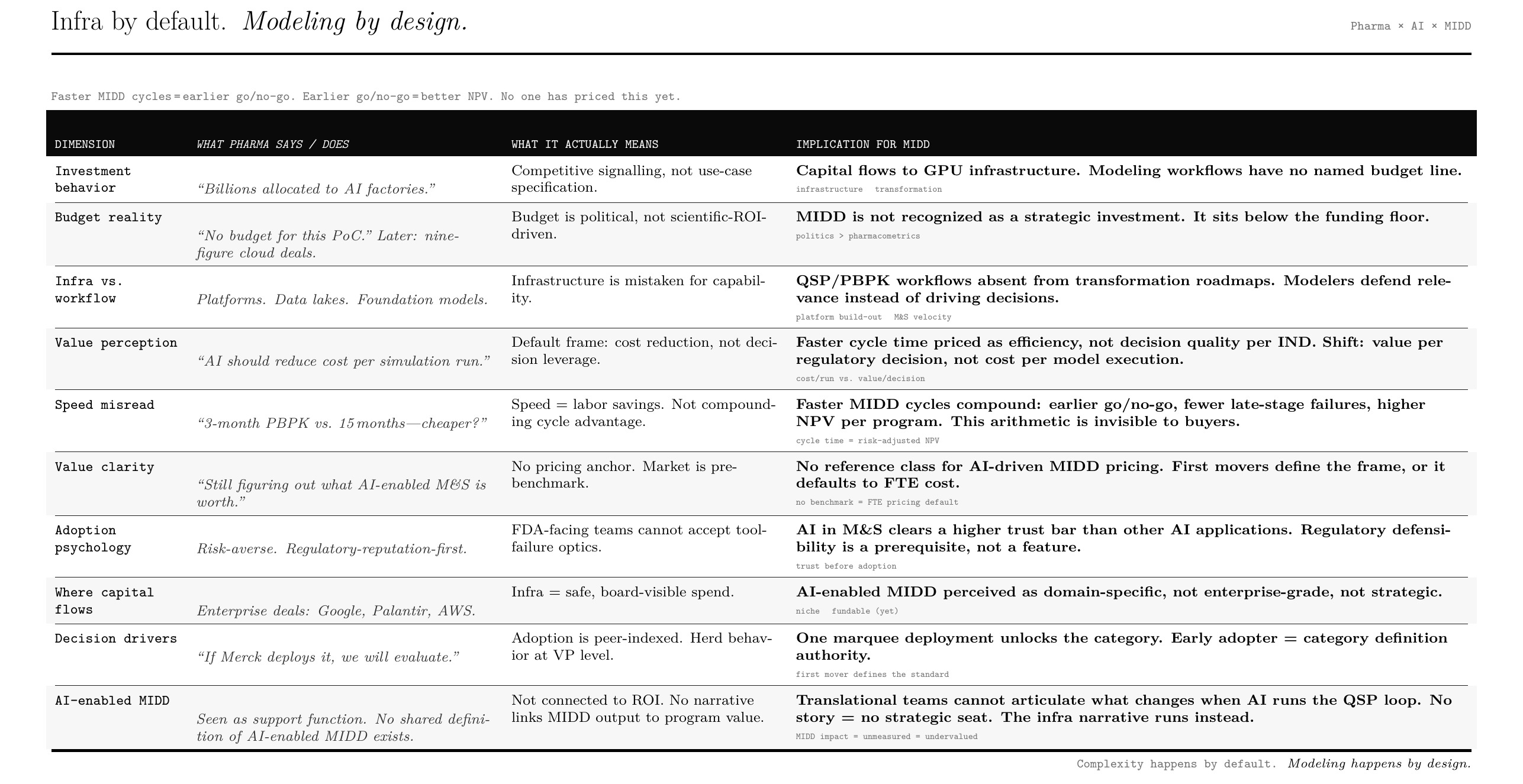
The Agentic Shift in MIDD: Verifying becomes the most valuable skill
The core mental model for Model-Informed Drug Development has been quite straightforward. It rewarded scientists who could build robust models, navigate complex datasets, and defend quantitative reasoning to regulators and development teams. The work has always blended deep domain expertise with technical expertise too. The fact is very visible in the history of modelling where the scientists have been great programmers too and they have undoubtedly built modelling tools and libraries that work at scale.
