Hello 👋
This is going to be a little series of working towards prototypes and implementations to fix replacement cycling attacks.
Why is this important?
As the current state of the lightning network, malicious actors have a capacity to bribe miners on channel resolutions, consequently, have a capacity to steal funds from peers.
This bribing issue was brought to light on the mailing list by Matt around 2020 [1]. Since then, some of the methods for mempool pinning related problems were mitigated, new sophisticated methods were found [2], leaving bribes an open problem in the lightning space.
Previously needed background
I’m listing few general and not detailed concepts that are helpful to remind, you can skip them if you already familiar with the problem
- Inputs in multi-input transactions can be removed using transaction replacement methods [3]
- Every LN channel has a 2-2 multisig output that locks the funds (aka funding transaction)
- Every side of a LN channel stores and updates a unconfirmed transaction, aka commitment transaction. This transaction has outputs for each party.
- Every payment that goes through the lightning network uses HTLCs and updates the commitment transaction.
- HTLCs is an output added to the commitment transaction that has a smart contract with two main clauses, as Bitcoin OpTech describes: “a payment clause secured with a hash lock and a refund clause secured with a time lock. To open a hash lock and claim a payment, the receiver needs to reveal the preimage to a hash digest encoded in the contract. To open a time lock and receive a refund, the spender needs to wait until after a certain time encoded in the contract” [4].
- When a payment goes through, a secret (preimage) is generated from the receiver side and HTLCs are generated through all hops in the network. Each HTLC has a different locking time giving a CLTV delta time (CheckLockTimeVerify delta time) that lets a window of time for any HTLC channel resolution between peers. Elle Mouton has a perfect explanation of these. [5] [6] [7]
What are Replacement Cycling attacks?
Replacement cycling attack is a method that makes use of transaction input replacements and HTLCs scripts conditions, to make forcefully stuck HTLCs not be confirmed until CLTV delta from the HTLC on a previous (malicious) hop timeout. After the timeout, as the attacker has the preimage, spend the funds from the stuck payment, stealing the payment that went through the HTLC.
A lot of words, I would suggest refer to the following timeline from Antoine Riard paper example published in the mailing list [8]:
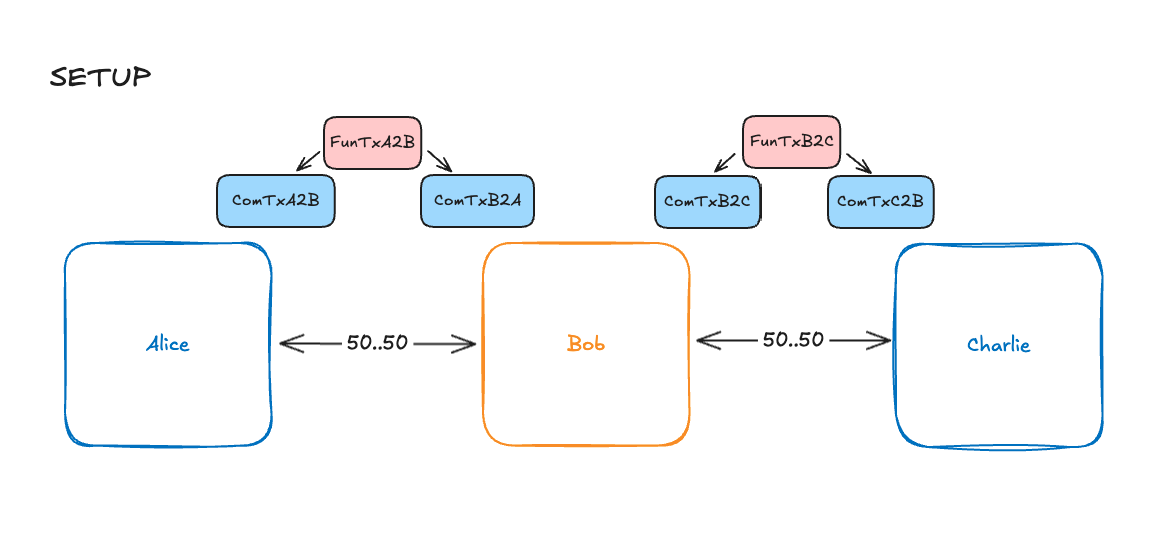
Setup
3 Nodes, Alice, Bob and Charlie.
Topology of the network: A -> B -> C
Alice and Charlie are considered attackers and Bob is the victim.
