That is a better world. That world is not our world, we don't have a Searchable Earth, yet we already have all the data and tools to make it happen. Today. At global and historical scale. For free. That is just one of the benefits of doing AI for Earth.
When?
The "when" is definitely and simply now.
I firmly believe that we're at a critical juncture in the development of geospatial AI, and with it to shape the path of AI in general, and geospatial in general. That moment was not 3 years ago, since critical tools like Transformers (the T in chatGPT) did not exist at scale. That moment is neither 5 years from now, as I believe that sooner than that someone will dominate and set the norm, collapsing expectations for decades to come. Like Google Maps did around 2006. Their amazing product arrived at the right time and by 2012 was literally the most used app in the world. It became the norm and it also made innovating on online maps much harder, since they were the expectation (At Mapbox we suffered that, as we not only had to be better, we had to be 10x better, to overcome the expectation of "why not Google"). The wins we make today, the values we set, the product we ship in AIfor Earth in the next ~5 years will define the expectations of this field for decades to come.
How
Open Source, Open Data, Open for Business
So, if the "when" is now because it is now that we are setting the expectations, what are these? We're already seeing the dominance of big tech with AI models that seek improvement with ever large sizes and massive budgets. And it works, those are the models most of us use and think of when we speak of AI. It makes for a great business model to make a moat of huge budgets of compute just to get to the start line. It ensures that competitors are few and the race expensive. This leads to a future where a few powerful players control the landscape. By the same token it also attracts massive VC funding, which further provides finance to continue building amazing AI products and services (that will need to hypescale or hyperprofit to return investor expectations).
Open-source AI, one of the main feeding lines of AI, has managed to build and retain a long tail of impressive models. We see open models able to get roughly similar quality as large closed models just a year or so afterwards. More importantly, their incentive is to find improvement by efficiency, not size. This is important for how many resources AI typically needs. It's really a feat to see the tricks open source AI finds to catch up, or sometimes even lead.
This is not an open open vs closed debate. I've worked my entire professional life on "both sides" and I believe in a world where both are true options, building on each other, and ultimately benefiting society at large and progress. I like a world of AI with healthy business products leaning on large closed models; and a long tails of real options of open models, of all sizes and types, decentralized... a fertile ground of innovation with lots of cross pollination in between. This is not a battle of opponents, this is about ecosystem health and resilience: This is the Gutenberg moment for AI, with direct parallels, like facilitating the spreading of innovations across the world, seeding new fields and standards, enabling fast and efficient distribution of progress, ...
But this window of opportunity might close soon. The dividends of improvement with large models will accelerate the divide. These novel products are so differentiated that many people start to associate AI with chatGPT directly, and not know that some open models might be as easy, and better, for some specific use cases. Try using chatGPT without internet connection, or handle voice input by someone who suffers stuttering. Moreover, regulation will come and might rule thinking of what they can see, a backdrop of the few closed model ecosystem (easier to regulate) than the open commons. We already see some of those unintended consequences in the recent California SB-1047 proposal.
AI for Earth is an extremely efficient field to show the path of an ecosystem thriving on both open and closed models:
- We have literally Petabytes of fully open data covering the entire world, and decades of archives (and so we have of commercial data). All of that already cloud ready to be streamed, indexed, sliced and pre-processed as required, with zero license or IP uncertainty. To top it, we also have petabytes of high-resolution and cadence under commercial licenses.
- AI for Earth models are intrinsically more efficient: I believe that global geospatial models will train much faster that large language models. Take this example, there is simply no satellite image, for as many bands and resolution you can think of, that shows "a city transform overnight into a pink fluffy cloud", yet I can write those words without any problem. An AI language model needs to learn to deal with anything anyone can think of, but AI for Earth only needs to deal with the world. And the world is large, but it is also much more limited that our capacity to describe options. Think it this way, it is obvious that travel books use way less words than science fiction ones. Mathematically, Earth pixels on our datasets live on a hyperspace much larger that what it is actually populated. And thus, AI tools with Earth data should learn faster than with text data (or sounds, or random images). Earth is semantically limited.
