Web Scraping เป็นอีกวิธีหนึ่งที่เราจะใช้ดูดและสกัดข้อมูลที่กระจายอยู่ในเว็บออกมาได้ ซึ่งถ้าลองค้นหาเครื่องมือใน Search Engine ก็จะพบว่าเครื่องมือหลายๆ ตัวที่มีอยู่นั้นพัฒนาด้วย Python ซะเป็นส่วนใหญ่ แต่ด้วยที่เราเป็น Rubyist ถ้าเราจะทำ Web Scraping ด้วย Ruby จะมีแนวทางอย่างไรบ้าง เรามาลองดูกัน
สำหรับตัวอย่างในครั้งนี้ ก็จะยกตัวอย่างที่ว่าถ้าอยากทราบว่ามีหนังสือเล่มไหนออกมาใหม่บ้างในเว็บ Book Depository ซึ่งเราจะดึงมาเฉพาะชื่อหนังสือ ผู้แต่ง และเลข ISBN จากนั้นก็ export ไปเก็บไว้ใน CSV ก็แล้วกัน เอาแบบง่ายๆ พอ ซึ่ง gem ที่เราจะนำมาใช้ก็จะมีดังนี้
สำหรับตัวอย่างในครั้งนี้ ก็จะยกตัวอย่างที่ว่าถ้าอยากทราบว่ามีหนังสือเล่มไหนออกมาใหม่บ้างในเว็บ Book Depository ซึ่งเราจะดึงมาเฉพาะชื่อหนังสือ ผู้แต่ง และเลข ISBN จากนั้นก็ export ไปเก็บไว้ใน CSV ก็แล้วกัน เอาแบบง่ายๆ พอ ซึ่ง gem ที่เราจะนำมาใช้ก็จะมีดังนี้
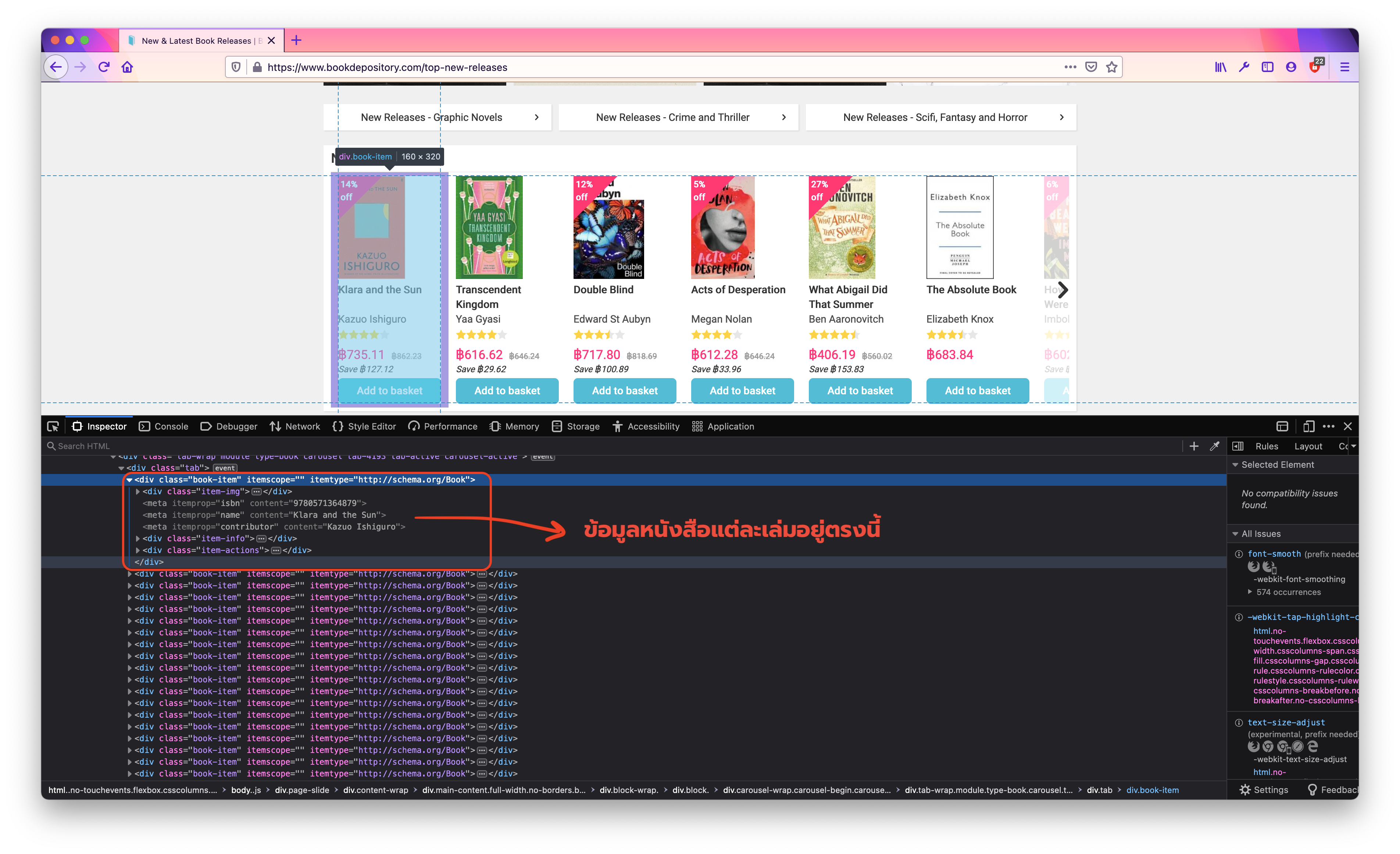
เริ่มต้นก็เราเข้าไปในหน้าเว็บ top-new-releases จากนั้นก็เปิด inspector เพื่อดูว่าข้อมูลที่อยากได้อยู่ที่ element ไหน และพบว่าหนังสือแต่ละเล่มจะอยู่ภายใต้ div ซึ่งมี class name ชื่อ book-item โดยภายในก็จะมีชื่อหนังสือ ชื่อผู้แต่ง และเลข ISBN อยู่ใน meta อีกทีหนึ่งดังแสดงในรูปด้านล่าง
ที่นี้ก็ลงมือเขียนโค้ดกันเลย
