The concept of AI (or machine learning or algorithms or whatever you feel like calling them) have become a catchall for all sorts of problems and fears. Many of them aren't really problems with AI at all, but issues with capitalism or the internet generally, or just...you know...people.
Alexa and its imitators mostly failed to become much more than voice-activated speakers, clocks and light-switches, and the obvious reason they failed was that they only had half of the problem. The new machine learning meant that speech recognition and natural language processing were good enough to build a completely generalised and open input, but though you could ask anything, they could only actually answer 10 or 20 or 50 things, and each of those had to be built one by one, by hand, by someone at Amazon, Apple or Google. Alexa could only do cricket scores because someone at Amazon built a cricket scores module.
But now, large language models (LLMs) like those built by OpenAI, Google, and Facebook seem to solve the other half of the problem.
instead of people writing the pattern for each possible question by hand, which doesn’t scale, you give the machine a meaningful sample of all the text and data that there is and it works out the patterns for itself, and that does scale (or should do). You get the machine to make the machine, and now you have both the input and the output.
So now we've (theoretically) solved the two halves of the problem: computers can be asked anything and computers can answer anything. What are the next problems that present themselves? Ben identifies two:
The Science Problem
The Product Problem
First the Science Problem (emphasis mine):
The breakthrough of LLMs is to create a statistical model that can be built by machine at huge scale, instead of a deterministic model that (today) must be built by hand and doesn’t scale. This is why they work, but it’s inherent in this that a statistical, probabilistic model does not give a ‘right’ answer in a binary sense, only a probable answer...it will give the right ‘kind’ of answer, which may or may not be the ‘right’ answer. This is not a database.
In other words, LLMs don't care about whether something is true or not. They care about whether something feels like it's the answer you want to hear. This aligns almost perfectly with Harry Frankurt's classic definition of bullshit from On Bullshit:
Bullshit is speech intended to persuade without regard for truth. The liar cares about the truth and attempts to hide it; the bullshitter doesn't care if what they say is true or false.
In terms of usability, it leads to a similar place as the Siris and Alexas of 15 years ago, although for different reasons:
You could ask Alexa anything, but it could only answer ten things. ChatGPT will answer anything, but can you use the answer?
This leads to the second problem that Ben identifies, the Product Problem:
I think that natural language, voice or text are not necessarily the right interface even if you were talking to an AGI, even if it was ‘right’, and, more fundamentally, that asking a question and getting an answer might be a narrow interface, not a general-purpose one.
It all comes back to the uncertainty inherent in the probabilistic nature of LLMs. Almost all tech products are built on the assumptions of a deterministic world, so solutions don't quite fit:
using an LLM to do anything specific is a series of questions and answers, and trial and error, not a process. You don’t work on something that evolves under your hands. You create an input, which might be five words or 50, or you might attach a CSV or an image, and you press GO, and your prompt goes into a black box and something comes back. If that wasn’t what you wanted, you go back to the prompt and try again, or tell the black box to do something to the third paragraph or change the tree in the image, press GO, and see what happens now. This can feel like Battleship as a user interface - you plug stuff into the prompt and wait to find out what you hit.
It feels weird because our solutions are basically "ports" as Jason Fried from 37 Signals puts it in a post talking about how remote work is a platform:
Stuff that’s ported lacks the native sensibilities of the receiving platform. It doesn’t celebrate the advantages, it only meets the lowest possible bar. Everyone knows it. Sometimes we’re simply glad to have it because it’s either that or nothing, but there’s rarely a ringing endorsement of something that’s so obviously moved from A to B without consideration for what makes B, B.
Right now, we're in the experimental phase, trying to figure out how the product should work in a world where these new capabilities exist.
the paradox of ChatGPT is that it is both a step forward beyond graphical user interfaces, because you can ask for anything, not just what’s been built as a feature with a button, but also a step back, because very quickly you have to memorise a bunch of obscure incantations, much like the command lines that GUIs replaced, and remember your ideas for what you wanted to do and how you did it last week - and then you pay someone to turn those command into buttons.
So what's the answer? Heck if I know. But as we see all the experiments out there, it's worth looking out for what Ben Evans calls "the embodied use cases." The specific ways in which the inherent weaknesses of AI (hallucination, bullshitting, etc.) can be compensated for or even turned into strengths through the experience of using the product.