Current block height is 1000.
Channels are open with the following nomenclature:
- Funding Transaction between Alice and Bob: `FunTxA2B`
- Funding Transaction between Bob and Charlie: `FunTxB2C`
- Commitment Transactions between Alice and Bob / Bob and Alice: `ComTxA2B` / `ComTxB2A`
- Commitment Transactions between Bob and Charlie / Charlie and Bob: `ComTxB2C` / `ComTxC2B`
On figures, red boxes are confirmed transactions, blue boxes are transactions that nodes has them, orange is attacker broadcasted transactions and yellow boxes are victim broadcasted transactions.
Attacking timeline
1. Block height 1000
Alice sends to Charlie 1 BTC through Bob
HTLC outputs are formed with different timeouts:
Alice to Bob HTLCs (HTLC-A2B-Offerer & HTLC-A2B-Receiver)
Bob to Charlie HTLC (HTLC-B2C-Offerer & HTLC-B2C-Receiver)
* Note: For now I would use only the offerer side as is the one compromised with the HTLC-Timeout and the HTLC-preimage
The nLockTime of HTLC-A2B-Timeout Tx is 1080
The nLockTime of HTLC-B2C-Timeout Tx is 1020
* Note: nLockTime means that the transaction wouldn’t be mined (or is not valid) until that blockheight. The difference between both timeouts is given the CLTV-delta expiry of that hop. You can check Elle’s explanation on this [5] or bolt [9].
2. Block height 1019
Charlie broadcast an `AncestorTx` to be used as part of the input replacement using a chain of transactions.
* Note: This transaction is not required to be broadcasted in this block height. Could be earlier, or even a few blocks later. But, this transaction needs to be confirmed to take part in the attack.
3. Block height 1023
Bob lightning implementations broadcast commitment transactions on timeout + 3 blocks. Therefore, broadcast `ComTxB2C`, starting a forced closure of the channel.
* Note: The delta 3 blocks of the implementation is given to do cooperative settlement, taking into account asymmetries in block propagation or other related problems. Implementation could do less or more blocks as delta.
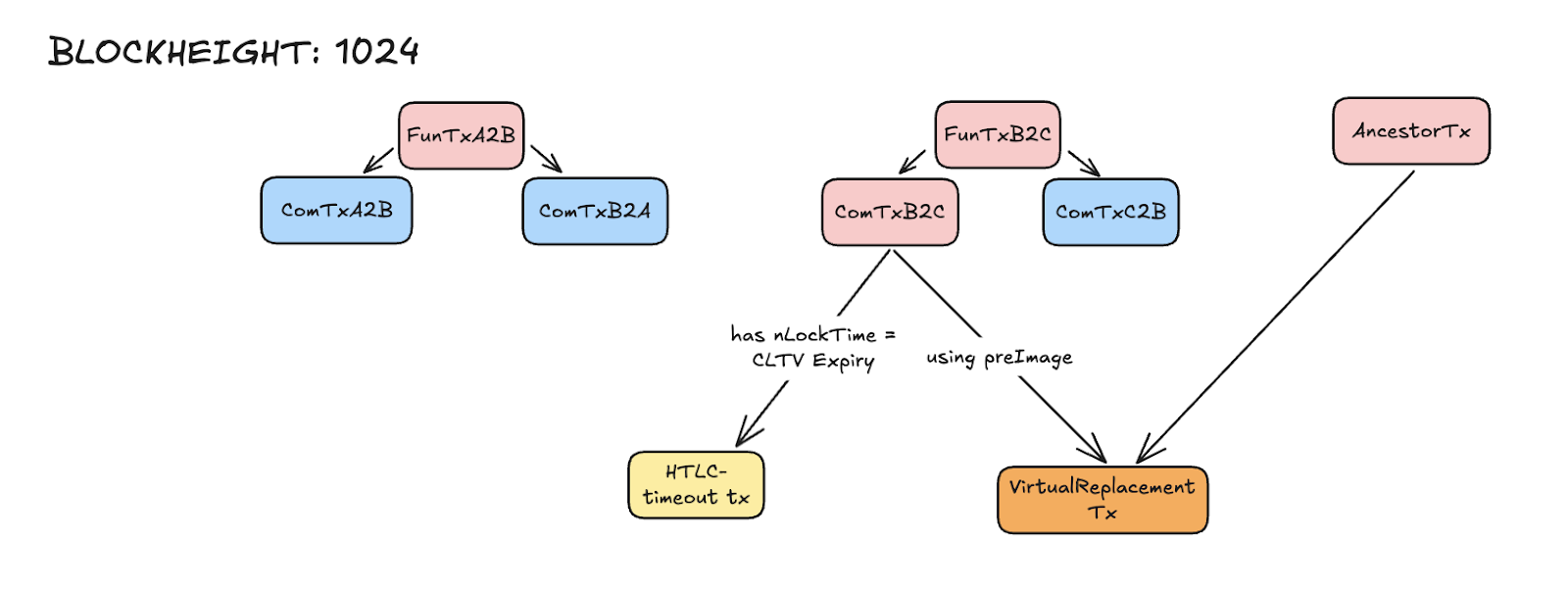
4. Block height 1024
`ComTxB2C` is confirmed.
