how much content is there in the publisher ecosystem
An increasing number publishers are licensing content for AI training. What’s the potential size of the market?
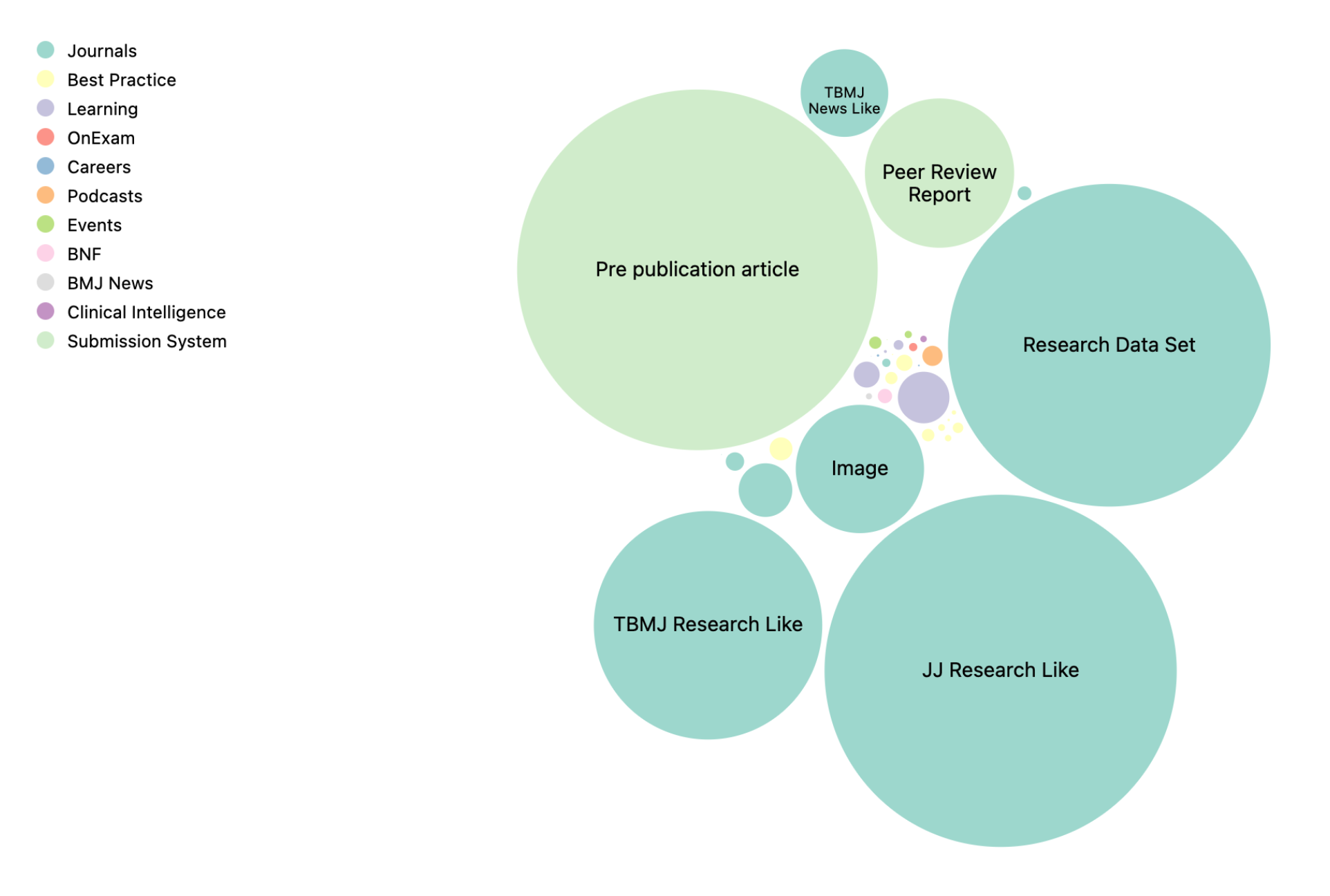
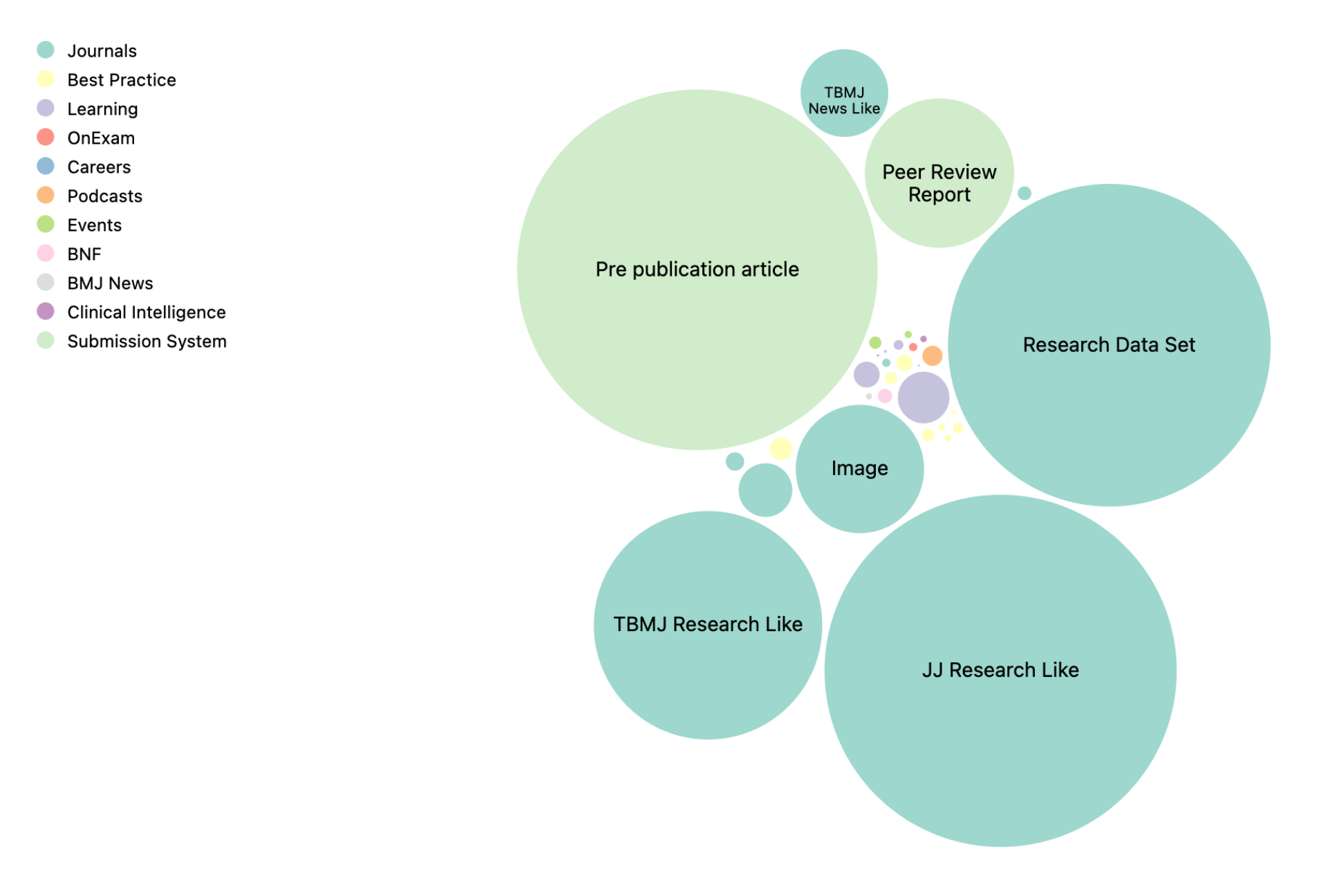
CrossRef gives us the data below for the top 80 lenders by CrossRef counts. Now not all of these are going to be papers, but we are just looking for an order of magnitude guess. The total sum of records across these publishers is 123 million items. If we make some assumptions about average paper size and average words per paper, and average tokens per word we get to something like 1 to 1.5 trillion tokens.
State of the art models are probably trained on 10+ trillion tokens.
Based on public data GPT estimates that the current market pays about a tenth of a cent per training token so the nominal value across the top 80 publishers might be in the region of one to two billion dollars worth of training data.
Now this does not include book content or other content. Skip down to the end of the post for some more reflections on this.