- Moreover, Earth is semantically stable. Ergodic if you will. Earth is constantly changing, and due to climate change and other factors those changes are unprecedented at that location. But the direction of those changes, and the options, are also very limited. I believe that a model trained just the present data would understand very well both the distant past and the distant future. Yes, Madrid might have been a forest and might become a desert. But today we do have plenty of examples of forest and deserts to recognize them when they show up in Madrid. Not only AI for Earth is semantically limited, it is also semantically ergodic. That again is a huge asset for AI for Earth.
- AI for Earth is not so much about generating data, like it is for text or images. It is mostly about understanding data, indexing data, computing at scale. It's about embeddings, not inference. We thus don't really suffer inference issues like hallucinations, fake data, (or energy resources to constantly run inference). AI for Earth is essentially an omnipotent semantic Earth database. Yes, our indexing might be wrong, but it won't generate the innate rejection of seeing a human hand with 10 fingers, a robot moving erratically or a natural replica of your voice with AI saying weird things.
The wins we make now on AI for Earth will lift not only AI for Earth, they will shape how we see AI, and they will help shine how we built it. We have a chance to create a future where geospatial AI is accessible, diverse, and driven by a wider range of interests than just the fiduciary duty of a for-profit.
What
Yes, we need a model: Clay
This is why, when we thought about doing Clay last year, we decided it had to be a non-profit and it had to have a large budget. If we couldn't raise millions, it would be much harder to play the hand of our value proposition properly. We didn't have the luxury of time to follow the traditional academic proposal, or even public funds. There's just too much (yet reasonable) due diligence, smaller funds and oversight. We needed large funds, quickly and from partners who believe on our "why" and "when". We needed to move quickly to make a real-world impact. We leaned on our networks and found 4 philanthropic individuals and organizations who trusted us and shared our vision. We are incredibly grateful to have them on this path.
Only then we realized we had a chance.
We also, obviously, realized that Clay had to be fully open-source model, and trained only on fully open data, so that anyone – NGOs, governments, journalists – could use it, and integrate it fully and without legal uncertainties on their operations and businesses. Making a multi-million dollar AI model that public asset was crucial for driving the message we wanted. It was beyond doing a model, it is about showing a path less traveled and inviting others to join. It also allows us to make an extremely attractive deal for businesses: Take the model, and go profit doing whatever you want. This is not that crazy, this is essentially what NOAA in the USA does with weather data (remember that NOAA is part of the Department of Commerce).
Also no surprise that for the speed of traction and impact we needed, it made more sense to keep the project very lean and rely heavily on literally the best experts we could find for actually making the AI model itself, who also had to align on the strategy. Our fellowship was whole with Development Seed and Ode, under Radiant Earth as fiscal sponsors. We all shared the responsibility of executing the high ambition for the model, marketing, product, communications and management. This also translated into a weird mindset that building the best AI model of Earth, as incredibly complex and hard as it is, it is just the first chapter, and we knew we had to move as soon as possible into Chapter 2: rolling it out to actually get early wins and scale traction. This was, and remains, my top concern with most unknowns (alongside the right governance). And, to make it even more interesting, I felt we didn't have time to either wait, or getting it wrong the first time.
Clay v1, which we released in May, is the proud culmination of our efforts. This is just v1 and we know this is just a fraction of what we know we can do technically. Yet, Clay is already the only large, open license, open data, global, instrument diagnostic, AI model currently available. It has already been used for a wide range of applications, from estimating biomass, to assessing land cover maps and tracking urbanization.
We have both documentation and a long technical tutorial. We do not have, or have started, a peer review paper. Mostly for lack of bandwidth.
Our architecture is not new or revolutionary, it is more the combination of several papers, and a VERY large training run, what makes the model unique alongside being released completely open.
Briefly, our architecture is 3 main components:
We have both documentation and a long technical tutorial. We do not have, or have started, a peer review paper. Mostly for lack of bandwidth.
Our architecture is not new or revolutionary, it is more the combination of several papers, and a VERY large training run, what makes the model unique alongside being released completely open.
Briefly, our architecture is 3 main components:
- An initial Transformer only gets to see the instrument specs (bands, wavelengths, resolution) and its job is to learn how to split the input images into a consistent set that works across instruments. It basically abstracts out the instrument, so Clay works with any.
