Every production system has at least one “god table”.
It’s usually the biggest, busiest table in the database — the one that knows about everything: orders, users, products, payments, delivery, invoices, discounts, status, audit trails… and inevitably, a lot more.
It becomes a magnet for behaviour. And that’s where things get dangerous.
It becomes a magnet for behaviour. And that’s where things get dangerous.
AI accelerates this problem in a predictable way.
Why LLMs grow the god table by default
When you ask an LLM to implement a change, it will usually optimise for the smallest local diff.
Why LLMs grow the god table by default
When you ask an LLM to implement a change, it will usually optimise for the smallest local diff.
Example:
“We need to record when an order is fulfilled, and by who.”
“We need to record when an order is fulfilled, and by who.”
The simplest change is obvious:
- add fulfilled_at
- add fulfilled_by
- to the orders table.
It’s not wrong. It’s just the path of least resistance.
But that’s exactly how the god table grows: one reasonable request at a time.
The hidden cost isn’t the columns. It’s the side effects.
The god table is already full of behaviour
In any mature codebase, the central model (Order, User, Account, etc.) tends to carry a lot of logic:
- callbacks / hooks
- state transitions
- auditing
- background jobs triggered on update
- “if this changed, do X” rules scattered across the system
- integrations hanging off updates (emails, invoices, accounting, CRM, analytics)
So when you add a new concern into the god table, you’re not just storing data.
You’re creating more reasons for the record to change.
And that creates systemic cost.
Write amplification and data pipeline noise
Most scale-ups end up streaming their core tables into a warehouse (Databricks, Snowflake, BigQuery, etc.) for reporting. That means every update to your god table can trigger downstream work: CDC events, ingestion jobs, transforms, dashboard refreshes, alerts, and external reports.
If the orders table is noisy, you’re effectively paying a tax on every small metadata change — not just inside your app, but across your analytics stack too.
If your god table is noisy, every update creates churn:
- more rows emitted downstream
- more refresh/sync work
- more dashboards recalculated
- more chances of “why did this job run?” incidents
- more external side effects triggered just because a record changed
The bigger and hotter the table, the more expensive and risky that churn becomes.
So if fulfilment metadata lives on the order row, you end up touching the biggest record in your system even when you don’t need to.
The better design: extract the fulfilment concern, It’s classic OO design: Single Responsibility Principle + decoupling.
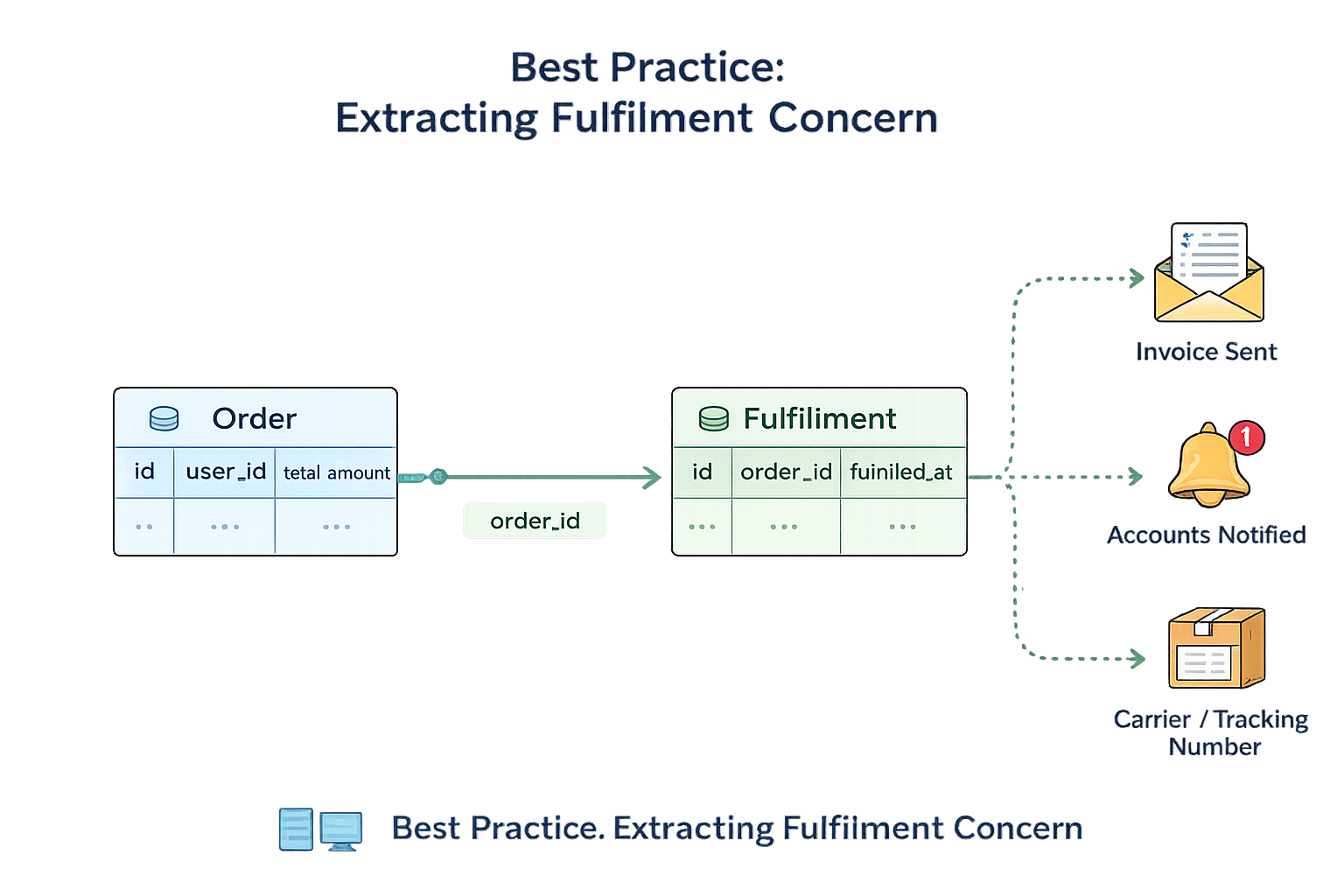
Instead of adding more fields to the god table, add a new concept.
Create a dedicated fulfilment model/table that belongs to an order.
For example:
- fulfilments (or order_fulfilments)
- order_id
- fulfilled_at
- fulfilled_by
