A month later, we placed an order for $600,000 worth of Dell servers to carry our exit, and did the math to conservatively estimate $7 million in savings over the next five years. We also detailed the larger values, beyond just cost, that was driving our cloud exit. Things like independence and loyalty to the original ethos of the internet.
Still in February, we announced the new tool I had bootstrapped in a few weeks to take us out of the cloud – without giving up on all the innovation in containers and operating principles from the cloud. This was the introduction of Kamal.
Shortly thereafter, all the hardware we needed for our cloud exit arrived on pallets in our two geographically-dispersed data centers. All 4,000 vCPUs, 7,680GB of RAM, and 384TB of NVMe storage of it!
To say this journey was controversial is putting it mildly. Millions of people read the updates on LinkedIn, X, and by following this very mailing list. I got thousands of comments asking for clarification, providing feedback, and expressing incredulity over our nerve to zig when others were still busy catching up to the zag.
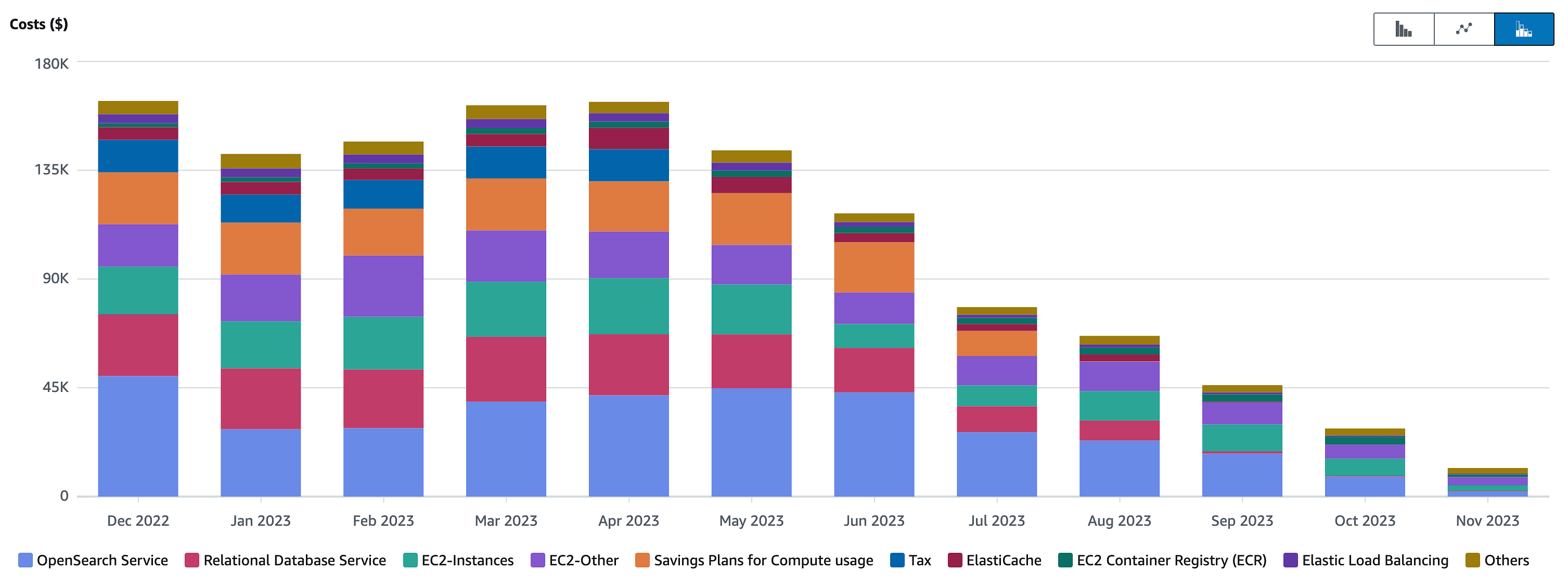
But the proof was in the pudding. Not only did we complete our cloud exit quickly, customers scarcely noticed anything, and soon the savings started to mount. Already in September, we’d secured a million dollars in savings on the cloud bill. And as the reserved instances (where you prepay for a whole year in advance to get better pricing) started to expire, the bill just kept collapsing:
Which brings us till today. The cloud exit is done, but the questions keep coming. Oh do they keep coming. So rather than answer the same points over and over (and OVER!), I thought I’d compile a good old fashioned list of Frequently Asked Questions (FAQ). Here goes:
Won’t your hardware savings be swallowed by bigger team payroll? No, because we didn’t change the team composition after our cloud exit. The same people who were operating HEY and Basecamp and the other apps in the cloud are now operating them on our own hardware.