Bob sees the confirmation and broadcasts his HTLC-timeout tx, which spends HTLC-B2C output.
Charlie waits for Bob’s transaction to appear at his mempool.
When it arrives, Charlie broadcasts a greater fee transaction using as input one output from `AncestorTx` and the HTLC-B2C output, now called `VirtualReplacementTx`.
As `VirtualReplacementTx` checks all rules of RBF [10], the HTLC-timeout tx that Bob broadcasted is successfully replaced from mempools. Therefore can not be confirmed and even though Bob unilaterally closed the channel, can’t get his funds.
Previous block confirmation and a successful replacement of Bob’s transaction, the attacker Charlie replaces the `VirtualReplacementTx` with a new transaction `AncestorTx-{N-1}` that costs more fees than `VirtualReplacementTx`. Therefore, the HTLC-B2C output remains unspent.
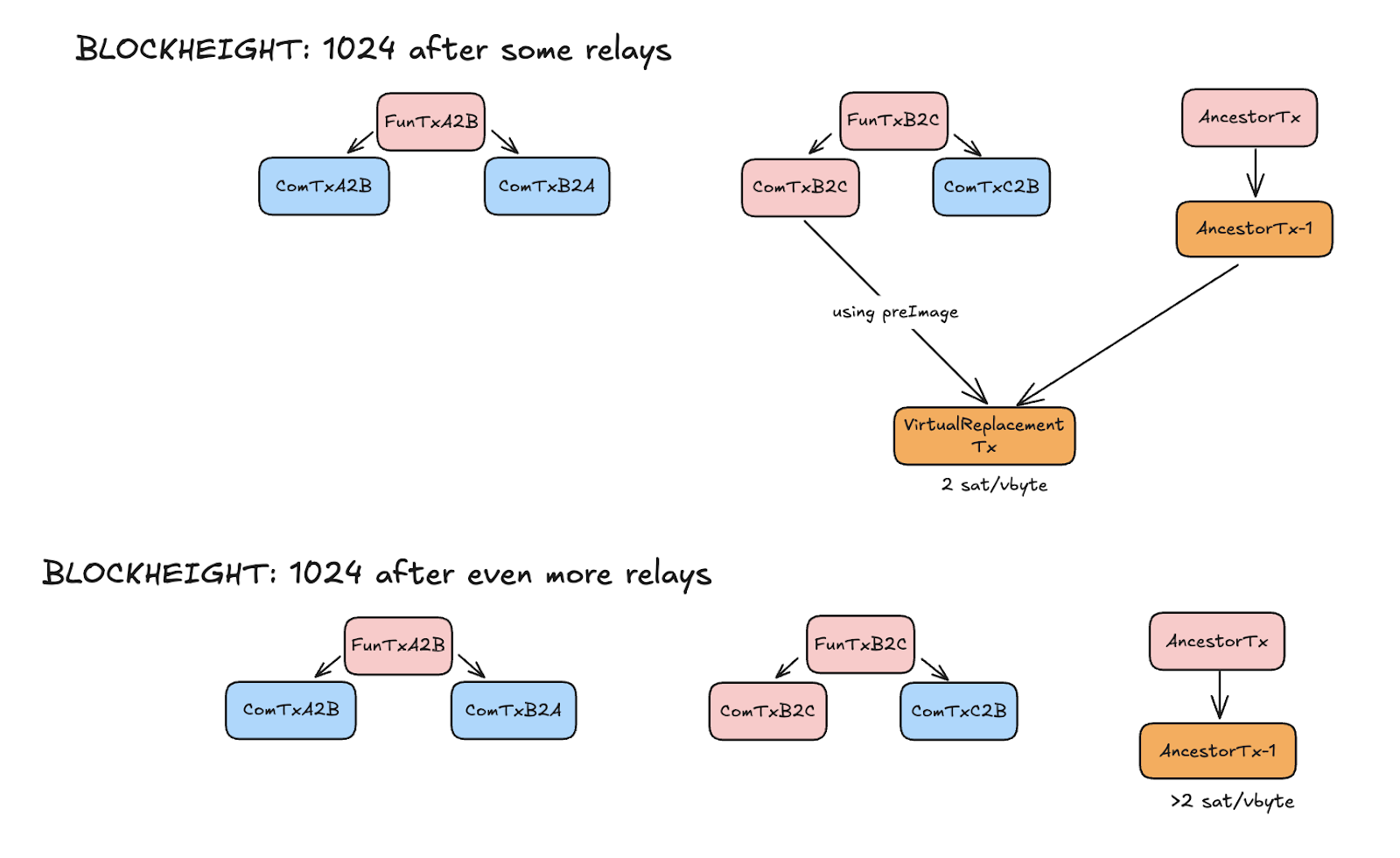
5. Block height 1024+N…1079
`AncestorTx-N-1` is confirmed