- A second ViT (visual transformer) takes both the input images and the split instructions of the first transformer; alongside the resolution and time. It builds a usual masked autoencoder task, where 70% of the image is masked out and the job of the model is to reconstruct it. The comparison of the reconstruction to the input gives 95% of the loss (the objective that guides the learning)
- Serving as a teacher and also helping anchor the model across instruments with universal features, we also take the full image and run it through a trained DINO frozen encoder, we compare our masked embedding to a DINO trained frozen encoder, and the difference is the 5% remaining on the loss.
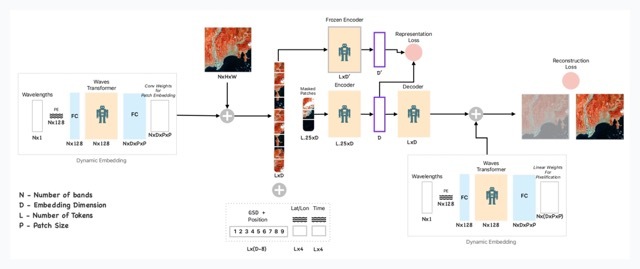
This yields a model that learns Earth on basically 3 ways:
a. A ViT starts with a linear projection of the patch, and it also has access to the resolution, location and time. Hence anchoring the model to the actual content of each patch, and the patches it pays attention to. On language models, the embeddings are randomly initialized.
b. The Transformer model "self-attention" mechanism learns to give features importance in relation to its surroundings. I.e. sand close to water is different than sand for miles around.
c. The reduction of dimensionality of the encoder forces the model to filter what features to retain in order to maximize the reconstruction quality. This is further helped by the heavy masking.
d. Batching several input images smooths the backpropagation updates, which make for easier stochastic descent on the loss surface. This helps cluster semantically similar concepts, arranging the embeddings space into semantic clusters. In my head I imagine how at a distance all forest patches "travel down" the loss surface together, and the closer you look the more organized they are so they can move over previous "grooves".
At the "neck" of the model we have embeddings, which in my opinion hold the linchpin of geoAI. One could even argue that embeddings is "the end of pixels" as the main actor in geospatial. A slogan could be that they contain 99% of the semantics with 1% of the size.
There are many many open questions about the architecture and training goals. For example, we know that we can create embeddings across instruments, but we have not forced, or even confirmed, that semantics across instruments are aligned. I.e. the sector of the embeddings space with "rivers" in Sentinel data, might also locate rivers in NAIP data. Or not. I'm keen to for example tweak the learning process to be explicitly geo anchored and with all inputs optional. That is, we drop some of the input variables (location, time, pixels, ...) and the model still needs to recreate the full input. If we further mix across inputs, we will force the model to pay close attention to location and time (i.e. we input Sentinel-2 but ask to reconstruct Sentinel-1, or NAIP). My goal is one model that memorized Earth semantics, just like chatGPT memorized quantum, french history and swahili. But this is v1. We do see the clear road ahead, and we've made enough progress to realize that our theory of change is not just the model, but the things around it.
Beyond the model, the world
The model itself is important, but the product and stories around it are what makes it work. This is why we've also built no-code web apps that allow users to easily interact with Clay and extract valuable insights from geospatial data.
