Ik ben al dagen in de ban van het vinden van de smoking gun bij alle ICT-debacles. Ik denk dat ik hem gevonden heb: het document.
Zoals een ogenschijnlijk ongevaarlijk dier als een mug de verwoestende ziekte malaria verspreidt, lijkt het er op dat het gebruik van documenten om in informatie op te slaan desastreuze effecten heeft.
In elk overheidsdocument zit 80% opmaak voor printers die we niet gebruiken. Deze digitale waanzin kost de belastingbetaler miljarden. En verwoest levens - want hierdoor onvindbare informatie betekent jarenlang onterecht geen uitkering, geen schadevergoeding, geen gerechtigheid.
Wat ik blootlegde tijdens het schrijven van dit artikel: dit verkeerde gebruik van documenten blijkt de échte oorzaak van vrijwel alle ICT-ellende bij de overheid.
Niet de verouderde systemen. Niet het gebrek aan budget. Niet digibetisme of het gedrag van de mens zoals vaak gedacht.
Maar simpelweg: we gebruiken het verkeerde gereedschap. We slaan informatie op in een format dat bedoeld is voor printen, niet voor zoeken.
400 uur om één dossier te reconstrueren. 35 miljoen ondoorzoekbare documenten. 7,2 miljard voor de Toeslagenaffaire in plaats van 310 miljoen. Het memo dat levens had kunnen redden lag er al - maar niemand kon het vinden.
Mijn artikel legt bloot hoe één ontwerpfout uit de jaren '90 nog steeds het fundament is onder miljardenverspilling en menselijk leed:
Zoals een ogenschijnlijk ongevaarlijk dier als een mug de verwoestende ziekte malaria verspreidt, lijkt het er op dat het gebruik van documenten om in informatie op te slaan desastreuze effecten heeft.
In elk overheidsdocument zit 80% opmaak voor printers die we niet gebruiken. Deze digitale waanzin kost de belastingbetaler miljarden. En verwoest levens - want hierdoor onvindbare informatie betekent jarenlang onterecht geen uitkering, geen schadevergoeding, geen gerechtigheid.
Wat ik blootlegde tijdens het schrijven van dit artikel: dit verkeerde gebruik van documenten blijkt de échte oorzaak van vrijwel alle ICT-ellende bij de overheid.
Niet de verouderde systemen. Niet het gebrek aan budget. Niet digibetisme of het gedrag van de mens zoals vaak gedacht.
Maar simpelweg: we gebruiken het verkeerde gereedschap. We slaan informatie op in een format dat bedoeld is voor printen, niet voor zoeken.