All items from step 4 (block height 1024) are repeated.
Charlie broadcasts a `VirtualReplacementTx` that replaces Bob’s transaction. Then, broadcast an `AncestorTx-{N}` transaction that replaces the virtual one.
* Note: `AncestorTx` must have at least the same amount of output as the CLTV_EXPIRY delta. For each block Charlie will spend one of these outputs for the replacement process. Each replacement process miners collect fees from the attacker. The attacker can replace the transaction for all this time because the preimage condition still can be used.
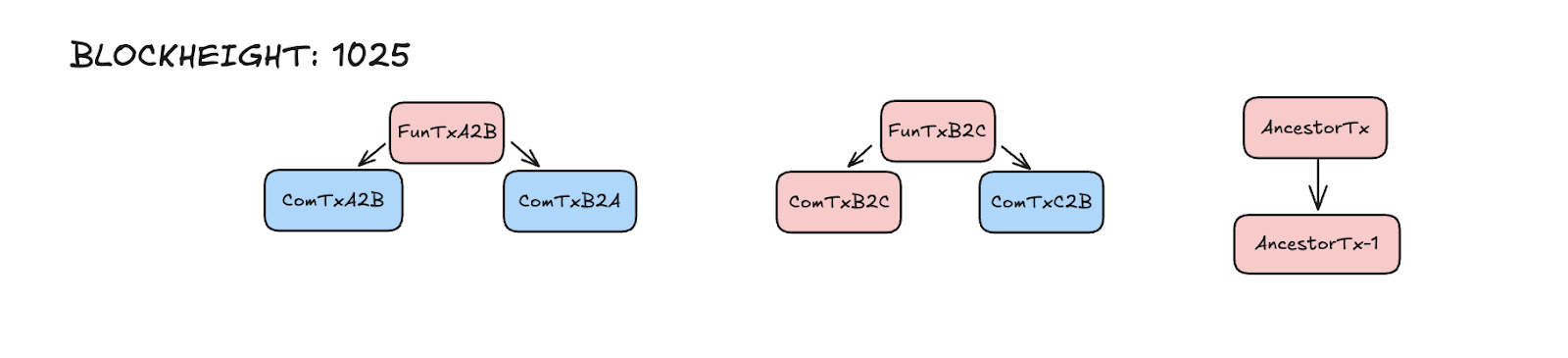
6. Block height 1080
Alice broadcast `ComTxA2B`, closing her channel with Bob
* Note: I’m assuming a modified implementation to do it just in block height 1080 and
not using the previously explained delta blocks.
7. Block height 1081
Alice spends the HTLC-A2B output using her HTLC-timeout tx, retrieving all her channel and HTLC funds.