This is the central deceit of the cloud marketing, that it’s all going to be so much easier that you hardly need anyone to operate it. I’ve never seen it. Not at 37signals, not from anyone else running large internet applications. The cloud has some advantages, but it’s typically not in a reduced operations headcount.
Why didn’t you just optimize your cloud bill instead? Our cloud bill used to be twice as large as the highly optimized, monthly scrutinized, heavily haggled bill we detailed in the $3.2 million for 2022. We had squeezed just about every drop from that lemon, and it was a ton of recurring work to do.
That’s part of why I’m so bullish on the concept of cloud exits for mid-sized and above software companies. It’s extremely easy to spend 2-3-4x the amount we were blowing every month on a business with the same number of customers as we have. Which means even higher potential for savings for most.
But what if you had written a Cloud Native application instead? Cloud Native, as in opposition to “lift’n’shift”, is often touted as The Real Way to take advantage of the cloud, but that’s again just more cloud marketing nonsense. It generally centers around the erroneous belief that serverless functions, and associated on-demand tooling, is going to make things cheaper. But if you need a pound of sugar, you’re not going to save any money buying single-wrapped cubes. I wrote about that in more detail in Don’t be fooled by serverless and Even Amazon can’t make sense of serverless of microservices.
What about security? Aren’t you worried about getting hacked? The majority of security problems you face by operating software on the internet comes from the application and its direct dependencies. The work that needs to happen to properly secure your custom-built application is not any materially different whether you own the computers it runs on or rent them from a cloud provider.
If anything, operating services in the cloud can give people a false sense of security. Thinking that it’s not something they have to worry about, when it absolutely is.
The big advantage of modern containerized application delivery, though, is that you’re no longer spending much time patching machines manually. Most of it is packaged up in the Dockerfiles, and deploying a new version of the application that runs on a more recent update of Ubuntu or whatever is the same whether you’re renting machines in the cloud or running your own.
Don’t you need a world-class team of super engineers to do this? I never shy away from an opportunity to brag about the great people we have working at 37signals, because I’m legitimately proud of the team we’ve assembled here. But it would be beyond hubris to claim that they have some special magical insights that are allowing them to operate our own hardware, which just isn’t otherwise available.
The internet got going in 1995. Cloud as the default choice didn’t happen until maybe 2015. So for well over twenty years, companies have been operating hardware to run their applications. This isn’t some archaic knowledge that’s been lost to the ages. We might not know exactly how the pyramids were built, but we do still know how to connect a Linux machine to the internet.
Besides, 90% of the expertise needed to run your own hardware is the same as what’s needed to run in the cloud. At least once you get to our scale with millions of users and hundreds of thousands of dollars in monthly bills.
Does this mean you’re building your own data centers? Nobody is building their own data centers, outside the hyperscalers and a handful of other mega companies like Google, Microsoft, and Meta. Almost everyone else simply rents a couple or cabinets or a room or a floor at a professional data center operator, like Equinix.
So owning your own hardware does not mean having to worry about security, or power delivery, or fire-suppression systems, or any of the other details that go into these facilities that can cost hundreds of millions of dollars to create.
But what about racking and stacking servers and pulling network cables? Who does that? We use a white-glove data center service provider called Deft. There are tons of other companies like them. And you pay them to unpack the boxes that arrive from Dell, or whoever you buy from, straight to the data center, then they stack it, rack it, and you see the IP address come online. Just like the cloud, even if it isn’t instant.
Our operations team basically never set foot in our data centers. They’re working remotely from all over the world. The operating experience is far more like that of the cloud than it is the early days of the internet when everyone drew their own cabling.
What about reliability? Doesn’t the cloud do that for you? When we were running in the cloud, we were using two geographically-dispersed regions, and plenty of redundancy within each region. That’s exactly what we’re doing now that we’re out of the cloud. We host our own hardware in two geographically-dispersed data centers, each data center is capable of carrying the full load we need, and every critical piece of infrastructure has replicas.
Reliability is largely a function of redundancy. You should be able to lose any computer, any component, at any time, without that being a problem. We had that in the cloud, we have that with our own hardware.