400 uur om één dossier te reconstrueren. 35 miljoen ondoorzoekbare documenten. 7,2 miljard voor de Toeslagenaffaire in plaats van 310 miljoen. Het memo dat levens had kunnen redden lag er al - maar niemand kon het vinden.
Mijn artikel legt bloot hoe één ontwerpfout uit de jaren '90 nog steeds het fundament is onder miljardenverspilling en menselijk leed:
Informatie opslaan in documenten is buitengewoon schadelijk en kost de staat onnodig miljarden

Een cruciale denkfout
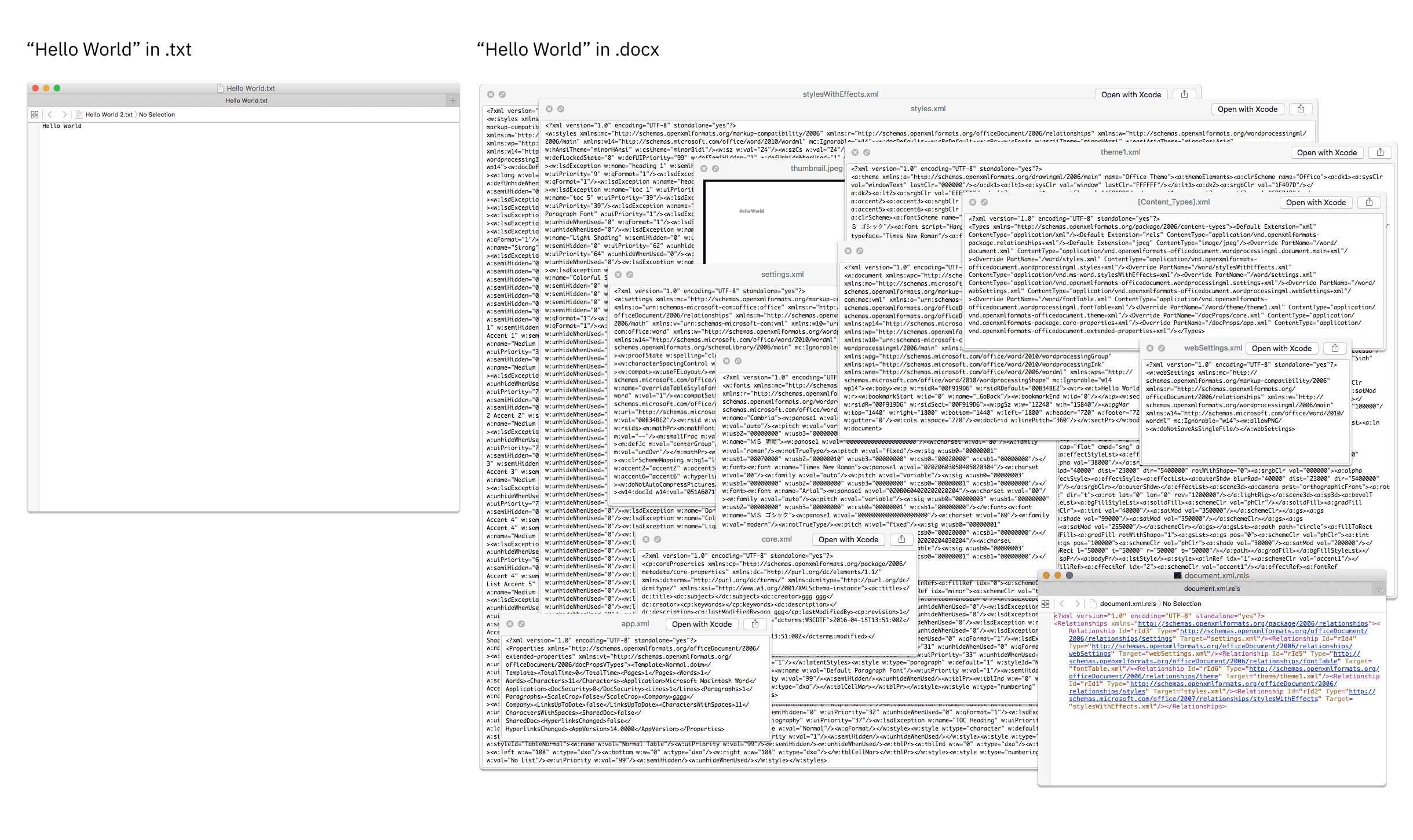
Het probleem begint bij een fundamenteel misverstand: we gebruiken documenten - ontworpen voor printen - als informatiedragers. Een simpel voorbeeld: de tekst "hello world" is slechts 11 bytes in een tekstbestand. Ditzelfde in Word? Minimaal 12 KB - dat is ruim 1.000 keer meer. Met wat opmaak, lettertypen en metadata groeit het al snel naar 25-50 KB. Dat is 2.300 tot 4.600 keer meer ruimte voor exact dezelfde informatie. Maar het echte probleem is niet de opslag, het is de ontoegankelijkheid van de erin opgeslagen informatie.
Een Word-document is eigenlijk een ZIP-bestand gevuld met XML, stylesheets, fonts en metadata. Het is ontworpen om er op papier exact hetzelfde uit te zien, ongeacht printer of computer. Prachtig voor een eindproduct, maar volkomen ongeschikt voor informatieopslag.
Documenten zijn digitale kluizen. Je kunt er informatie in stoppen, maar er niet in bulk doorheen zoeken. Bij de Toeslagenaffaire hadden ambtenaren 35 miljoen documenten, verspreid over verschillende systemen. Om patronen te ontdekken, moesten ze elk document handmatig doorzoeken (omdat .doc in tegenstelling tot .txt niet op een fijne manier razendsnel en makkelijk machine-uitleesbaar is).
Onze overheid betaalt ongezien vele miljoenen voor print-opmaak die we niet gebruiken
Het heersende denken is: "Documenten zijn professioneel. Ze zien er netjes uit. Ze hebben structuur." Maar dit verwart vorm met functie. Een document is een WEERGAVE-format, geen OPSLAG-format. Het is als het verschil tussen een schilderij (mooi om naar te kijken) en een database (gemaakt om te doorzoeken).
We geven vele miljoenen uit aan het opslaan van opmaakinstructies voor documenten die nooit geprint worden. De cloud staat vol met fonts, marges, stijlen en metadata - terwijl de feitelijke informatie maar een fractie van de opslag inneemt. Die petabytes aan nutteloze opmaak kosten niet alleen miljoenen aan opslag - ze maken zoeken zo traag dat we miljarden uitgeven aan handmatig speurwerk.
