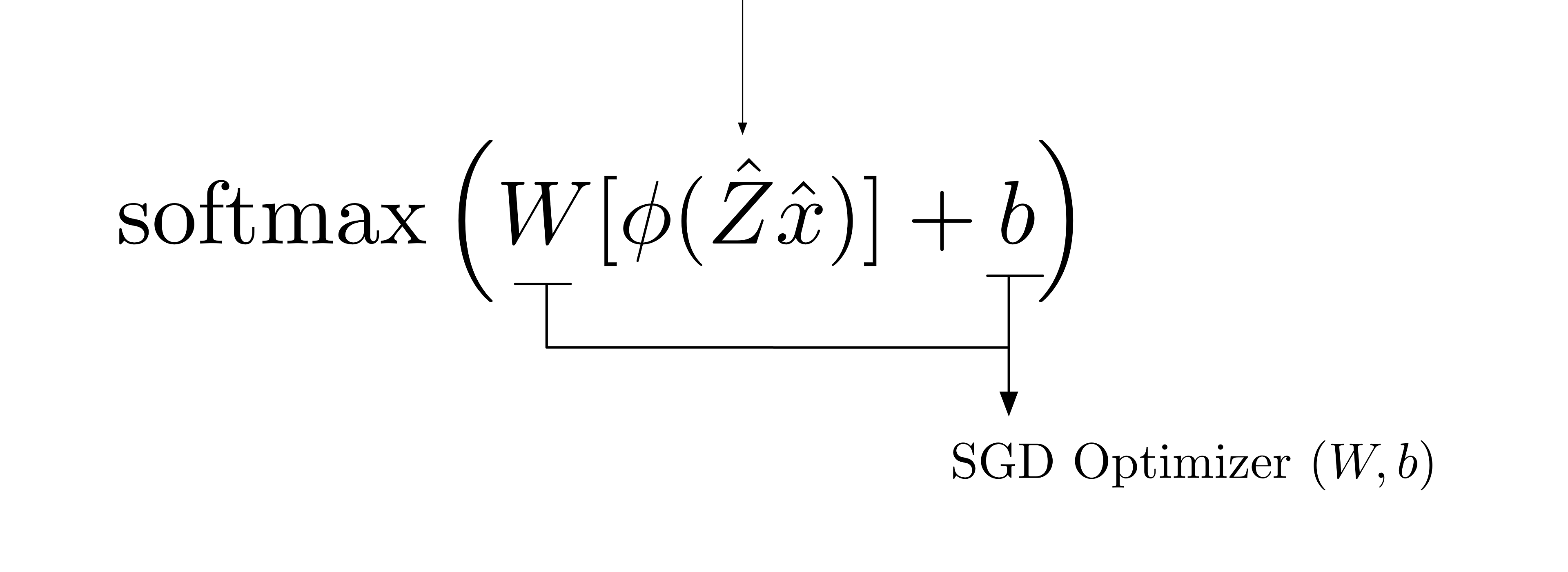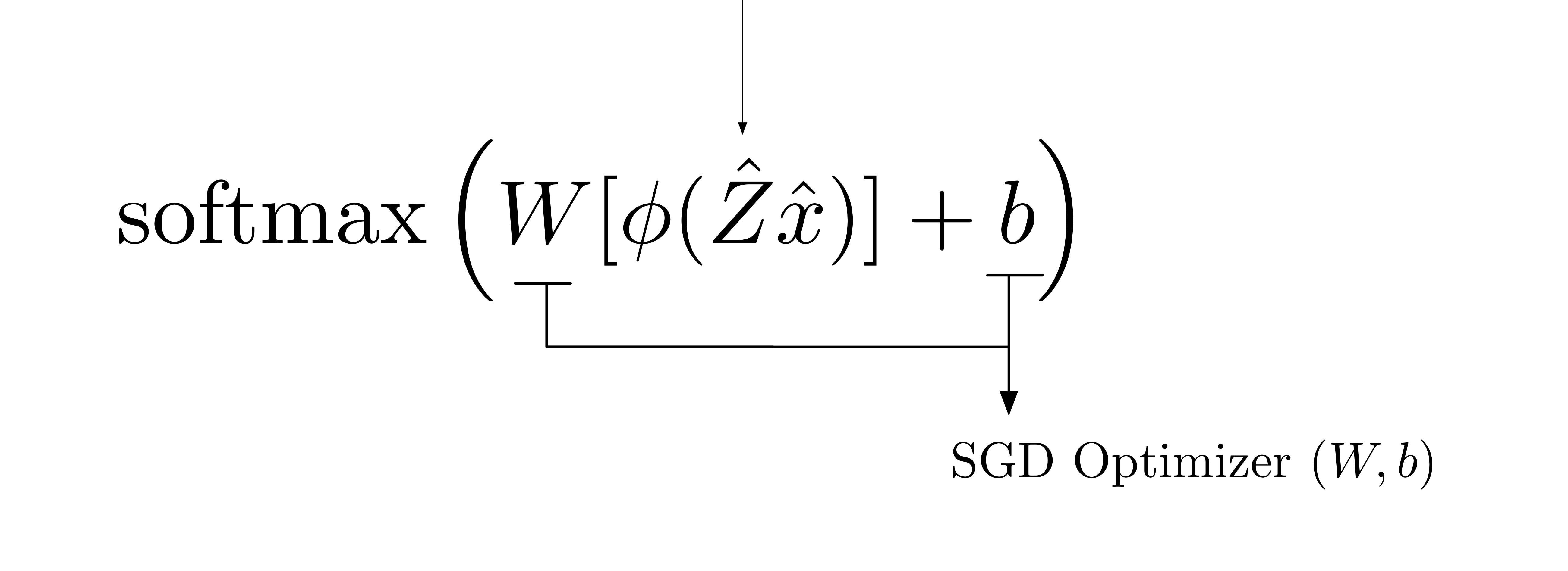"Random Features revisited: DL meets Kernel methods"
Hey everybody,
Following on an earlier post (https://world.hey.com/decurtoidiaz/hadamard-13de8cdc), where I introduced the use of the Hadamard as a stand-alone routine, I give further attention here at the work that I developed as part of my master thesis at City University of Hong Kong and Carnegie Mellon [1] back in 2014.