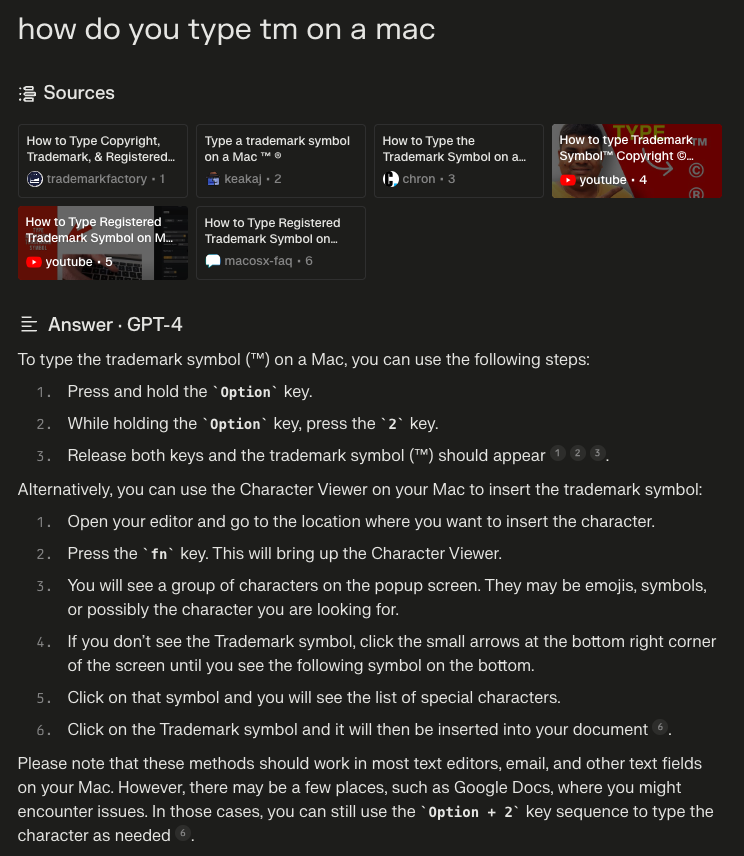
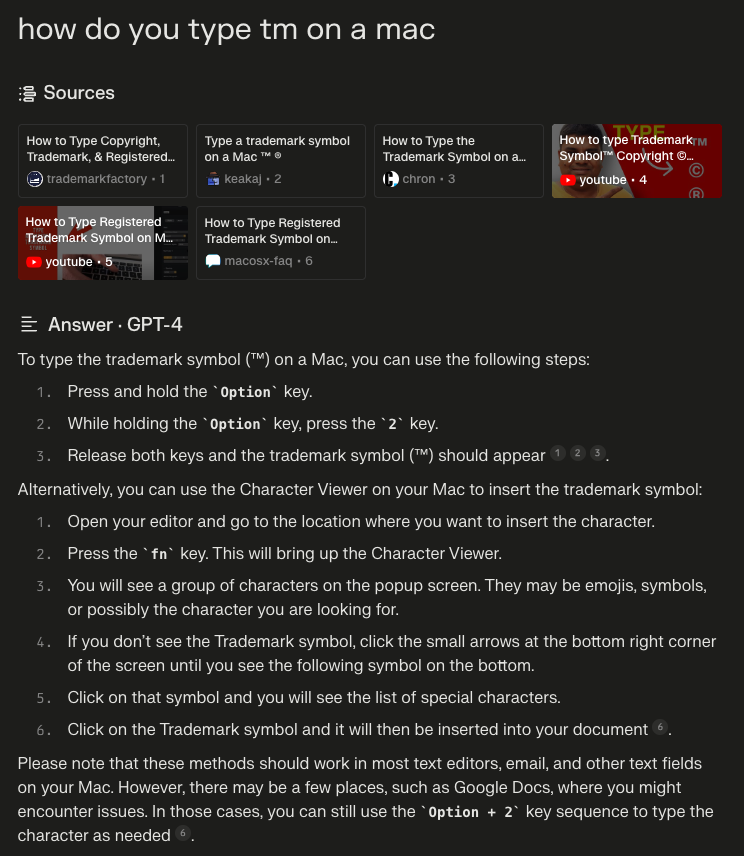
For example, here's the response of an LLM (called Perplexity) when I asked it to help me with the ™ symbol earlier in this post.
The information is all in the links at the top, but none is as succinct as the summary. The answer includes the sources up at the top (which emphasizes that the LLM isn't just making things up) and includes the titles and websites for those sources (so I can assume the answers are trustworthy and related to my question). It also connects the sources to the text via footnotes so I can follow up and verify if I'm curious about a specific part of the answer.
It's a whole new world. These capabilities exist now. There's no sense in fearing them. It won't stop them. And unlike crypto, LLMs are actually capable of doing things better than previous technologies. The trick will be how to productize them to solve problems better than previous products.