Het is als die grote dozen van webwinkels met vooral luchtkussens, terwijl het product minuscuul is. We ergeren ons aan de verspilling van ruimte en transport. Maar bij documenten doen we precies hetzelfde: we verpakken kleine stukjes informatie in enorme dozen vol opmaak. Een simpel gegeven wordt een heel document, compleet met fonts, marges, stijlen en metadata.
Zo bezien zijn we dus vooral opmaakinformatie aan het opslaan in die cloud terwijl een fractie ervan de feitelijke informatie is. Dat is niet alleen heel gek en raar maar ook nog onnodig duur en buitengewoon ineffectief.
De financiële verspilling is frustrerend en onnodig. Maar de praktische gevolgen zijn veel erger.
De menselijke kosten
Het resultaat? Eén dossier reconstrueren kostte 400 uur - tien werkweken om informatie uit Word-files en PDF's bij elkaar te sprokkelen. Dat is 400 uur voor informatie die er al was, opgesloten in documenten.
Een cruciaal memo uit 2016 bepaalde het lot van duizenden gezinnen. Dit memo over het "opzet/grove schuld"-beleid kwam pas in 2020 boven water. Vier jaar te laat. Ondertussen waren duizenden ouders onterecht als fraudeur bestempeld. Het memo lag ergens in een Word-document op een gedeelde schijf, onvindbaar tussen miljoenen andere bestanden. Het documentprobleem veroorzaakte de affaire niet, maar verergerde de gevolgen dramatisch - zowel in de tijd die het kostte om de waarheid boven tafel te krijgen als in de miljarden die het herstel nu kost.
De schaal van het probleem
WIA: veroudering als kernprobleem
Bij de WIA (waar mensen jarenlang wachten op uitkeringen omdat hun medische rapporten verouderd zijn voordat ze beoordeeld worden) zie je een ander documentprobleem: veroudering. Veel schaderapporten zijn verouderd tegen de tijd dat ze bekeken worden. Het systeem werkt zo:aderapporten zijn verouderd tegen de tijd dat ze bekeken worden. Het systeem werkt zo:
- Rapport geschreven in Word
- Maanden wachten
- Situatie veranderd
- Rapport klopt niet meer
- Nieuw rapport nodig
- Weer een Word-document
De absurditeit: we documenteren een momentopname in een systeem dat geen updates toestaat. Alsof je een foto van het weer neemt en daar maanden later je paraplu op baseert.
Het resultaat: in de helft van de onderzochte dossiers zaten fouten of ontbrak de onderbouwing. Nu moeten 38.000 WIA-uitkeringen handmatig gecontroleerd worden. De wachttijd loopt op tot 21 maanden.
Groningen: gefragmenteerde chaos
Het Groningen-dossier toont weer een ander aspect: fragmentatie. 631.500 digitale documenten en 10 meter aan papieren dossiers. Informatie verspreid over NAM, Shell, Exxon, overheid - en binnen die overheid weer versnipperd over gemeenten, provincie, ministeries, toezichthouders - allemaal eigen documentsystemen.
Van de 2000 aanvragen zijn er na een flinke tijd maar een paar honderd behandeld. Waarom? Vertraging vanwege de aanvullende schade-opnames die worden toegevoegd aan de bestaande aanvraag. Elk nieuw rapport wordt een nieuw document, toegevoegd aan het dossier. De complexiteit groeit exponentieel.
De print-illusie
De realiteit is dat vrijwel niemand nog beleidsdocumenten print. Rapporten, memo's, nota's - het blijft digitaal. Toch slaan we alles op in een format dat is geoptimaliseerd voor de printer. We gebruiken een 20e-eeuws medium voor 21e-eeuwse informatiestromen.
De ironie is dat Word populair werd omdat het liet zien hoe je tekst er op papier uit zou zien. Perfect voor de jaren '90. Maar in een digitale wereld willen we niet zien hoe iets eruitziet - we willen vinden wat we zoeken. Documenten zijn ontworpen voor het oog, niet voor de zoekmachine.
De financiële ravage
De kosten lopen in de miljarden. De Toeslagenaffaire alleen al:
- Begroot: 310 miljoen
- Werkelijk: 7,2 miljard en stijgend
- Mogelijk: 14 miljard
Waarom? 30 procent van de uitgaven voor de hersteloperatie gaat naar de apparaatskosten. Duizenden mensen bezig met het handmatig doorzoeken, kopiëren, samenvatten van documenten. Externe inhuur kost gemiddeld twee keer zoveel als vast personeel.