The work was developed in collaboration with I. de Zarzà i Cubero [2], who was also a master student in the EE Department at City University of Hong Kong; both were in the same joint program with the School of Computer Science at Carnegie Mellon where we pursued 12/30 credits of the program in Pittsburgh during two semesters (summer 2014 at the Robotics and Fall 2015 at the ML Department). The main derivate products from the dissertation are McKernel and C&Z dataset that appeared on subsequent publications.
McKernel aims to unify DL and Kernel Methods by providing a framework that gives a theoretical explanation by the use of FOURIER features. This was at the time of publication one of the first approaches (if not the first) to propose such an intend successfully.
C&Z is a bias-free dataset that was one of the first in 2014 (if not the first) to raise attention to the fact that learning methods had an implicit bias that we should be very careful about. Furthermore, we enhanced the dataset with HDCGAN (state-of-the-art method in synthetic image generation) generated samples in 2017, being the first dataset artificially augmented (many authors followed this approach afterwards).
I shouldn't need to do this but from my past experience is necessary to stress it out; please if you find the publications or the theses useful for your research please *do* cite them.
McKernel introduces a framework to use kernel approximates in the mini-batch setting with Stochastic Gradient Descent (SGD) as an alternative to Deep Learning.
The core library was developed in 2014 as integral part of a thesis of Master of Science [1,2]. The original intend was to implement a speedup of Random Kitchen Sinks (Rahimi and Recht 2007) by writing a very efficient HADAMARD tranform, which was the main bottleneck of the construction. The code though was later expanded at ETH Zürich (in McKernel by Curtó et al. 2017) to propose a framework that could explain both Kernel Methods and Neural Networks. This manuscript and the corresponding theses, constitute one of the first usages (if not the first) in the literature of FOURIER features and Deep Learning; which later got a lot of research traction and interest in the community.
More information can be found in this presentation that the first author gave at ICLR 2020 iclr2020_DeCurto.
One of the first datasets (if not the first) to highlight the importance of bias and diversity in the community, which started a revolution afterwards. Introduced in 2014 as integral part of a thesis of Master of Science [1,2]. It was later expanded by adding synthetic images generated by a GAN architecture at ETH Zürich (in HDCGAN by Curtó et al. 2017). Being then not only the pioneer of talking about the importance of balanced datasets for learning and vision but also for being the first GAN augmented dataset of faces.
The original description goes as follows:
A bias-free dataset, containing human faces from different ethnical groups in a wide variety of illumination conditions and image resolutions. C&Z is enhanced with HDCGAN synthetic images, thus being the first GAN augmented dataset of faces.
14,248 cropped faces. Balanced in terms of ethnicity: African American, East-asian, South-asian and White. Mirror images included to enhance pose variation.
Subset of 16,222 samples from the corresponding folders above that are correctly classified as faces given the default parameters of opencv.
File Information from graphics
Samples (graphics/samples/)**.
14,248 cropped faces. Balanced in terms of ethnicity. Mirror images included to enhance pose variation.
Labels (labels/c&z.csv and labels/c&z.p).
CSV file with attribute information: Filename, Age, Ethnicity, Eyes Color, Facial Hair, Gender, Glasses, Hair Color, Hair Covered, Hair Style, Smile and Visible Forehead. We also include format Pickle to load in Python.
Code (script_tensorflow/classification.py and generate_subfolders.py).
Script to do classification using Tensorflow.
Script to generate adequate subfolder of specific attribute. Useful to load into frameworks of Machine Learning.
HDCGAN Synthetic Images (graphics/hdcgan/).
4,239 faces generated by HDCGAN trained on CelebA. Resized at 128x128.
Additional Images (graphics/extra/samples/, labels/extra_c&z.csv and labels/extra_c&z.p)**.
3,384 cropped faces with labels. Ethnicity: White.