Toen ik ik dit concept onderzocht, deed ik een mooie bijvangst en vond ik nóg twee begrippen die ik eerder had willen kennen en snappen: inverted index en vector search. Ik had van geen van drieën gehoord, terwijl het eerste in vrijwel elke applicatie zit, het tweede in alles met een zoekfunctie, en het derde in steeds meer AI-toepassingen.
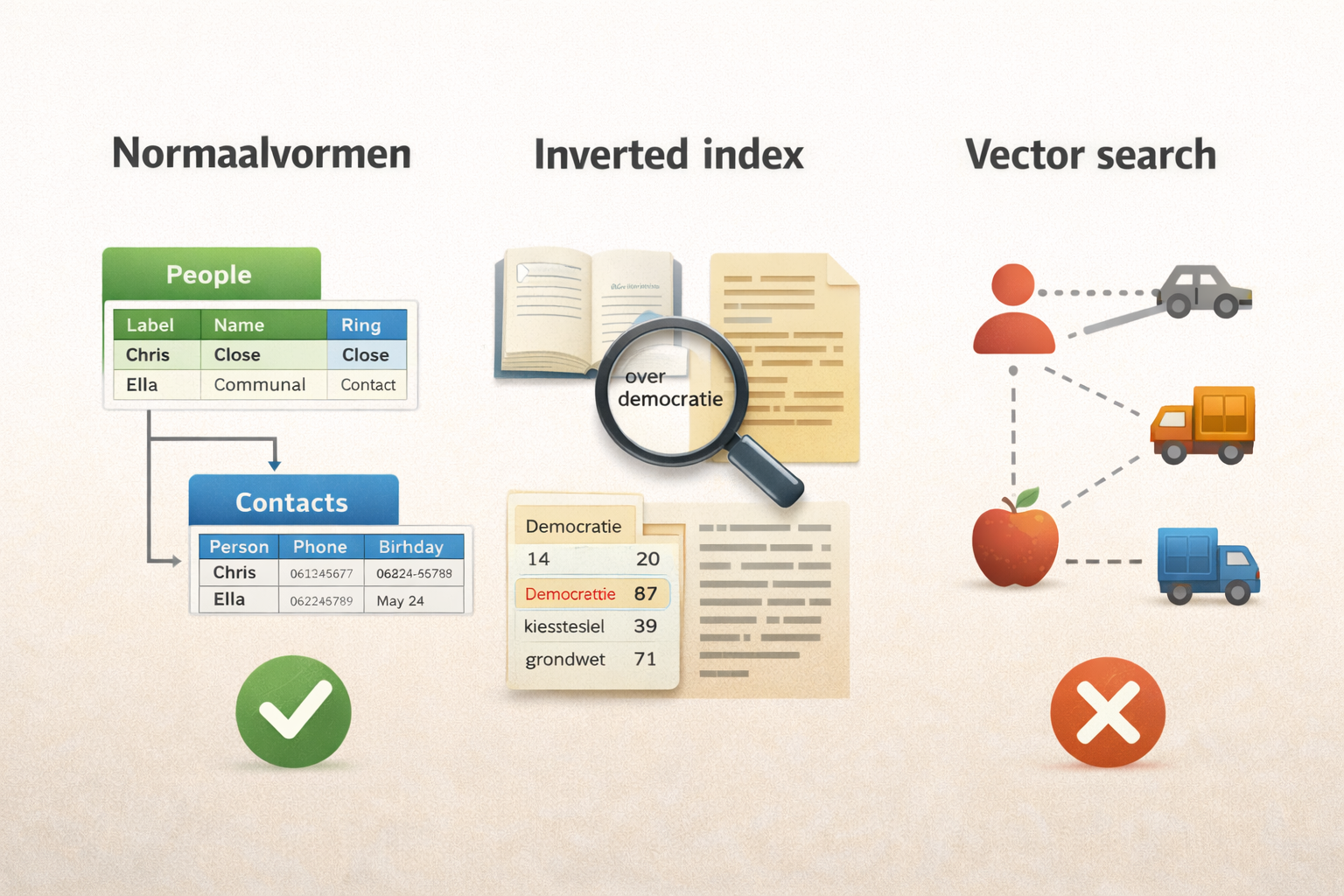
Normaalvormen: de kunst van niet twee keer hetzelfde opschrijven
Ik loop hier zelf tegenaan in ThetaOS. Ik heb daarin van alle mensen in mijn netwerk een profiel, met naam, contactgegevens, verjaardag, en in welke ring ze zitten (ik werk met concentrische cirkels: hoe dichter bij het midden, hoe nauwer het contact). Stel dat ik dat allemaal in één grote tabel zou proppen. Dan staat het adres van Mark Meinema er drie keer in, omdat hij in drie verschillende contexten voorkomt. Verhuist Mark, dan moet ik op drie plekken aanpassen. Vergeet ik er eentje, dan klopt mijn administratie niet meer.
