
Lezers van dit blog weten dat ik al geruime tijd nieuwe inzichten en vaardigheden aan het verwerven ben op het zelf kunnen omgaan met data en informatie. De drempel om met simpele scripts automatisch tekst in bestanden te kunnen verwerken is met de komst van hulpwieltjes als ChatGPT zo laag geworden dat het niet meer intimiderend voelt.
Mijn favoriete tool van dit moment om mijn kennis en informatie te kunnen vangen, vinden, ordenen en delen is Obsidian. Ik schreef er niet voor niets een heel boek over. Begin augustus ontdekte ik iets interessants:
Ik houd in Obsidian een dagelijkse notitie bij. Dat gaat automatisch via een template (in mijn boek vind je hoe). In die template staan dingen die ik privé en werk-technisch op de radar wil houden. Hieronder zie je een blokje uit die template.
Omdat ik dit jaar door mijn herseninfarct opgenomen was in een ziekenhuis en revalidatiecentrum vroeg ik me af hoe ik makkelijk kon zien hoe vaak ik dit jaar niet thuis sliep. Doordat ik elke dag een waarde (standaard mijn huis) in mijn dagelijkse notitie achter het veld Wakker in: heb staan, kon ik makkelijk een pagina in Obsidian maken met iets als: Kijk in al mijn dagelijkse notities van dit jaar, check wat er achter Wakker in: staat, en als daar NIET mijn huis staat, tel dan hoe vaak ik elders wakker werd.
Het maken van die zoekslag (Query) in automatisch laten verschijnen op de pagina Waar logeerde ik in 2025 was met ChatGPT een kwestie van minuten. Eenmalig. Leuk (en soms handig).
Maar deze post gaat over de Slaapapneu en Gewicht. Die vul ik ook dagelijks in. En daardoor kan ik op dezelfde manier een handig overzicht maken, en zelfs de getallen laten correleren of rood of groen laten worden als ze boven of onder een bepaalde waarde zijn. Daar heb ik dus een overzichtpagina voor (net als de logeerpagina) die heet: 📊👨⚕️ Health stats Martijn (relevanter dan voorheen gezien mijn infarct.)
Ik liet trots aan mijn lief zien wat ik geknutseld had (ik vond dit al behoorlijk interessant). Toen vroeg ze of ik dat ook met mijn bloeddruk-data kon doen. Leuke vraag. Dan zou ik wellicht verbanden kunnen leggen die best relevant zijn. Maar hoe?
Omdat bloeddruk een cruciaal element is bij een herseninfarct neem ik die flink serieus en heb ik niet bezuinigd op een goede bloeddrukmeter. Deze stuurt via bluetooth de data naar mijn iPhone-app.
Ik ging naar de app, en klikte op exporteren naar een .csv-bestand. Ik kon ook het datum bereik kiezen, heel handig. In mijn iCloud zag ik het bestand en sleepte het naar ChatGPT (voor deze casus vind ik het geen ramp als een tech-bedrijf een setje bloeddrukwaarde zou kunnen inzien, al is die kans nogal klein).
Ik zag hoe de CSV was opgebouwd en zag alle waardes en velden. Ik hoefde alleen datum, boven en onderdruk te hebben.
Nu moest ik die CSV-data in een vorm gieten die makkelijker te verwerken is. ChatGPT tipte me twee toverwoorden: 'parsen' (data vertalen naar iets wat computers snappen) en 'JSON' (een slimmer bestandsformaat dan CSV).
Zie het zo: CSV is als een simpel Excel-lijstje, prima voor boodschappen. JSON is meer een slimme opbergkast waar je alles met labels in kunt stoppen - handig als je bloeddrukmetingen wilt koppelen aan specifieke datums. Bovendien snapt de computer meteen wat getallen zijn en hoeft hij niet te raden.
Ik vroeg ChatGPT dus gewoon: 'Parse deze CSV naar JSON met alleen datum, onder- en bovendruk, en hartslag.' Klaar binnen een paar seconden.
Daarna was het even een paar dagen experimenteren voor ik alles snapte. Ik wilde namelijk volautomatisch die data ónder in mijn rijtje met data in mijn daglog ónder het veld [[⚖️ Gewicht]] hebben. Op de juiste dag en op deze manier: [[🩸 Bloeddruk]] 120/80 ❤️ 68
Maar hoe zorg je ervoor dat al die getallen op deze manier in al die verschillende datums in al die daglogs op de goede datum met de juiste waardes op de juiste plek komen?