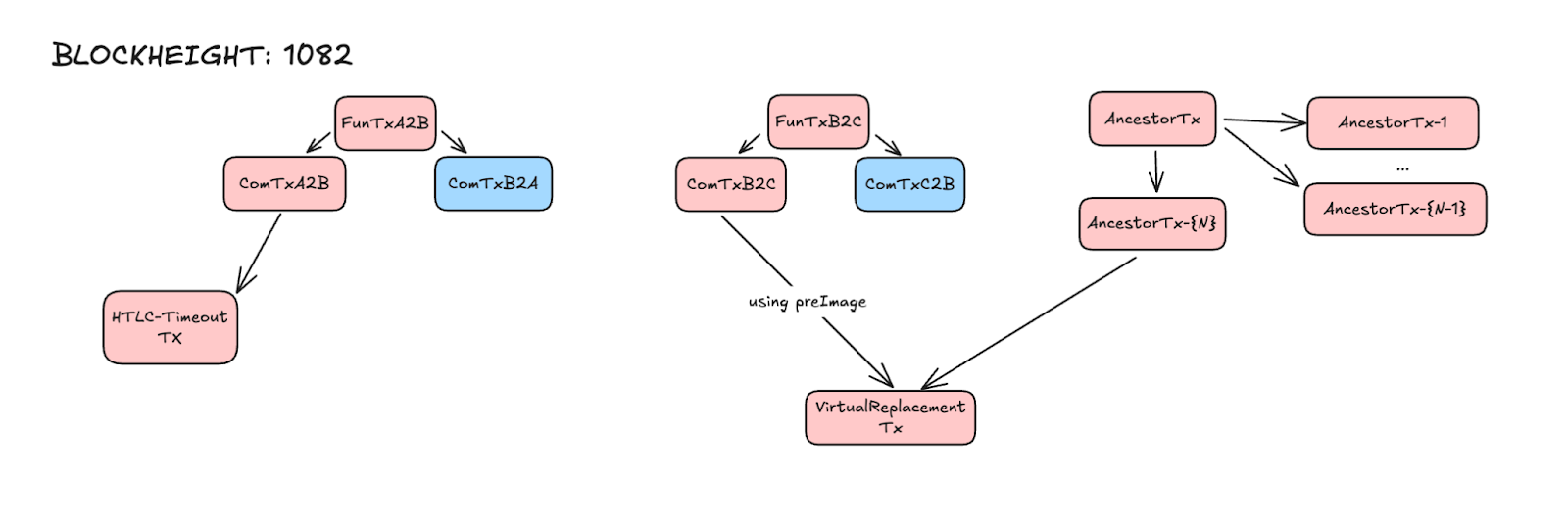
8. Block height 1082
8. Block height 1082
Charlie finally does not replace the `VirtualReplacementTx` with an `AncestorTx-{N}`. Getting the HTLC funds.
* Note: Charlie did the replacement cycle until this block. If he broadcast and got the `VirtualReplacementTx` confirmed, Bob could get the pre-image and get his funds from the HTLC-A2B output that was locked until block 1080.
By the end of this exercise, network participant had the following conclusion:
- Alice got her 1 BTC back
- Bob lost 1 BTC
- Charlie got 1 BTC
In other words, the attacker stole 1 BTC and the victim lost 1.
Miners collected fees from all the confirmed transactions, that actually were many.
What is the real issue here
The previous timeline consisted in the race condition of who gets to spend the HTLC out first, through the pre-image path or the timelock one. But if a malicious actor bribes (or just forcefully convinces) miner(s) to pin the transaction of the victim, the attack can also take place, even without that many replacements.
In other words, as Peter Todd points out in the mailing list [11] , the problem here is that after the HTLC-timeout path becomes spendable, the HTLC-preimage path remains spendable.
We need to find solutions to this issue.
Proposed and implemented mitigations
Antonie Riard in his paper proposed five mitigations related to mempool monitoring and how the HTLC-timeout transaction is rebroadcasted [8]: Local Mempool and transaction relay traffic monitoring, miner mempool monitoring, defensive fee broadcasting, aggressive broadcasting and per hop packet delay bumping. All of them, attempt to mitigate the issue doing either:
- Trying to win the race
- Trying to make the race not worthwhile.