Now something fundamental is changing - a new class of systems is making the technical orchestration of modeling work dramatically cheaper and faster. Get a database, connect it to a dashboard- make AI extract differential equations from publications and then make it create the simulation engine. Very precise and personalised for this one question. It is possible to scale this personalization too- but that is a matter of discussion in anlother post.
What is more important is that the binding constraint is shifting. And for MIDD scientists, this is both an opportunity and a quiet crisis of relevance if we don’t adapt. And as of today- it is more a quiet crisis. Modellers across the domain are skeptical of its impact on their work and thus own their reservation on adopting the system- a lot of this skepticism is seen in the way their teams are making investment in AI in their organization as they are struggling with the gaps that are created by pharma investment in the AI infra (all the news about Eli Lilly, Roche, BMS, Sanofi, Novartis etc) and their real connection to the decisions that will be made by this.
How I see this?
What “Agentic” Actually Changes
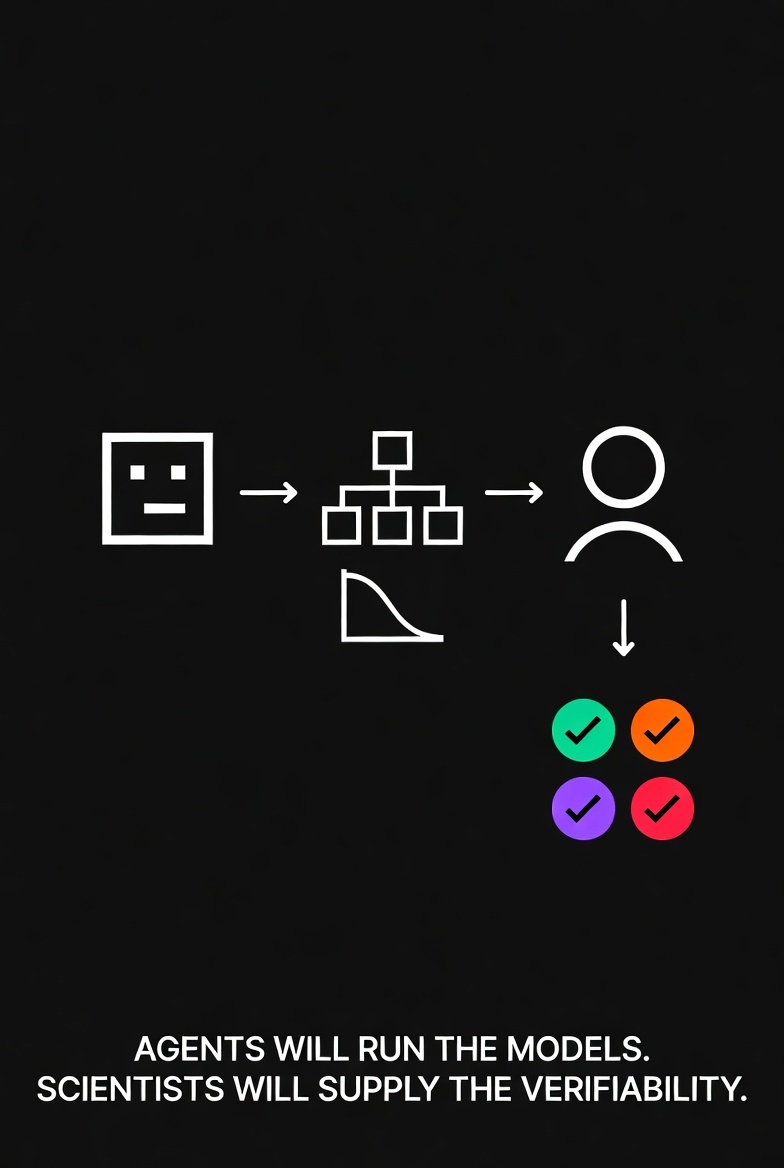
Most of us are familiar with traditional scripting or static pipelines: you define the steps, the inputs, the order, and the script executes. If the data format changes or an unexpected issue appears, the pipeline breaks or produces silent errors. Agentic AI systems are different. They can inspect the actual data they receive, decide which tool or method is appropriate *at that moment*, execute it, evaluate the result, and sometimes adjust course - all while keeping a detailed record of their reasoning.
A striking real-world demonstration comes from bioinformatics researcher Manuel Corpas. He gave an agent access to ten unlabeled whole-genome files, including his own family’s data. The agent correctly identified all familial relationships by choosing and running the right kinship tool at runtime. It then moved on to polygenic risk scoring. On the first attempt, the results were sooo worng, pretty bad... but not extremely catastrophic, they were off by a factor of three - because the agent had mishandled missing data positions. The error was only discovered because Corpas compared the output against his own previously published, peer-reviewed benchmark. Once corrected, concordance reached 100%.