Mark Vletter tipte me over MCP's - een manier om Claude echt met mijn bestanden te laten werken. Het installeren van die MCP-servers was even doorbijten (tools installeren, paden configureren, permissies regelen), maar het resultaat is indrukwekkend. Ik wees een map aan (🥼 Maclab) waar Claude in mag werken, en ineens kan hij Python-scripts draaien die automatisch mijn Obsidian-bestanden updaten.
En na wat experimenteren en proberen lukte het. Ik heb nu een AI-tool, die lokaal een python-script draait dat die JSON-file uitleest, en de data op de juiste plek op de juiste manier zet. In 2 seconden.
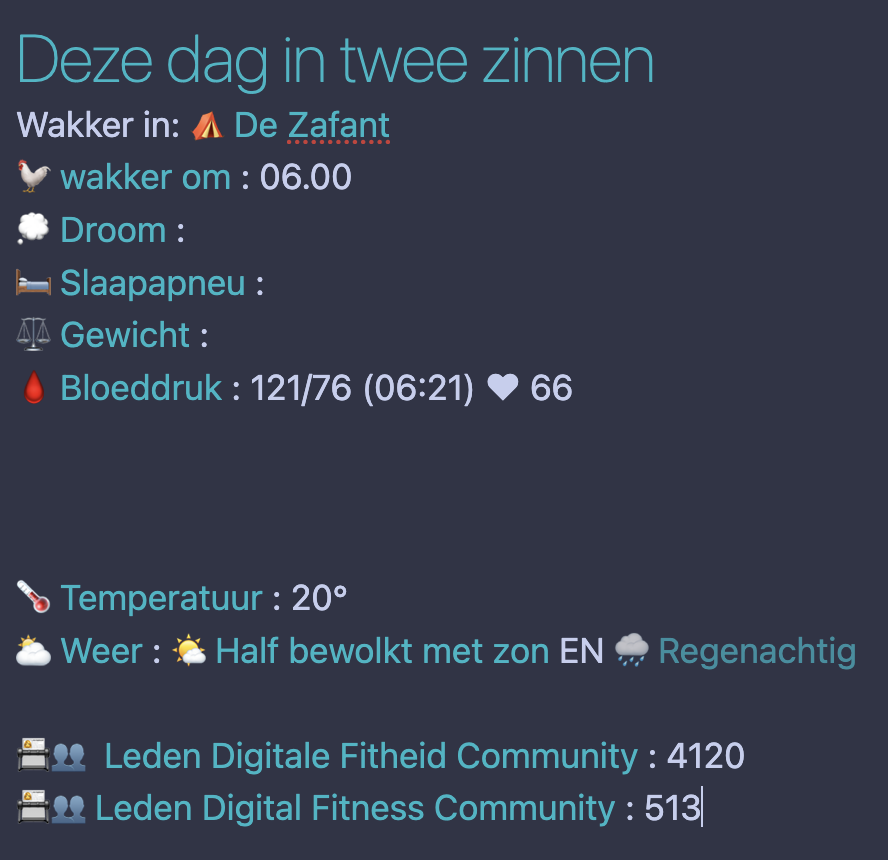
Het resultaat: Elke dag waarop ik mijn bloeddruk heb gemeten, verschijnt deze nu automatisch in mijn daglog: [[🩸 Bloeddruk]] 127/79 ❤️ 72. Ik exporteer maandelijks die data en even later staan ze in mijn daglogs. Maar de echte meerwaarde ligt elders: in Obsidian kan ik nu queries maken die mijn bloeddruk correleren met andere factoren. Een slechte nacht volgens mijn slaapapneu-score? Dat blijkt zich te vertalen in hogere bloeddrukwaarden. Voor iemand die na een herseninfarct zijn gezondheid nauwkeurig moet monitoren, zijn deze inzichten heel waardevol.
Het doet me denken aan Stach uit de Koning van Katoren die ontdekt dat de geleerde geneesheren oplichters zijn. Veel IT-mystiek blijkt ook gewoon duurdoenerij. De tools zijn er, gratis en toegankelijk. Je hoeft alleen maar te durven experimenteren. En ja, gebruik markdown in plaats van pdf's - dat scheelt een hoop gedoe bij het automatiseren.
Wil je meer weten over hoe je met Obsidian slimmer met je eigen informatie om kunt gaan? Lees dan mijn nieuwe boek.