In de jaren zeventig bedacht Edgar Codd, een wiskundige bij IBM, een systeem om dit soort problemen structureel op te lossen. Hij noemde het normalisatie, en de stappen daarin heten normaalvormen. Het principe is eigenlijk elegant: je splitst informatie op in de kleinst mogelijke logische eenheden, zodat elk gegeven maar op één plek staat. Dat herken ik al een tijdje, omdat het precies is hoe ik wikilinks gebruik in mijn persoonlijk kennismanagement met Obsidian. Elk begrip heeft daar één notitie, en alles wat ernaar verwijst linkt ernaartoe in plaats van de informatie te kopiëren. Mijn boeken Starten met Obsidian en Verder met Obsidian gaan daar in de kern over.
De eerste normaalvorm is het simpelst: elk vakje in je tabel mag maar één waarde bevatten. Dus niet drie telefoonnummers in één cel, maar drie aparte rijen. De tweede normaalvorm gaat over samenhang: als je een tabel hebt met bestellingen, dan hoort de naam van de klant daar niet in thuis, want die hangt niet af van de bestelling maar van de klant. Die naam hoort in een aparte klanttabel, en de bestelling verwijst daar alleen naar met een nummer. De derde normaalvorm trekt dat nog iets strakker: als je in die klanttabel zowel de stad als de postcode opslaat, is dat eigenlijk ook dubbel, want de postcode kun je afleiden uit de stad. Een van die twee mag eruit.
Zonder te weten dat hier al mensen heel diep over nagedacht hadden, kwam ik blijkbaar op hetzelfde spoor. Ik schreef vorig jaar een ontologie die ik al een tijd gebruikte en die mensen aan het overnemen zijn. Het principe komt op dezelfde manier tot stand: je probeert zo atomair mogelijk te kijken naar informatieelementen die je vaak gebruikt. Dat scheelt niet alleen in data, maar ook in verbindingskracht.
Inverted index: de truc achter elke zoekbalk
Het tweede begrip dat ik tegenkwam was inverted index. De gedachte erachter is supersimpel. Zoals die handige lijst met woorden achterin een boek. Bij het woord "democratie" staat: pagina 14, 87, 203. Je hoeft niet het hele boek door te bladeren, de index vertelt je precies waar je moet zijn. Een inverted index doet precies hetzelfde, maar dan voor elke zoekterm in elke tekst in een hele verzameling documenten.
In ThetaOS kan ik via Moltbot (nu OpenClawd), mijn chatbot op Signal, zoeken in al mijn notities en documenten. Als ik intik "wanneer sprak ik laatst met Peter", doorzoekt het systeem mijn gegevens op die exacte woorden. Razendsnel, omdat het niet alle documenten hoeft door te lezen maar alleen de index raadpleegt. Datzelfde principe zit achter Google en achter vrijwel elke zoekbalk die je dagelijks gebruikt, van je mailprogramma tot je telefoon. Het bestaat al sinds de jaren zestig.