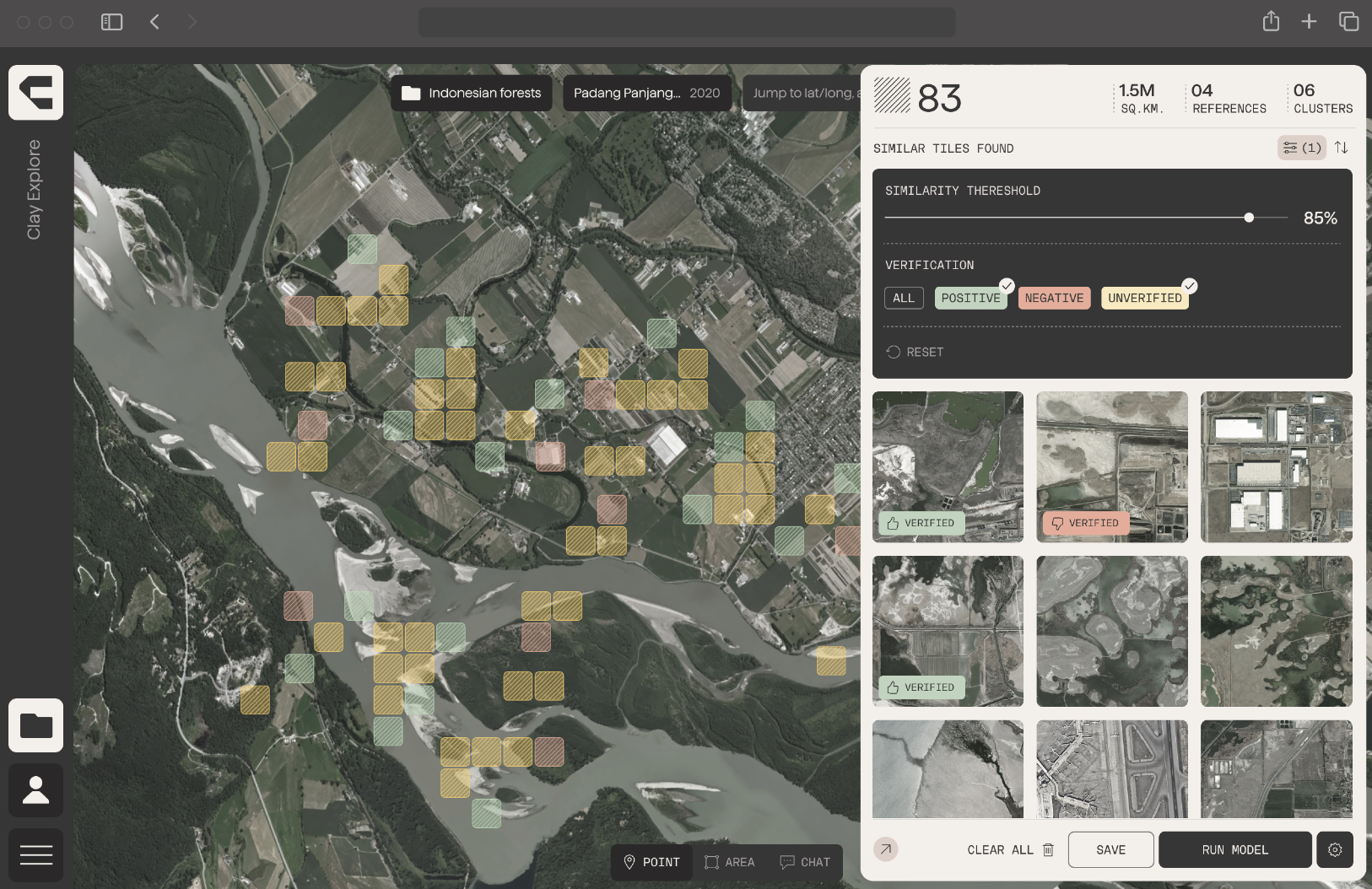
Our work now is two-fold: a) Work closely with partners to address real-world problems, inspiring others to join the movement, while b) build an app that we can open to the world, that allows anyone to use Clay with the least amount of need to understand AI or geospatial, just doing the user intent in the least amount of clicks and choices.
[On my class, we ran out of time roughly around here, and I've already complemented a lot]
-----
We envision a future where geospatial AI is seamlessly integrated into everyday tools like Google Maps, providing real-time insights into environmental changes and empowering people to make informed decisions.
This will in turn demonstrate how AI can be built in a way that creates both for-profit and public digital goods with a longtail of options that both helps maximize the value to most people, and seed innovation.
To achieve this vision, we need to move now, and demonstrate that AI is not just the model, but how we build them, and what products we create with them, for whom, to be used how. We need to encourage collaboration, simplicity of operation, dependability through quality and flexibility, space for profitable products and public good, share knowledge and resources, and work together to overcome the technical and social challenges that lie ahead.
I'm excited about the future of geospatial AI, and AI; and I'm convinced that together, we can unlock its full potential to create a more sustainable and equitable world. And that that path has an important milestone in the minds and work of the people on that room in Copenhagen and those reading this far on this article.