- and any fulfilment-related fields you’ll inevitably want next:
- invoice_sent_at
- accounts_notified_at
- tracking references, timestamps, notes, etc.
Now fulfilment becomes its own bounded area for data and behaviour.
The benefits are immediate
Cleaner boundaries
Order stops absorbing every new concern. Fulfilment logic lives in one place.
Less noise
Updating fulfilment doesn’t have to touch the core order record unless you deliberately choose to.
Reduced write amplification
Your downstream pipelines don’t churn because fulfilment metadata changed.
Easier evolution
Fulfilment can grow without bloating your core model.
Operational safety (the underrated benefit)
This matters a lot in real systems: troubleshooting.
When fulfilment state lives inside the Order model, it’s difficult to inspect, edit, or replay fulfilment behaviour without dragging the entire “order machinery” along with it.
In many systems, “order updated” can trigger revenue-critical side effects: payment flows, invoicing, accounting sync, customer notifications, CRM updates, and more.
When you’re in the console fixing a one-off edge case, the last thing you want is to accidentally trigger something serious (imagine re-charging a customer because you touched the wrong attribute).
When fulfilment is its own model/table, it’s safer:
you can inspect and change fulfilment state, rerun fulfilment-specific logic, or repair a record without touching the core order row or firing unrelated order callbacks.
That separation isn’t just architecture. It’s an operational safety feature.
How to get AI to do the right thing (and why it still misses)
This is also where AI needs guidance.
Left to itself, it’ll take the shortest route: “add columns to orders”.
I even have a rule in my AGENTS.md along the lines of:
“Avoid growing the god object/table. If the change introduces a new concern (fulfilment, payments, notifications), propose extracting a dedicated model/table.”
And yet it still doesn’t always follow it.
Why? Because the right answer is… it depends.
Sometimes adding a column is genuinely fine. Sometimes extracting is overkill. The model can’t always infer which world you’re in unless you restate the constraint and the context.
So when I’m prompting changes like this, I now explicitly remind it:
- assume the main table is a god table with heavy callbacks and data pipelines
- avoid adding noisy fields that increase write amplification
- prefer extracting a dedicated model/table for new concerns, and explain the trade-offs
With that context, the model usually produces a much better design.
The meta-point
AI increases your ability to ship quick diffs.
But unless you guide it, it will happily accelerate the behaviour that creates long-term complexity: growing the god table.
So the lesson is simple:
Don’t just ask an LLM to make the change.
Ask it to make the change without growing your god table.
If you already have a test suite, this is the kind of refactor that becomes safe and repeatable:
tests are the contract, and you can prove behaviour didn’t regress while you improve the design.