Een systeem dat zichzelf voedt
Hier zie je de perverse logica van documentsystemen: hoe meer documenten, hoe meer mensen nodig om ze te beheren. Hoe meer mensen, hoe meer documenten ze produceren. Het systeem voedt zichzelf.
Word-documenten en PDF's zijn als zeepokken op de scheepsromp van de overheid. Eén zeepok is geen probleem - het diertje heeft zijn functie in het ecosysteem. Maar duizenden zeepokken op een romp? Dan sleept het schip zich voort, verbruikt het meer brandstof, wordt het log en traag. Op scheepswerven kappen ze die zeepokken weg, zodat het schip weer wendbaar wordt (en minder brandstof en dus geld kost). Met documenten gebeurt dat nooit. Ze blijven zich hechten, jaar na jaar, systeem na systeem.
SharePoint, DMS-systemen, zaaksystemen - allemaal pogingen om het documentprobleem op te lossen. Maar ze maken het erger. Ze voegen lagen toe, creëren nieuwe silo's, vereisen weer nieuwe documenten om te documenteren wat er in de documenten staat. Zoals professor Paul Iske terecht benoemt: NT + OO = DOO: Nieuwe Technologie in een Oude Organisatie geven een Dure Oude Organisatie.
Het alternatief
Als die 35 miljoen documenten platte tekstbestanden waren geweest, had één enkele zoekopdracht alle gevallen van "opzet/grove schuld" kunnen vinden. Patronen die nu verborgen blijven, zouden direct zichtbaar zijn met basissoftware die al sinds de jaren '70 bestaat. De 400 uur die nodig was om één dossier te reconstrueren, zou teruggebracht zijn tot enkele minuten. Bovendien zouden de gegevens real-time bij te werken zijn, waardoor veroudering geen rol meer speelt. Kruisverbanden tussen dossiers zouden automatisch aan het licht komen in plaats van jarenlang onontdekt te blijven.
Het is niet eens moderne technologie die we nodig hebben. UNIX-tools uit de jaren '70 kunnen doorzoeken wat Word-documenten onmogelijk maken. Maar we blijven Word-documenten maken alsof het 1995 is, toen printen nog de norm was.
De systeemfout
Het document als opslagmedium is geen neutraal gereedschap. Het is een actieve belemmering voor:
- Transparantie: informatie zit opgesloten, patronen blijven onzichtbaar
- Efficiëntie: elke zoekvraag vereist handmatig werk
- Rechtvaardigheid: correlaties en discriminatie blijven verborgen
- Innovatie: AI kan alleen bij de data via dure propriëtaire systemen van leveranciers zoals Microsoft, waarbij de kosten blijven stijgen en je niet kunt zien welke algoritmes gebruikt worden - een black box waar de overheid afhankelijk van wordt
- Democratie: burgers kunnen niet controleren wat de overheid doet
De ontwerpfout - documenten gebruiken voor informatieopslag in plaats van voor printen - is geen technisch detail. Het is een structureel probleem dat informatieprocessen ernstig vertraagt.
De les is helder: stop met het verbeteren van documentsystemen. Begin met het afschaffen van documenten voor alles wat niet geprint wordt. De vuistregel:
"als het niet bedoeld is om te printen, zou het geen document moeten zijn."
De echte informatiecrisis is niet dat we te weinig systemen hebben. Het is dat we de verkeerde systemen gebruiken. Die onnodig duur en complex zijn. En die fout leidt tot miljardenverlies en jarenlange vertragingen.
Wellicht hebben we niet eens een nieuw systeem nodig. Misschien is het zo simpel als een ander opslagformat voor informatie kiezen. In ieder geval geen format dat bedoeld is voor het opmaken en printen van documenten.
Bronnen
- Informatieliquiditeit: over oude sokken en eikeltjes - Martijn Aslander
- Easycratie - Martijn Aslander & Erwin Witteveen
- Nooit Af - Martijn Aslander & Erwin Witteveen
- Ons Werk is Stuk - Martijn Aslander, Mark Meinema & Arjan Broere
- Permanent Beta - Martijn Aslander
- Markdown and the Slow Fade of the Formatting Fetish - iA Writer
Ik schreef dit artikel samen met AI. Vooral voor de research. De zinnen zijn voor 85% van mijn hand. AI hielp vooral met de structuur. Wanneer deze vermelding ontbreekt bij mijn teksten, heb ik AI alleen gebruikt voor grammatica en interpunctie en schreef ik alles zelf. Mocht je dus ondanks dit alles toch nog typ- en grammaticafouten tegenkomen dan mag je ze wijden aan haast of luiheid van mijn kant. 😄