Infinite Sentiment: Client-Side Sentiment Analysis of Novels Using Transformers.js
My last two blog posts were called The Joy of JSFiddle and My React-Natural-Typing-Effect NPM Module and this blog post continues my focus on the client-side. However, I kick things up a notch by utilizing Hugging Face's Transformers.js which is a library that enables a vision of the future that I love: machine learning and AI that runs entirely in the client's browser. To me, this is a beautiful thing that can obviate the overhead of running cloud ML services (let the clients use their RAM and CPU cycles! But give them option to opt-in) and enable greater privacy of users. Sure, most companies would rather hoover up user data and behavioral data, which can turn a nice profit even after the additional overhead of an ML backend. But I'm not a company and I think privacy is important. Plus, it's just really cool to be running ML and AI locally.
This project of mine, Infinite Sentiment, started as an excuse for me to play with Transformers.js by grabbing random passages from the novel Infinite Jest and passing them through a sentiment analysis model in the Transformers library: https://github.com/cipherphage/Infinite-Sentiment. On a separate git branch, sentiment-viewer, it has grown into a React/Next.js app that performs sentiment analysis on passages from text files and presents users with a sortable, heatmap-like visual which can uncover patterns in the data. What exactly the patterns mean is not clear to me, because there are multiple layers of open questions that I have. But it's been a ton of fun for me and I'm excited to extend my app to make it easier to use and more versatile in the analysis of literature.
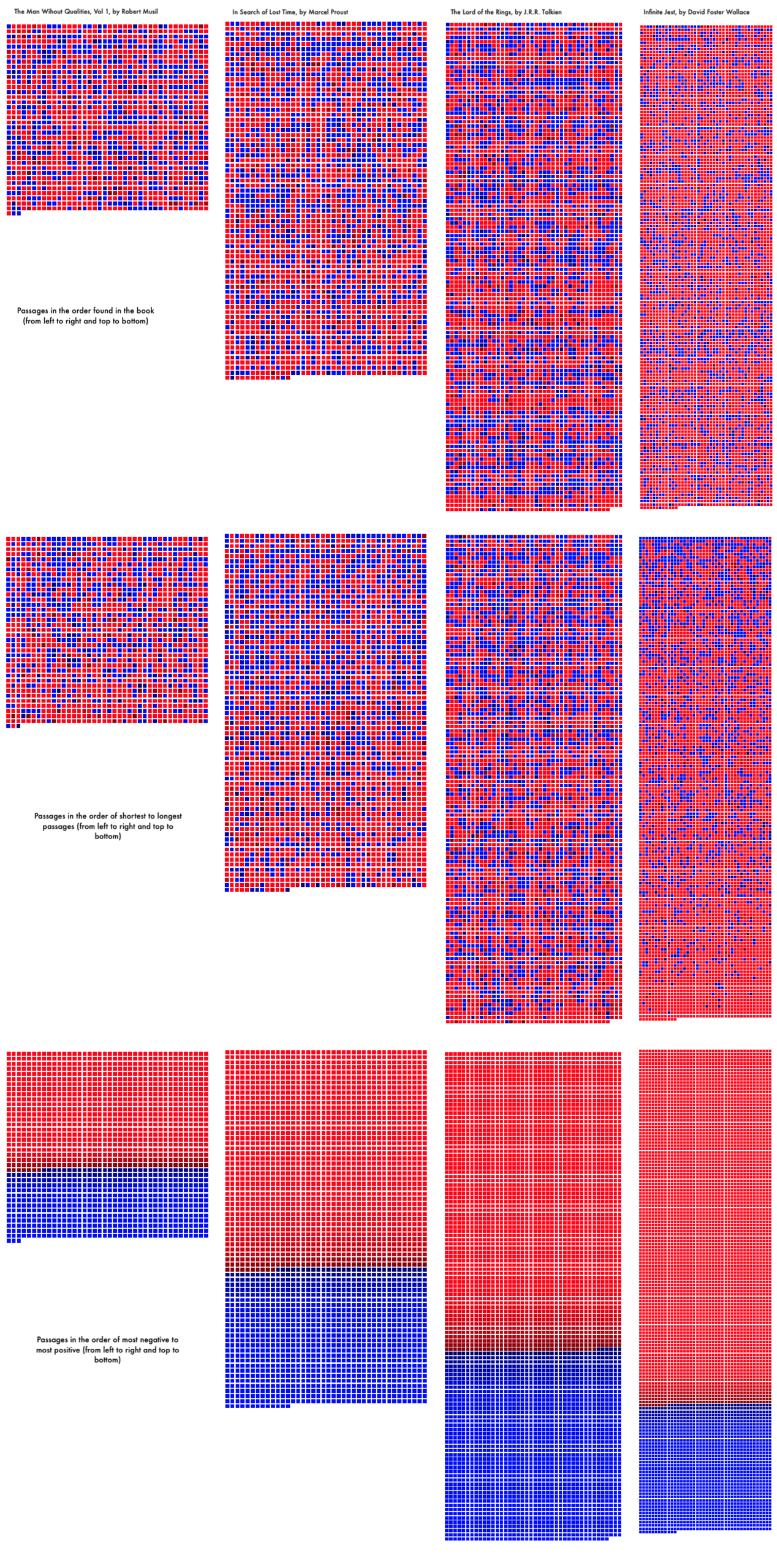
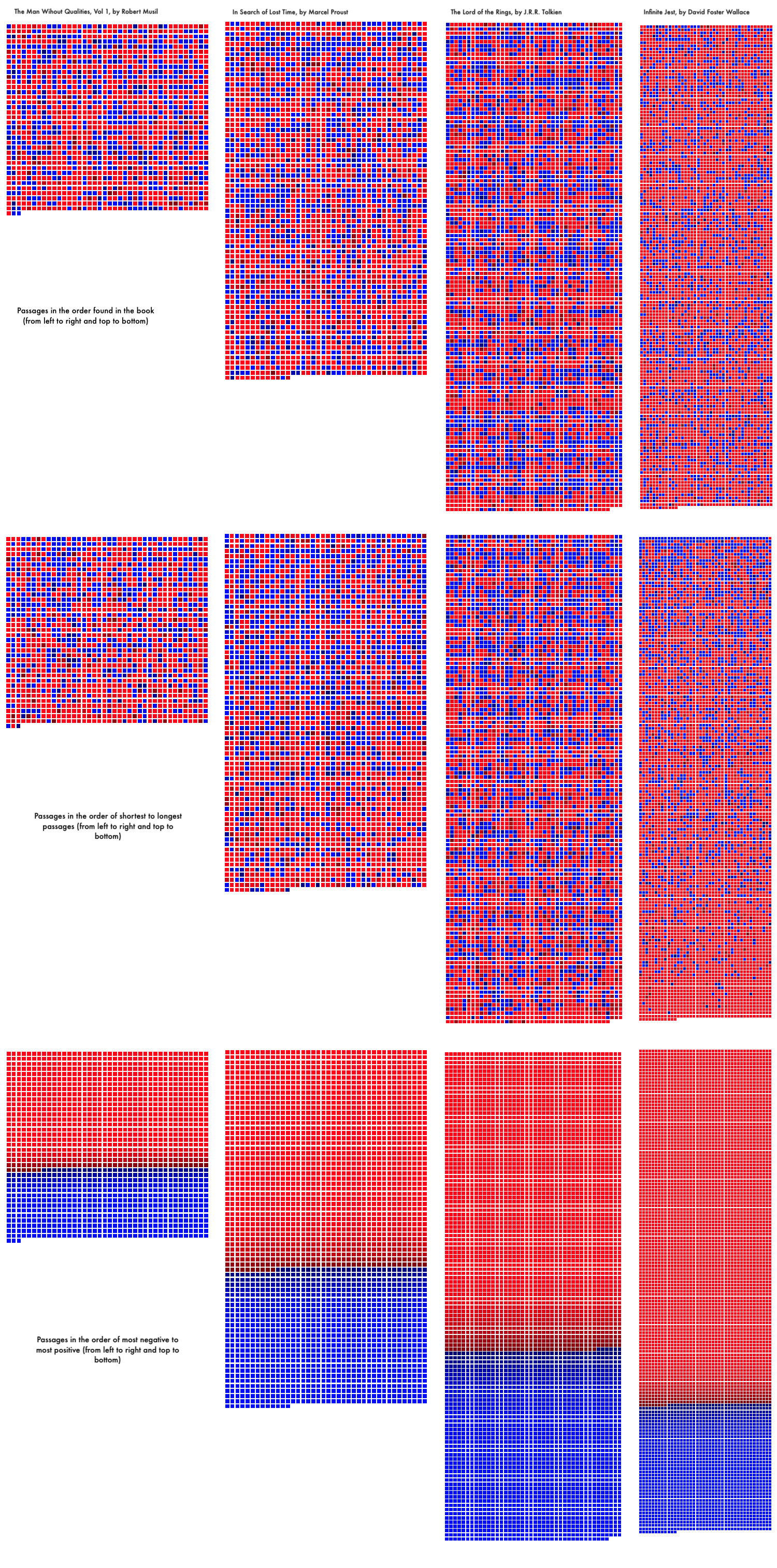
Here's a comparison of passages from four 20th century novels. I'll discuss the questions raised by these comparisons below, after a very brief technical discussion of the app.
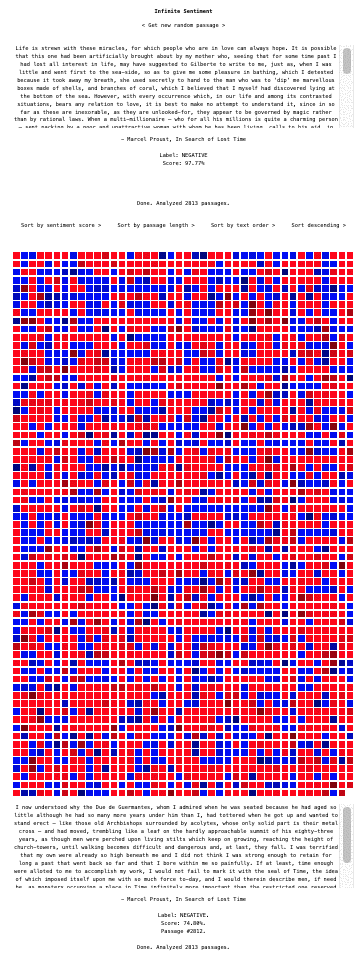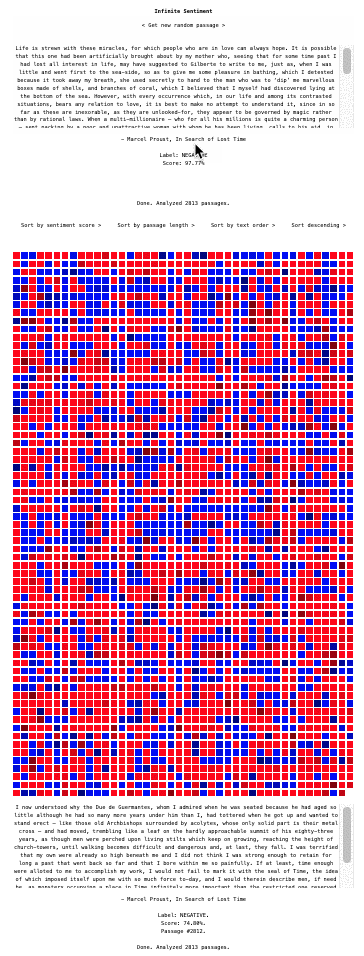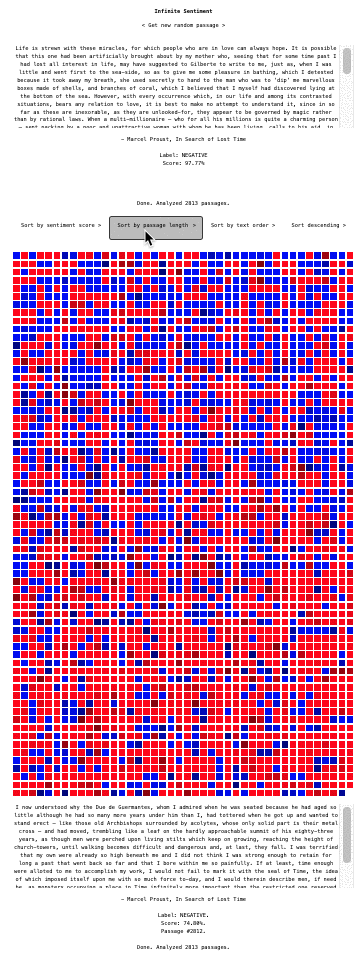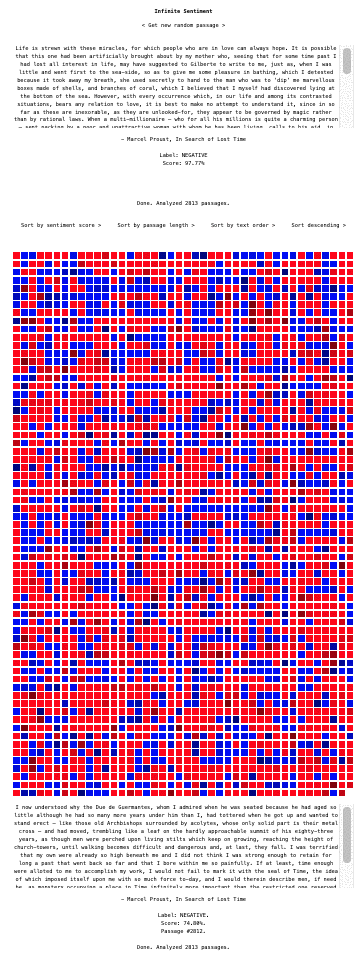
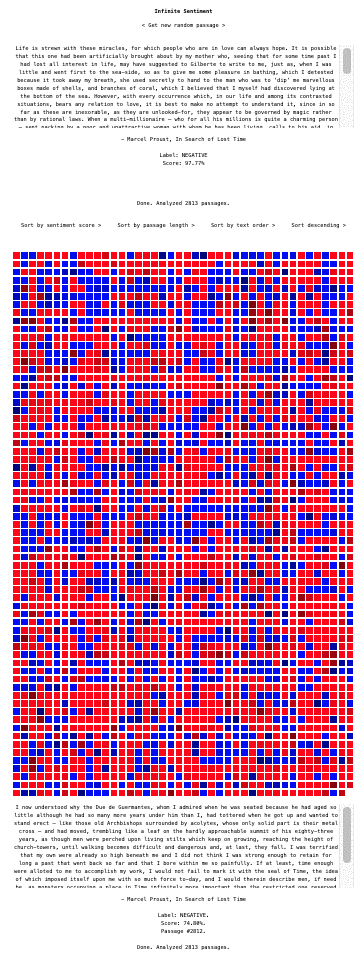
Technically, the web app I made to create these heatmaps is very straightforward. Here's a gif of the UI which I made with simplicity in mind to make it fun to play with for anyone to explore text-based data and in particular long texts such as novels.
At the top of the UI we have the app's name, Infinite Sentiment, and directly below that we have a React component that simply accepts a passage and displays the text (the Get random passage button grabs a random element from the passage string array). Below that is a simple sentiment analysis component which displays the loading message for the analysis, accepts and sends the text to the web worker (using the web API's postMessage) that runs the client-side sentiment analysis pipeline (from the Transformers.js library), and waits for the output. When the output arrives (again via postMessage) the loading message is replaced by the output.