Some of them, local-mempool and aggressive rebroadcasting, were implemented by the different node implementations to fix this issue.
Next, I’ll do a summary of each mitigation.
Local-Mempool and transaction-relay traffic monitoring
*Already implemented by LND and Eclair Implementations*
In our example, whenever Charlie broadcasted the `VirtualReplacementTx` spending the HTLC output funds, needed to use the pre-image condition of the script, effectively exposing the preimage in the mempool. If the victim (Bob) where to be monitoring transactions broadcasted, could retrieve the pre-image from the `VirtualReplacementTx`, and use it to unlock funds from the Alice channel. Mitigating the attack.
Even though this works well in practice, an attacker could be sophisticated enough to bypass this solution using a mempool partitioning attack. First the attacker must know to which Bitcoin node the victim connects to. Then, generate two transactions with the same fee rate and absolute fee, one is broadcasted to the victim node and the other to the rest of the network. They won't replace each other, because the absolute fee of the transaction is the same, then, not replacing the transaction in the local mempool. The victim won't know that is being attacked.
Miner-mempool monitoring
*not implemented*
Introduce a new network of transaction-relay between LN nodes and miners.
It would actually work the same as local-mempool, but instead of consulting your own node, you would consult miners' mempool.
This has even more issues than the local one as LN and the miner, attacker could do mempool-partitioning to the specific miner, or could explode a DDOS attack to it (or the connection of this network) and miners would have incentives to even charge for this premium service.
Aggressive Rebroadcasting
*Implemented Eclair, Core-lightning, LND and LDK*
Nodes rebroadcast the HTLC-timeout transaction randomly on every block. So the possible attacker has to be the one reacting from the mempool and not the victim.
Defensive fee rebroadcasting
*not implemented*
The attacker spends fees everytime it successfully replaces a transaction, “worst case for Charlie”, one per block. If fees spent for the attack are greater than the amount to be stolen, there is an economic disincentive.
With anchor channels the absolute fees to be collected can be adjusted. If the victim adjusts the absolute fee, the attacker must pay in N blocks the total amount of the HTLC.
Mempools are dynamic and spikes could happen, giving the attacker a window of a few blocks where the attack can be performed without spending fees. Meaning that this adjustment could have a difference of a few blocks, where the attacker can take advantage of it.
Per-hop packet delay bumping
More CLTV Expiry delta means more time for the attack to be happening. Therefore, more fees and more likely the attack to fail.
As I said before, all mitigations concentrate on if the race condition is worthwhile or how to win it. But why don’t we want races in the Lightning Protocol?
Why we don't want races in Lightning Protocol
Every time there is a dispute or want to *end a relationship*, nodes go on-chain. Both cases depend on what the contract between the parties says. I think anyone can see a problem with the "whoever comes first, was right" type of contract. Incentivises cheating. Also makes it so whoever has more capital (therefore, better machine or connection) will probably end up winning.
Finally, and what I really don't like as much, incentives are to go on-chain to be **always sure** in any possible scenario.
So, better contracts == better infrastructure
So what to do?
Niftynei pointed me out that there is a possible, magical, solution proposed from Peter Todd in the mailing list and that also did a talk recently in BTC++ [11] [12]
OP_EXPIRE enters the scene.
My goal is to build a prototype demonstrating the usefulness of this opcode to the lightning protocol, through a proposed patch to bitcoin-core and the required updates to the lightning spec and CLN, to demonstrate how the softfork proposal is useful for resolving HTLC timeouts off chain.
OP_EXPIRE, AKA, OP_ANTICHECKLOCKTIMEVERIFY, is actually quite beautiful and lets us build better contracts so node implementations don’t need to go on-chain to be sure that funds are safe.
As the name says, it lets a branch or the script expire after certain block or delta blocks. This means that the HTLC-preimage branch would expire after a delta, previously negotiated, amount of blocks, making it an urgent thing. Now after a certain amount of block an HTLC is not returned, the channel wouldn’t need to be closed, implementation would need to make the HTLC-preimage become not spendable to return the error back to the network.
If someone has a problem, it wouldn't mean chaos on-chain given automatic unilateral closures.
If you see your peer down and you want to really want to close the channel, you would manually (or programmatically) take action and not be part of the protocol.