How about international performance? Isn’t cloud faster? Our previous cloud setup used two different regions within the US, and then it used a CDN network with local edge nodes all over the world. That’s the same story, again, like reliability, with our cloud exit. We use two data centers in the US, and we use an international CDN to speed up content delivery.
It’s fundamentally the same equation. The hard part about international footprints is usually not securing a data center or setting up hardware, but designing your application to deal with multiple primary databases for writing, dealing with replication lag, and all the other fun stuff it takes to make applications fast on a global internet.
We’re currently planning an outpost experiment for HEY with a data center in Europe, and we’re just leaning on our friends at Deft to set that up. As with all hardware procurement, it does take longer to get that delivered than cloud. Nothing beats the cloud for “I want 10 servers online in Japan” and seeing it happen 30 seconds later. It’s amazing.
But for our kind of business, the insane premium you have to pay for that kind of instant bootstrapping just isn’t worth it. Waiting a couple of weeks to see servers come online is a completely tolerable trade-off.
Did you factor in what it costs to replace your servers later? Yes, we did our math on the basis of servers lasting five years. That’s conservative. We’ve had servers go 7-8 years, working great. But five years is usually the interval used by most people, and it makes for easy financial comparisons.
But here’s the kicker. We spent $600,000 buying a ton of new servers. We’ve already paid that investment off with the savings secured by leaving the cloud! So if some amazing technological breakthrough happens next year, and we want to buy a bunch of new stuff again, we can easily do that and still be ahead on the math.
What about privacy regulations and GDPR? Clouds don’t offer you any real advantages when it comes to privacy regulations and GDPR. If anything, it’s a negative aspect, because all the major hyperscalers are American. So if you’re in Europe, and you’re buying cloud services from Microsoft or Amazon or Google, you’re still liable to the fact that the US government can legally compel these providers to hand over data and records.
So, if anything, you’re better off owning your own hardware and running it from a European data center provider, if strict compliance with GDPR is key to your setup as a European company.
What about bursts in demand? What about autoscaling? The shocking thing about buying your own hardware is realizing both how cheap and how powerful it’s become. The progress in the last 4-5 years alone has been immense. This is one of the reasons that much of the cloud is getting to be a worse deal by the year. Moore’s Law is hammering the prices and increasing the capabilities of stuff you buy from Dell and others. But it’s scarcely moving the needle on the price you have to pay Amazon and others for their managed services.
That’s all to say that you can afford to dramatically over provision your own hardware to give you ample headroom to deal with spikes, and it’ll barely make a difference in the long-run budget.
That said, if you regularly do face 5-10x or higher spikes in demand over baseline, you may indeed be a good candidate for cloud. This was after all the original incentive behind AWS. That Amazon needed way, way, WAY more performance on Black Friday or Cyber Monday than they did the rest of the year. So flexible hardware made sense.
But you can also mix and match. The saying goes “buy the baseline, rent the spike”. Many companies won’t even need to bother with that, though. Just buy some powerful machines a fair step ahead of your growth curve, keep an eye on usage over time, and if you have to make an unplanned expansion, you can usually have a whole other fleet of servers online in a week or so.
How much are you spending on service contracts and licensing fees? Nothing. Everything you need to run applications on the internet is generally available as open source. We run open source versions of everything we were running in the cloud. Our RDS databases became MySQL 8. Our OpenSearch became open source ElasticSearch.
Some companies may indeed like the comfort of a service contract, and there are plenty of providers out there who can offer one. We’ve on/off used the great services of Percona for their MySQL specialists. It doesn’t fundamentally change the underlying equation.
Although you do have to stay clear of the most enterprisey outfits. Typically if they have banks or governments on their client list, you ought to look elsewhere, unless you just like setting money on fire.
If cloud is so expensive, why did you ever go there? Because we bought the marketing pitch. That it was going to be cheaper, easier, and faster. Only the last promise ever really came through for us. The cloud makes it really fast to provision a whole fleet of servers. But that’s just not something we do very often, so it’s not worth a huge premium.
But we spent years trying to unlock the savings from “economies of scale” and “ease of use”, but it just never really happened. The managed services still needed management. The advances from Moore’s Law rarely got passed on as savings.
In hindsight, I’m actually glad we did give the cloud a proper go. We learned a lot, and we improved our processes as a result. But I do wish we’d done the math a couple of years sooner.
I have another question you didn’t answer!
Please email me dhh@hey.com. I’ll add answers that are generally interesting to this page.