之前练手的 {tarantino} 包通过提交并入选了本周的 R Weekly。上周末写了一篇博文,把 understat.com 的公开数据拎出来做项目,写了一篇大体思路的博文 Visualize expected goals.
有一个想法:如果成品是一张以图片呈现的、不太再乎复现能力的可视化,完全可以用 Figma 这样的设计软件来完成最后一步的打磨。
项目
- Coronavirus Variant Tracker: where different strains are spreading (axios.com) 美国境内病毒🦠变种的分布。
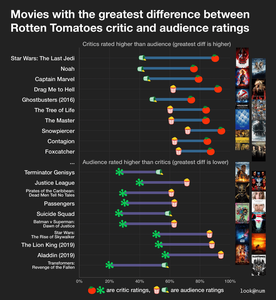
- Movies with the greatest difference between Rotten Tomatoes critic and audience ratings (reddit.com) 非常简单直白的一张 dumbbell graph, 但是执行得却非常出色。
- Get out of your geographic music bubble (pudding.cool) 上周更新过数据的 The Cultural Borders of Songs (pudding.cool) 这周又有了大变化,增加了 storytelling.
观点
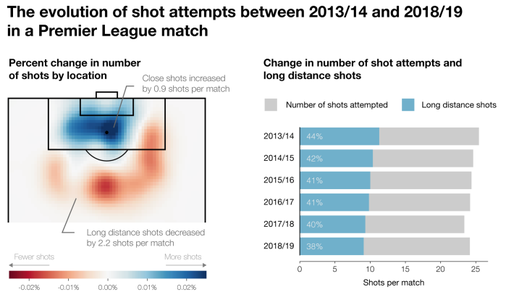
- Is Soccer Wrong About Long Shots? | FiveThirtyEight 如果唯数据论影响到了球员场上的决策,就对竞技运动是一种伤害了。现有的 xG 模型还是过于简单化球场上的情势了——同样的射门位置,大家都知道 Arjen Roben 带球蹚两步之后打门更有威胁。很简单,助跑后既能摆脱防守球员的覆盖,又能有更大的射门力量。
故事
工具
- ggplot2 extensions (tidyverse.org) 虽然大多数时候都是「有需要解决的问题,再去找工具」,但有时候看一下这种罗列了一众工具但 toolbox, 也可以拓宽一下视野。
- Create a Collection of tidymodels Workflows • workflowsets Max Kuhn 的一个全新 R 包,可以将多个 preprocessors 和 models 排列组合并相互比较,形成一个完整的工作流,并且可以对其进行调节。当然,{workflows} 也与他之前的 {tidymodels} 相兼容。
- Querybook Pinterest 的大数据 IDE 开源了。
播客
- Episode 07: How to Annotate Like a Boss! Featured Viz by Susie Lu — Data Viz Today 周末的时候尝试复刻了一下 understats 上每场比赛的 xG 分析,其中让人比较头昏的一点是在图上做注解。正好这周听到 Data Viz Today Episode 7 的节目,就是在讲如何给可视化做合理的 annotations.
书籍
- Tidy Modeling with R (tmwr.org) Max Kuhn 和 Julia Silge 关于 tidyverse 下统计模型选择的一本新书,开源。
- 附有 GitHub repo: tidymodels/TMwR: Code and content for “Tidy Modeling with R” (github.com)
- 另外关联推荐一下 Max Kuhn 的上一本书 Kuhn, M, and K Johnson. 2013. Applied Predictive Modeling. Springer.
数据
- psychbruce/ChineseNames: 🀄 Chinese Name Database (1930-2008) (github.com) 1930-2008 年中文姓氏和名字的数据库,已经打包成了 R 包。