Issue 12. 2021-05-30
前段时间事务繁忙,一周下来也看不了多少内容,就连平常每日翻阅的 RSS 也不能清空。于是把更新频率从每周五周更改到了暂定的月更,这样每次也能积累更多的材料,在短时间内就同一话题进行比较阅读。
这样的变动一定会导致一篇中的内容更多,于是我也考虑了如何把一期内容更好地分类。先前的分类方式我觉得大致可行,但同一话题(例如体育)又往往会横跨「项目」和「视频」两类。倘若按照话题去分类,则又会陷入话题和子话题的无尽漩涡之中。于是索性我就不再折腾这样的细枝末节。随性一点也许会更好,本来就只是一个个人的阅读记录(或许应该改为 A subset of an Internet archive 才更为贴切)。
- Where are the world’s airports? dataisbeautiful (reddit.com)
- 我不认为把经纬度变成点就算是完成了一个 beautiful 的项目,其实要考虑的有很多,比如过于密集的数据点其实没有太多的意义,1000 和 5000 的差别一定没有 1000 和 200 的 差别明显。另外,机场规模也可以作为一个考虑的维度:例如在巴布亚新几内亚🇵🇬的381座机场大多数是岛与岛之间的小机场,这些在图上与每日吞吐量巨大的国际机场并没有区别。如果对这个话题感兴趣的话,YouTube 有一个频道叫 Missionary Bush Pilot,经常执飞这些航线,景色宜人。

- Noise in Creative Coding | Varun Vachhar
- The hundred poles, Hamilton. (AFP) : formula1 (reddit.com) Lewis Hamilton 创纪录的第 100 个 F1 分站赛杆位可视化,虽然在 subreddit 中「广受好评」,而且作者的想法我能理解,但是大奖赛的排列顺序以及 label 的文字朝向实在让我不能理解:不是赛道的音序,也不是大奖赛所在国家的音序。我觉得真的有必要做一个「Data is beautiful, but I have unpopular opinion」的系列。
- How to plot XGBoost trees in R
推荐语:初学 R 时候日期 / 时间类型一直让我很头疼,lubridate 包解决了不少问题。这篇文章介绍了一个同样专注于处理时间类型的年轻的 R 包 clock 并将其和 lubridate 进行对比,clock 对异常处理更得当,运算支持更多数据类型(lubridate 只支持 R 原生的 Date 和 POSIXct 类),如果你对处理日期 / 时间数据有更高要求,不妨试试 clock。
- F1 Drivers Rated – Version 2 用基于发车车位的预计积分和实际积分的对比来衡量当前车手的表现。这有点类似于之前英超的 xG-based ranking vs real ranking. 数据应该是没有包含西班牙站的结果,所以根据他的模型,表现最为出乎意料的是 Lando Norris.
- Why nobody knows how to pronounce my name in Japanese - Datawrapper Blog 日语汉字两个难点:数量多,难记。中文汉字也是一样的。日本的九年义务教育(6-15岁)要求掌握的汉字数量是 2136 个,相比之下作者对比了希伯来语、希腊语等语言的 character 字数,相差的是数量级。当然我觉得这其实有点不妥了,本身语言体系不同,拉丁字母就那么几十个,能表意的也并非那些字母,而是组合后的单词。然后我还特意查了一下中国的九年义务教育所授汉字数量,并没有一个准确的数字出来,但多个来源都称是 3000 多个,我觉得这个数量应该是合理的。
- Americans Up and Moved During the Pandemic. Here’s Where They Went. - WSJ
- “Hey guys” as the most popular greeting in YouTube videos. 为什么有人会说「What is up」啊?
- An Interactive Editor for Viewing, Entering, Filtering & Editing Data • DataEditR (dillonhammill.github.io) DataEditR 这个 R package 可以使用户通过类似 Excel 的方式修改表单数据。
- Introducing Observable Plot / Observable / Observable (observablehq.com) 可以从 copy-paste 开始学习新技能了。
- Mastering Shiny (mastering-shiny.org) Hadley Wickham 的新书,旨在从零开始介绍 Shiny 的使用方法。5月底纸质版会上市,但是老规矩——全书会开源。有一本「必读」的书要列上各大学习书单了。
- Getting blue fingers | Percentile Radars/Pizza’s 虽然对于 pie charts 这个词有一定的负面情绪,似乎换个名字之后能缓解这种 debuff. 当然了,要说风玫瑰或者本文使用的 percentile radars/pizzas 本质上和传统饼图还是有着一定的差别的——表达数量多寡的不再是扇形弧度的大小,而是扇形本体的半径。这种可视化在体育数据分析文章中出现频率真的不低。The Athletic 之前在「寻找某某球员的替代者」这类文章的时候就喜欢拿出这种图找相似形状。
- The Good, the Bad and the Ugly: how to visualize Machine Learning data 可惜我看不懂德语 slides 中的内容。下面的代码倒是可以作为 cheatsheet 或者改写成自己的 snippets 以后随取随用。我一直觉得拥有自己风格 snippets 非常重要。
- More Americans Are Leaving Cities, But Don’t Call It can Urban Exodus
- Inside the numbers of Stephen Curry’s record-setting April scoring spree 本赛季是近些年来第二个「非正常」赛季,常规赛的排名不论东西部都与赛季前的预测有挺大的出入。当然,在这种未知因素众多的时间段内,预测本身还有意义么?Curry 已经拿下了常规赛得分王,这是继 MJ 之后年龄最大的得分王;四月的惊天表现居功至伟。两个发现:
- 目前历史前三的三分射手似乎都是在读完大学之后才进入联盟的。
- 在日历上表现比赛三分命中数,缺席的比赛用透明的点表示,可以叫做「smashing tomato plot」么?🍅🏀
- Do You Live in a Political Bubble? 这种把相同投票倾向的选民从地理上标记出来,从而看出「聚类」的现象叫做 political bubble. 所以之前的 Spotify’s most popular songs by geolocation 实际上就是这种小 bubble 的抽象表达。
- The Guardian 200: Unfinished business since 1821 《卫报》庆祝自己发行 200 周年做的专题,图文并茂的时间线。
- Getting Started with Generative Art in R 我之前也尝试用 attractor 做过一些:

- Statistical Atlas (flowingdata.com) Nathan Yau 从 2015 年开始的一个系列项目——用 1874 年美国第一本基于普查结果的地图册作为蓝本,用当代的普查数据去复刻当时的可视化风格。
- Watercolor Maptiles Website Enters Permanent Collection Of Cooper Hewitt Stamen Design 基于 OpenStreetMap 数据所制作的一套水墨绘图风格是我最为喜欢的地图风格。另外他们的 Toner 黑白色也非常好看。

- TidyX 是一个分享 TidyTuesday 项目录屏的 YouTube 频道。
- 无国界记者组织的 2021 年世界新闻自由指数报告:
- 4万份“尸检报告”曝光!死因:社会性死亡 (qq.com) 公众号 DATAMUSE 关于豆瓣小组「社会性死亡」的 EDA,颇为有趣。
- From Fonseca to Rangnick: using data to scout Tottenham’s next manager – The Athletic 之前 The Athletic 「寻找某某球员的替代者」之类的文章看得多了,对于衡量球员特点的变量也都有所耳闻,但是如何衡量一个教练的能力呢?诚然,奖杯多少、带队成绩可以笼统地具象为几个数字,但球队可能需要关注的更多是一种氛围性和渐进的变化。所以,什么样球教练才「合适」呢?文中用到了一位波兰的足球分析师 Piotr Wawrzynow 的方法:Profiling Coaches with Data – Analytics FC.
- The Data Journalism Podcast Alberto Cairo 和 Simon Rogers 的一档播客节目。如其名,data + journalism.
- JesseVent/crypto: Cryptocurrency Historical Market Data R Package (github.com) 一个可以调取虚拟货币历史价格数据的 R 包,省去写爬虫或者使用各大交易平台 api 的时间。
- Finding Messi-esque dribblers and making choices while clustering (letterdrop.com) 来了来了,又是一篇「给球员找相似」的文章。不过这次侧重的则是 Messi 的盘带。作者刻意避开了「盘带区域」,精简了变量数量,然后做了 k-means clustering. 总体来说感觉做的不是很成功。
- World Map 31203 (lego.com) LEGO 新推出的世界地图。最近 LEGO 的这种「圆片」艺术拼图往往都是一套能品出多(四)种样式的,当然也鼓励用户多买多拼,挂在墙上。只是不知道这张一万多个零件的世界地图,在各位有创意的艺术家手里又能折腾出什么新花样。
- 10 Tips to Customize Text Color, Font, Size in ggplot2 with element_text() - Python and R Tips (cmdlinetips.com) 之前我在 issue 1 和 issue 8 都提到过 Dr. Cédric Scherer 关于 {ggplot2} 的技巧分享,很是受用。但我个人感觉其中最为有用的内容无疑是 element_text()function 的运用。这类用法上的东西,除非很高频率地使用,否则真的很有必要自己准备一个顺手的 cheatsheet 能够随取随用。
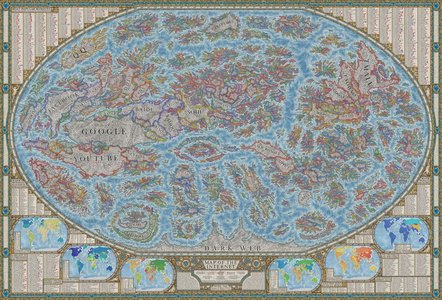
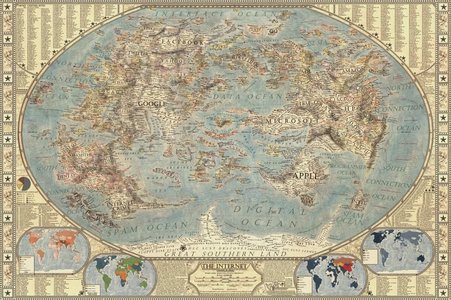
- Map of the Internet — Halcyon Maps 来自 jsongal 的推荐。专业绘图师所绘制的一张有趣的「互联网地图」。总感觉自己在哪里看过,直到浏览到他们商店售卖的产品,才发现早在 2014 年 Halcyon 就已经做过同一主题的地图。相隔七年,互联网世界「造陆」明显。
- 有意思的是,地图中「国家与国家」的相邻关系更多是产品功能上相似度,而非公司之间的持股关系。换句话说,图中的网站以功能聚类。
- 同一个网站/国家中,还会列出一些关键词,充当「城市」。
- How To: Hex-Styled Snowflake Charts - The F5 (substack.com) 呈现的结果看似简单,但是清洗数据并将其归类到对应坐标的六边形中不是件容易的事。