Group | Count Elsevier | 23945552 Springer Nature | 17121586 Wiley | 11615319 Taylor & Francis | 7661076 Oxford University Press | 7099352 IEEE | 6330425 Public Library of Science (PLoS) | 4656878 De Gruyter | 3592941 Wolters Kluwer | 3144482 SAGE Publications | 3113846 American Chemical Society (ACS) | 2783353 Cambridge University Press | 2518549 MDPI AG | 1839573 JSTOR | 1493296 Frontiers Media SA | 1273571 IOP Publishing | 1234626 Royal Society of Chemistry (RSC) | 957268 BMJ | 944924 Georg Thieme Verlag KG | 893190 AIP Publishing | 814133 American Physical Society (APS) | 792287 American Psychological Association (APA) | 728599 SPIE | 622941 Emerald | 588373 American Medical Association (AMA) | 587653 University of Chicago Press | 552537 American Association for Cancer Research (AACR) | 536330 ENCODE Data Coordination Center | 530782 Project MUSE | 524088 Copernicus GmbH | 507121 ACM | 484588 FapUNIFESP (SciELO) | 483388 BRILL | 451064 S. Karger AG | 448434 American Association for the Advancement of Science (AAAS) | 440679 CAIRN | 435492 EDP Sciences | 423965 Cold Spring Harbor Laboratory | 412409 University of California Press | 405755 Trans Tech Publications, Ltd. | 397569 PERSEE Program | 381133 PeerJ | 370053 OpenEdition | 362025 Pleiades Publishing Ltd | 360934 International Union of Crystallography (IUCr) | 345418 Duke University Press | 337732 Japan Society of Mechanical Engineers | 334322 Optica Publishing Group | 331591 Office of Scientific and Technical Information (OSTI) | 329531 Egypts Presidential Specialized Council for Education and Scientific Research | 317833 Princeton University Press | 307187 American Society for Microbiology | 300354 Worldwide Protein Data Bank | 281318 American Geophysical Union (AGU) | 275786 IGI Global | 256509 transcript Verlag | 255440 eLife Sciences Publications, Ltd | 242413 H1 Connect | 238869 IUCN | 237647 Institution of Engineering and Technology (IET) | 237280 Unmaintained records | 237248 WORLD SCIENTIFIC | 220300 American Library Association | 219038 Mary Ann Liebert Inc | 215932 American Institute of Aeronautics and Astronautics | 212477 Center for Open Science | 206990 The Conversation | 205172 Canadian Science Publishing | 204478 Pensoft Publishers | 201955 The Electrochemical Society | 198316 American Society of Hematology | 193810 Massachusetts Medical Society | 191183 Edward Elgar Publishing | 190934 American Physiological Society | 189804 Inderscience Publishers | 186568 American Astronomical Society | 185775 Mark Allen Group | 182930 American Society of Clinical Oncology (ASCO) | 180213 SAE International | 174882
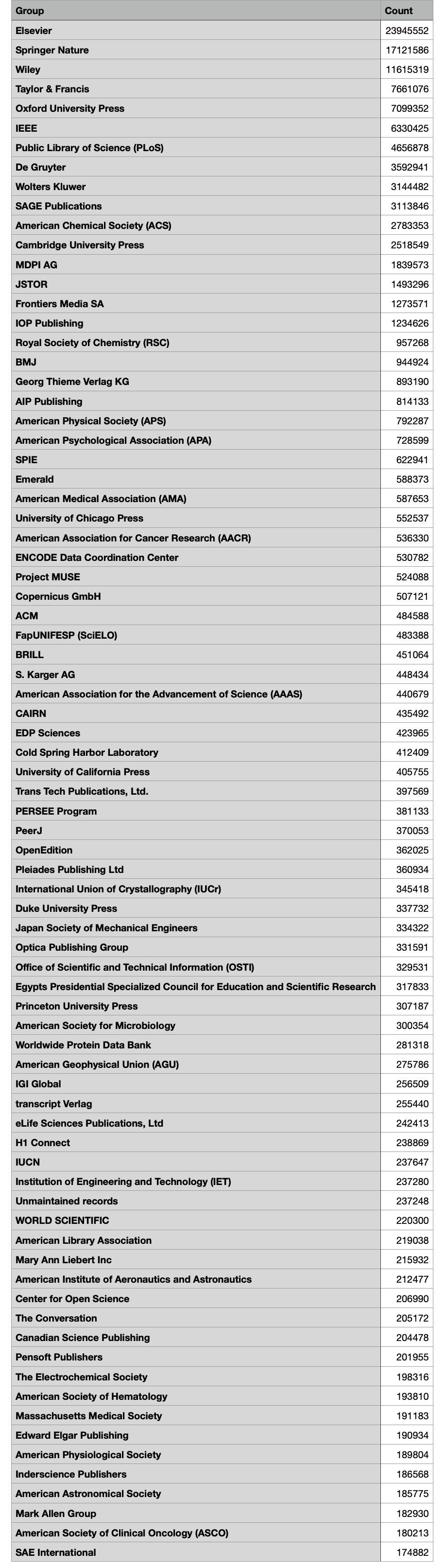
Picking up from above. At the moment it seems that most of the market is in training on raw words but published have lots of other contest too. I tried to reason about how much content of different kinds we might have at BMJ and without spending too much time in our content systems (I was just doing a quick back of the envelope) we might imagine that we sit on lots of audio, video, image, raw research data, and metadata like submitted article versions.
If the market shifts to being interested in these kinds of artefacts and companies doing training runs continue be deluged with cash waterfalls then the market could double or triple in size.
There are a lot of debates about the ethics of these kinds of deals. I had a very good but all too short conversation with Amy Brand from MIT on the topic.
There are a few things I am willing to say on this.
- the large amounts of cash involved, and associated high profit margins, are creating new incentives and that always has different consequences than one initially expects. - the stance of our community / industry will not change the behaviour of the major actors. - our content is relatively unbiased compared to the open web. - LLMs are going to be used by a lot of people, irrespective of whether they have high quality content to train on, or not.
About Ian Mulvany
Hi, I'm Ian - I work on academic publishing systems. You can find out more about me at mulvany.net. I'm always interested in engaging with folk on these topics, if you have made your way here don't hesitate to reach out if there is anything you want to share, discuss, or ask for help with!