Underneath that in the UI you see the really fun component, SentimentViewer, which I'm working on in the sentiment-viewer git branch right now (a work in progress for sure!). This is the component that receives the full passage string array and then proceeds to send one passage at a time to the web worker for analysis, receives the output and displays the color of the output sentiment score as a colored square in a grid. The color forms a gradient with the other squares in so far as the square's color is a red (negative sentiment) or a blue (positive sentiment) with an rgb value linearly tied to the sentiment score. Below the grid, the latest passage and output is displayed. Soon I will hook up the square's onClick to display the clicked on passage or perhaps do a popup on hover, but for now clicking on a square console log's that square's text and sentiment output.
On top of the grid of squares are four more-or-less obviously labeled buttons: Sort by score, Sort by passage length, Sort by text order (i.e., the order the passage appears in the original text), and Sort descending (which is a toggle that changes to Sort ascending).
With just the first three buttons it is possible to some interesting pattern finding. In the chart at the beginning of this post you can see an example of some comparisons. For example, the default view is to show the passages in order as they appear in the text. As you can see in the chart the distribution of negative passages versus positive passages varies by author with some authors appearing to have clusters or groupings of sentiment (as with Lord of the Rings and Infinite Jest) while the other two (The Man Without Qualities and In Search of Lost Time) appear to have more randonly distributed sentiments between passages.
The second row of the chart shows a sorting of passsages by passage length from shortest to longest. In this case we can see that longer passages, which are at the bottom ends of each collection, appear to be more negative across all of the authors, although perhaps Infinite Jest has this pattern most clearly where as Lord of the Rings is slightly more even.
Finally, in the bottom row of the chart we see that sorting by score can give an impression of the overall sentiment of the novel and here Infinite Jest appears to be the most negative of the four novels.
All that said, I feel I have come up with more questions than answers. For example:
Is Infinite Jest actually more negative in it's longer passages? Or is the sentiment analysis model that I used biased on longer passages (or just not useful for long passages)? I used this model: Xenova/distilbert-base-uncased-finetuned-sst-2-english.
Currently, I am parsing the text into passages in a very simplistic manner, relying on a straightforward regular expression. The texts themselves are littered with inappropriate linebreaks so the resulting passages are unlikely to consistent in multiple ways: length, start and stop of sentences (sometimes mid-sentence), and other inconsistencies. For example, right now Infinite Jest, a roughly 1200 page novel, is separated into over 6000 passages. In Search of Lost Time, at seven volumes and over 3000 pages, is separated into less than 3000 passages. While Proust certainly does write longer paragraphs and sentences than other writers I've read, I'm not sure that on average the length of his passages would be greater than an entire page, so there could be a significant parsing inconsistency here. What are some more versatile and more consistent ways to parse these texts? Are there some other ML models that can help to parse and classify the texts' strings before they are used in further analysis?
What would happen if I analyzed the text line-by-line, sentence-by-sentence, by paragraph (which is roughly what I try to do right now), by quotations, by character dialog, by page, by chapter, by section or by volume? Again, perhaps different ML sentiment analysis models might be more or less suited to different lengths of texts or different kinds of text (e.g., dialog versus narration).
How do different text files compare, different translations or editions of a novel, visual arrangements of the text, endnotes, footnotes, pictures, forwards and introductions, etc?
What are the differences between ML models for sentiment analysis and what exactly are they measuring?
Are there other useful or interesting ML models that could be applied on literature for the purposes of analyzing and comparing?
As you can see there are a lot of interesting questions and perspectives that can be brought to bear on the analysis of the texts and my app is currently a rudimentary toy compared to real analytical tools. There remains a lot of fruitful and more importantly fun work that I want to do to extend this app into a more general literature analysis tool. It's an interesting and curious hobby project for me because it brings together three of my interests: great literature (a long time interest of mine), machine learning (a recent interest), and data dashboards (a professional interest I've held for many years). Which aspects of data and analysis will I focus on? Are there opportunities for creating React component library NPM modules for Transformers.js data visualizations or does it make more sense to focus on an all-in-one web app? I'm excited to see where this leads in my spare time!