Worden dan álle woorden geïndexeerd? Nee, want woorden als "de" en "het" en "een" komen zo vaak voor dat ze niets onderscheidends opleveren. Er bestaat voor elke taal een stopwoordenlijst met dat soort woorden, en die worden bij het opbouwen van de index overgeslagen.
In het Nederlands nemen de twintig meest voorkomende woorden bijna de helft van alle tekst in beslag, dus door die weg te laten houd je een veel compactere en bruikbaardere index over. Sommige systemen gaan nog een stap verder en herkennen dat "fietsen", "fiets" en "gefietst" varianten zijn van hetzelfde woord, zodat je ook resultaten vindt als je net een andere vorm gebruikt dan in het origineel staat. Dat heet stemming.
Als ik zoek op "auto" vindt zo'n index niets over "voertuig", want hij heeft geen idee dat die woorden over hetzelfde gaan.
Vector search: zoeken op betekenis
Om dat op te lossen bestaat er dus nog een derde mechanisme dat ik deze week bij toeval ontdekte. Vector search kan iets wat een inverted index niet kan: zoeken op betekenis in plaats van op woorden.
De makkelijkste manier om het uit te leggen is met een bibliothecaris die elk boek in de collectie heeft gelezen. Als je vraagt "ik wil iets weten over hunebedden", geeft hij je niet alleen geschiedenisboeken of aardrijkskundeboeken met het woord hunebed erin, maar ook dat boek dat ik schreef over hoe ik in 2002 met 14.000 mensen samen een hunebed bouwde. Hij snapt dat dat er ook mee te maken heeft, ook al gaat het over iets heel anders. Een computer kan dat niet, die kan niet echt lezen. Maar er is een truc bedacht die in de buurt komt. Het systeem zet elk stukje tekst om in een lange reeks getallen, waarbij elke positie iets zegt over een aspect van de betekenis. Het woord "auto" krijgt daardoor een getallenreeks die dicht ligt bij die van "voertuig", en ver weg van "appel". Als je zoekt, wordt je zoekopdracht ook omgezet in zo'n reeks, en het systeem kijkt welke teksten de meest gelijkende getallen hebben.
Wat ik er fascinerend aan vind is waarom het werkt. Niemand heeft geprogrammeerd dat "auto" en "voertuig" bij elkaar horen. Het systeem heeft miljarden teksten doorgewerkt en daarin ontdekt dat die twee woorden steeds in vergelijkbare contexten opduiken. Dit is hoe kinderen leren wat woorden betekenen. Dat leren ze niet uit een woordenboek, maar doordat ze die woorden in verband met elkaar in context horen. Vector search doet in wezen hetzelfde, maar dan met meer tekst dan wij als mensen ooit zouden kunnen lezen.
Dit is eigenlijk ook hoe AI-systemen als Claude en ChatGPT werken: door gigantische hoeveelheden tekst te verwerken en daar patronen uit te leren. Als je zo'n systeem vervolgens loslaat op je eigen data, maakt het van al jouw documenten zulke getallenreeksen aan waarmee het op betekenis kan zoeken in jouw eigen verzameling.
Drie lagen van ordening
Wat ik geweldig vind is het verband tussen deze drie mechanismen. Normaalvormen dwingen je dus om gegevens schoon op te slaan, een inverted index maakt ze doorzoekbaar op woorden, en vector search voegt daar iets aan toe wat op begrip lijkt. Ik paste de eerste twee al toe in ThetaOS zonder te weten hoe ze heetten.
Net als bij cronjobs geldt: dit zijn geen nieuwe uitvindingen. Het zijn concepten die al decennia bestaan maar die verstopt zitten onder de motorkap van je computer. Het voelt alsof we met de komst van Windows en macOS de werking van die wonderapparaten hebben afgedekt met een visueel aantrekkelijke interface, maar daarmee ook het begrip ervan zijn kwijtgeraakt. Ik schat dat een stuk of twintig van dit soort begrippen, met een beetje context, een wereld van verschil kunnen maken. Ik ga ze verder ontdekken en ze hier delen.