A similar trend is reported from NovoScribe activity.
The agent did the hard technical work. The scientist’s published benchmark caught the subtle but critical mistake.
This pattern will become common in MIDD. Agentic systems will increasingly handle data preparation, tool selection, initial model runs, sensitivity analyses, and even draft reporting. What they will not do reliably on their own is know when their output is subtly wrong in ways that matter for dose selection, trial design, or regulatory submissions and defense.
The New Way of working: Orchestration
When orchestration becomes cheap, verification is strategically vital.
there are a few ways to look at verifiability:
Research-grade: Does the output look plausible on the surface?
Cohort-grade: Does it hold up across different datasets, methods, and dose replicates?
Clinical-grade: Does it match independent ground truth with quantified, acceptable error rates?
Most current applications of agentic tools in our field sit at tier of research-grade and are inching toward tier two. Tier three - the level regulators and late-stage decisions require prospective benchmarks, external collaboration, and deliberate scientific design. Something that is outside the realms of competing. I think the future is to create a benchmarking consortia between the industries to mark the MIDD grading of what does a good and bad MIDD hypothesis mean?
This is not a technical problem to be solved by better prompting alone or by we did infrastructure changes. And it plays to the strengths of experienced MIDD scientists rather than replacing them.
What This Means for You as a MIDD Scientist
Whether you consider yourself technical or not, your highest-leverage contribution is moving upstream from execution to verification of the MIDD model choice and outputs.
Non-technical MIDD scientists often worry they will be left behind. The opposite is more likely. The scientists who will thrive are those who can:
Define what “acceptable” looks like for a given decision context
Curate or create trustworthy benchmarks (internal historical models, published literature, external datasets)
Design tiered validation processes matched to the stakes of the decision
Spot when an output is biologically or statistically implausible even if it looks clean
Insist on provenance, auditability, and human oversight where it matters
These are not new skills in spirit. What is new is the volume and speed at which candidate outputs will be generated. Without deliberate verifiers, that speed becomes a liability.
Practical Steps You Can Take Now
You do not need to become a prompt engineer or build agent infrastructure. You do need to treat verification as a first-class scientific activity:
1. Start a personal or team benchmark library. Every time you or your group produces a high-quality model or analysis, capture the inputs, assumptions, outputs, and any external validation. These become your reference standards.
2. Define validation tiers for common MIDD tasks. What constitutes research-grade versus cohort-grade evidence for a pediatric extrapolation? For a formulation bridging study? For a virtual population in QSP? Write it down.
3. Insist on verifiability. Any agentic workflow used in serious work should produce a clear, human-readable record of data sources, tools chosen, decisions made, and versions used.
4. Practice “falsification thinking.” This one implies in the traditional modelling thinking and should be used on both humans and machines. Before accepting an AI-generated result, ask: What independent check would most likely reveal if this is wrong? Then perform or request that check. Hold up the flag of "all models are wrong, only some are useful".
5. Collaborate on shared benchmarks. The field would benefit enormously from community or pre-competitive efforts to create validation datasets and frameworks for common MIDD use cases.
Agentic AI will not eliminate the need for MIDD expertise. It will eliminate much of the drudgery that currently consumes expert time. In its place, it creates a higher-stakes role: designing the guardrails, benchmarks, and verification processes that turn fast, powerful systems into trustworthy scientific equity co-partners.
The scientists who will have the greatest impact in the coming years are those who stop asking only “How do I get the model to run?” and start also asking “How will we know - quickly and defensibly - when the model of choice and the output even though it looks correct is wrong in the bigger story, and what standard of evidence is required for this decision?”
That is not a smaller role. It is a more scientific one. Thus, Agents will scale output. Modelers will scale trust.
P.S -> this image was a ton of fun, with Openclaw cursor use + grok + kegg
I wonder- a lot. So, I write my wonder here. What to expect? The chaos and curiosity that my being brings. As living a human life is not bound by definitions in the macros- the posts here will be spontaneous and identity-less! I like to give and create art. So if you buy an act of creating I will use it for things that I am passionate to give for. Obviously, a little support on my art will make me feel visible.
"Change. Change. Change. Change … change. Change. Chaaange. When you say words a lot they don't mean anything. Or maybe they don't mean anything anyway, and we just think they do."