require 'httparty'
require 'nokogiri'
require 'csv'
class Scraper
include HTTParty
CONTENT = /content="([\w\s\d\:\-\u00E9'\(\)!&;:?.,]+)"/
def start(url)
response = HTTParty.get(url)
doc = Nokogiri::HTML(response.body)
books = doc.css('.book-item').map do |link|
title = meta(link, 'name')
author = meta(link, 'contributor')
isbn = meta(link, 'isbn')
Book.new title: title, author: author, isbn: isbn
end
export_to_csv(books)
end
def meta(link, name)
CONTENT.match(link.css("meta[itemprop='#{name}']").to_s).captures.first
end
def export_to_csv(books)
CSV.open("./data/books.csv", "wb") do |csv|
csv << [ 'title', 'author', 'isbn' ] # header
books.each do |book|
csv << [ book.title, book.author, book.isbn ]
end
end
puts "Export to CSV success"
end
end
class Book
attr_accessor :title, :author, :isbn
def initialize(**kwargs)
kwargs.each do |key, value|
send("#{key}=", value)
end
end
end
Scraper.new.start 'https://www.bookdepository.com/top-new-releases'
เพียงเท่านี้เราก็สามารถที่จะได้รายการหนังสือใหม่ และเก็บลงใน CSV เป็นที่เรียบร้อย แต่ที่จริงแล้วเราสามารถนำไปประยุกต์ให้เกิด automation ขึ้นได้ผ่าน cron job หรือทำการบันทึกลงฐานข้อมูลแทนไฟล์ก็ได้