Hey everybody,
Following on the previous post about Random Features [https://world.hey.com/decurtoidiaz/random-features-revisited-dl-meets-kernel-methods-57990072], I give some emphasis here on a follow-up work that we mainly developed while working at Carnegie Mellon and CUHK and that generalizes the main ideas of using Random Kitchen Sinks as a proxy for kernel methods.
Doctor of Crosswise: Reducing Over-parametrization in Neural Networks.
https://arxiv.org/pdf/1905.10324
https://github.com/curto2/dr_of_crosswise
Dr. of Crosswise substitutes common products matrix-vector in the architectures of Neural Networks by the use of simplified one dimensional multiplication of tensors. Namely, it establishes a framework of learning where learned weight matrices are diagonal and optimized weights are considerably reduced. We introduce a new operation between vectors to allow for a fast computation.
We build on these ideas to pioneer a framework of DL where the formalism used entangles matrices diagonal.
Again, this shouldn't be necessary but please *do* cite the paper if you find the publication or the code useful for your research.
Following on the previous post about Random Features [https://world.hey.com/decurtoidiaz/random-features-revisited-dl-meets-kernel-methods-57990072], I give some emphasis here on a follow-up work that we mainly developed while working at Carnegie Mellon and CUHK and that generalizes the main ideas of using Random Kitchen Sinks as a proxy for kernel methods.
Doctor of Crosswise: Reducing Over-parametrization in Neural Networks.
https://arxiv.org/pdf/1905.10324
https://github.com/curto2/dr_of_crosswise
Dr. of Crosswise substitutes common products matrix-vector in the architectures of Neural Networks by the use of simplified one dimensional multiplication of tensors. Namely, it establishes a framework of learning where learned weight matrices are diagonal and optimized weights are considerably reduced. We introduce a new operation between vectors to allow for a fast computation.
We build on these ideas to pioneer a framework of DL where the formalism used entangles matrices diagonal.
Again, this shouldn't be necessary but please *do* cite the paper if you find the publication or the code useful for your research.
Dr. of Crosswise
Doctor of Crosswise: Reducing Over-parametrization in Neural Networks.
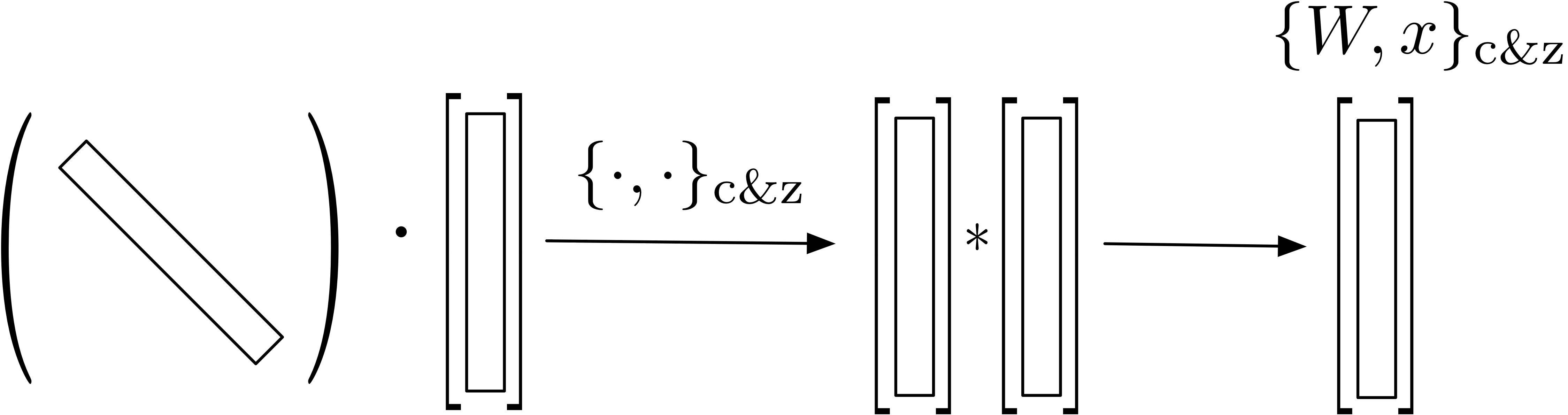
If you find this example useful, please cite the paper below:
@article{Curto19,
author = "J. D. Curt\'o and I. C. Zarza and K. Kitani and I. King and M. R. Lyu",
title = "Doctor of Crosswise: Reducing Over-parametrization in Neural Networks",
journal = "arXiv:1905.10324",
year = "2019",
}To run the code, enter the given folder and run:
$ pip3 install -U scikit-learn $ python c_and_z.py
File Information
- c_and_z.py
- Toy example demonstrating the use of the newly developed operand. A network motivated by McKernel is used. Weights are kept random, for simplicity.
Best regards,
De Curtò i DíAz.