- hoopR (saiemgilani.github.io) 一个支持 play-by-play 篮球数据的 R 包。省却与 Basketball Reference 打交道的麻烦。
- Visualizing Incomplete and Missing Data | FlowingData 数据清洗中对于缺省数据的处理不是什么新鲜话题了,但是到了可视化的这一步如果仍要面对缺省数据,应该如何操作?
- Measuring Freedom by Swaminathan Nanda-Kishore | Medium 作者用自创的 Freedom Rating 作为衡量指标,可视化出足球运动员在场上的「自由」程度。足球经营模拟类游戏一般都会对球员在战术中扮演的角色有相应的指令。例如,你是希望一个边后卫「坚守位置」更加注重防守,还是「自由发挥」从边路插上助攻?作者考虑的参数是:接球位置。但我想补充的一点在于,接球位置和场上的战术定位有关系,所以对于 FR 的衡量是否要分整个赛季和单场比赛的区别?例如文中所举例的 César Azpilicueta,他在左右边后路接球的位置更多是与该场比赛所出任的位置有关,尽管从赛季的角度来看他的跑位非常自由。
- VR Data Visualization Learnings from the Place Viewer - YouTube 从 VR 的视角去看当年 r/place 的那场著名社会实验。

- Strava Global Heatmap 最近开始重新拾起跑步的习惯,也斥「巨资」加入了 Garmin 的使用者行列。不得不说,在运动手表行业,有着多年手持 GPS 设备生产经验的 Garmin 真的功能强大。每次跑完回来都能收集到一屏幕的各种数据,dashboard 呈现先不谈好看不好看,但总有着满满的成就感。而成就感,是能促进习惯养成的。巧合的是,两周前的 The Process 邮件中,Nathan Yau 用 Strava 提供的 global heatmap (for running/cycling) 作为例子说明有时候数据没有展现的,很可能和数据所揭示出来的信息一样多。Strava 的例子「只」展现出它的 app 用户的使用场景,换句话说其实也就是中产阶级的居住地点可视化;Nathan 进而提到了他在 2014 年做的类似尝试,则是太过于泛化这一类跑步的 GPS 数据。
With so much data available, it’s easy to get excited about what we can see (and rightfully so), but it’s also easy to forget that data always has its limitations.
另外,我在整理本篇的时候,忽然有了改写所引用文章标题的想法——有的时候直接照搬文章原标题并不那么合适,尤其考虑到我本身是在拿中文写作。大致做一个类似于湾区日报的修改,下次开始。🌉