We can see the changes on the script here (extracted from Elle Mouton blog [6]):
Current offering HTLC
# To remote node with revocation key
OP_DUP OP_HASH160 <RIPEMD160(SHA256(revocationpubkey))> OP_EQUAL
OP_IF
OP_CHECKSIG
OP_ELSE
<remote_htlcpubkey> OP_SWAP OP_SIZE 32 OP_EQUAL
OP_NOTIF
# To local node via HTLC-timeout transaction (timelocked).
OP_DROP 2 OP_SWAP <local_htlcpubkey> 2 OP_CHECKMULTISIG
OP_ELSE
# To remote node with preimage.
OP_HASH160 <RIPEMD160(payment_hash)> OP_EQUALVERIFY
OP_CHECKSIG
OP_ENDIF
OP_ENDIF
New offering HTLC
When going to remote or pre image, after specified blockheight the script would fail, leaving only the first two branches as possible way to unlock the funds.
# To remote node with revocation key
OP_DUP OP_HASH160 <RIPEMD160(SHA256(revocationpubkey))> OP_EQUAL
OP_IF
OP_CHECKSIG
OP_ELSE
<remote_htlcpubkey> OP_SWAP OP_SIZE 32 OP_EQUAL
OP_NOTIF
# To local node via HTLC-timeout transaction (timelocked).
OP_DROP 2 OP_SWAP <local_htlcpubkey> 2 OP_CHECKMULTISIG
OP_ELSE
# To remote node with preimage that expires on expire block height.
<expire block height> OP_EXPIRE OP_DROP
OP_HASH160 <RIPEMD160(payment_hash)> OP_EQUALVERIFY
OP_CHECKSIG
OP_ENDIF
OP_ENDIF
How could it be implemented?
- Coinbase Bit: modify the nVersion to enable transactions to have tx outputs to be spendable like the coinbase transaction output.
- Delta encoding expiration: encodes the a delta expiration in the nVersion that applied to the nLockTime, acts like a new factor “AbsoluteExpireHeight” to be checked as the OP_CLTV.
- Taproot Annex: use the annex as nExpiryHeight that would work as the same of the “AbsoluteExpireHeight”.
I took the liberty to implement the second one.
All transactions using this op_code would need to use nLockTime greater than 0 and do not use sequence_final.
We take the first 16 bytes of the nVersion field of the transaction (now nDeltaExpireHeight), this would signal the maximum delta of all OP_EXPIRE in scripts inside the transaction from the nLockTime field.
So the actual script takes the first element of the stack and compares it to the AbsoluteExpireHeight (nDeltaExpireHeight + nLockTime).
The script would fail then in the following cases:
- The stack is empty
- The top item on the stack is less or equal than 0
- The lock time type of the stack item is not block height
- The lock time type of the nLockTime is not height
- The top stack item is greater than AbsoluteExpireHeight
- the nSequence field of the txin is sequence_final
What 's on PART II?
- Testing new LN scripts on bitcoin-core and how the attack is mitigated
- Partial implementation in CLN
And the future?
Let’s build it together 🥳
Let’s build it together 🥳
References
- https://diyhpl.us/~bryan/irc/bitcoin/bitcoin-dev/linuxfoundation-pipermail/lightning-dev/2020-April/002639.txt
- https://github.com/t-bast/lightning-docs/blob/master/pinning-attacks.md
- https://en.bitcoin.it/wiki/Transaction_replacement
- https://bitcoinops.org/en/newsletters/2023/10/25/#replacement-cycling-vulnerability-against-htlcs
- https://ellemouton.com/posts/htlc/
- https://ellemouton.com/posts/htlc-deep-dive/
- https://lightning.engineering/posts/2023-06-28-channel-normal-op/
- https://gnusha.org/pi/bitcoindev/CALZpt+GdyfDotdhrrVkjTALg5DbxJyiS8ruO2S7Ggmi9Ra5B9g@mail.gmail.com/
- https://github.com/lightning/bolts/blob/master/02-peer-protocol.md#cltv_expiry_delta-selection
- https://github.com/bitcoin/bips/blob/master/bip-0125.mediawiki#implementation-details
- https://gnusha.org/pi/bitcoindev/ZTMWrJ6DjxtslJBn@petertodd.org/
- https://www.youtube.com/watch?v=HXnNRmhCpNM