Disasters I've seen in a microservices world, part II
When I first wrote about microservice disasters, I thought we'd eventually "solve" them, with better tooling, frameworks, and operational maturity. We didn't. We just learned to live with the chaos. Distributed systems will always surprise you: timeouts, retries, and fallacies don't disappear; they just shift shape. Maybe that's the real lesson: software engineering isn't about eliminating uncertainty, but managing it gracefully.
Being part of the Runtime team at Adevinta, building an internal Kubernetes-as-a-service for the rest of the company, gave me a perspective on all the things software engineers build atop distributed systems. After all, is a Platform any good if we're not surprised by what people build? I don't think so.
So, today I'm adding four disasters I've seen first-hand to the other six.
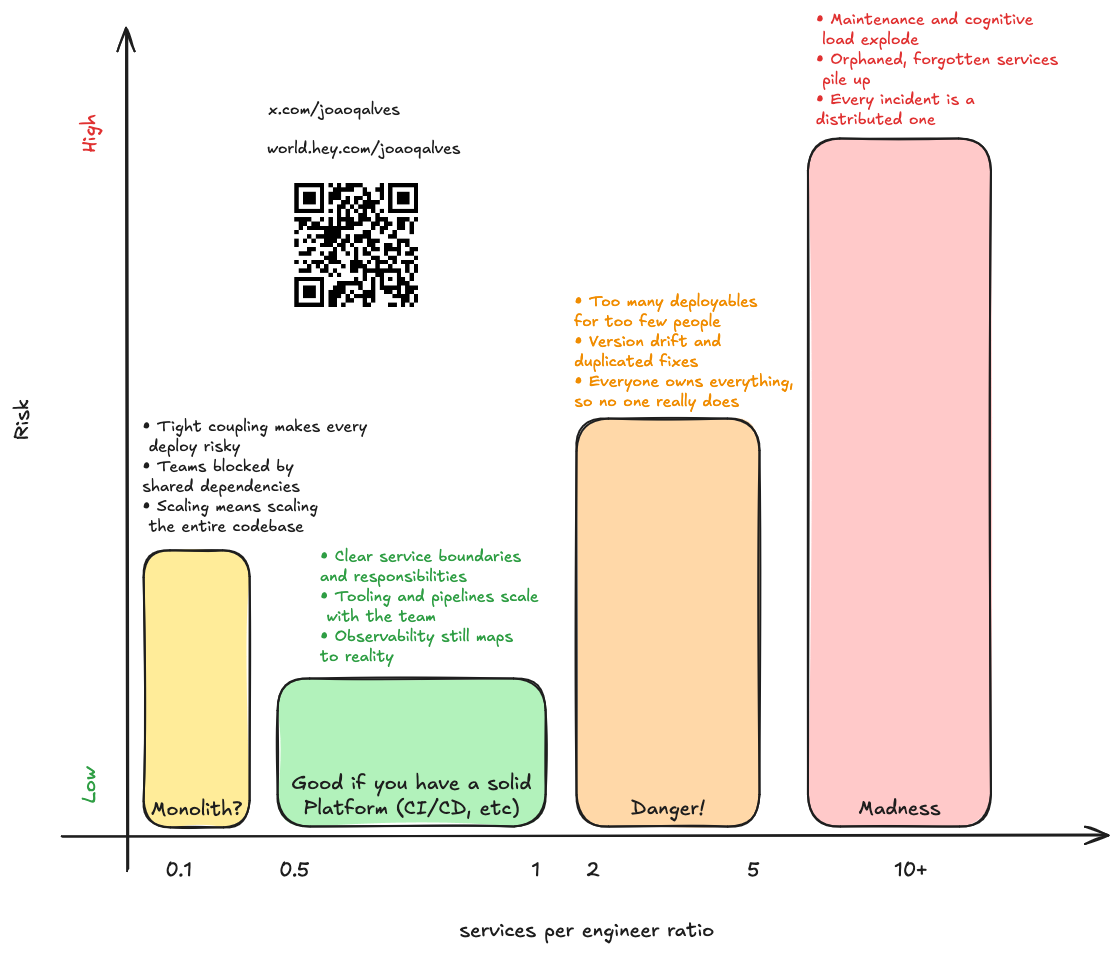
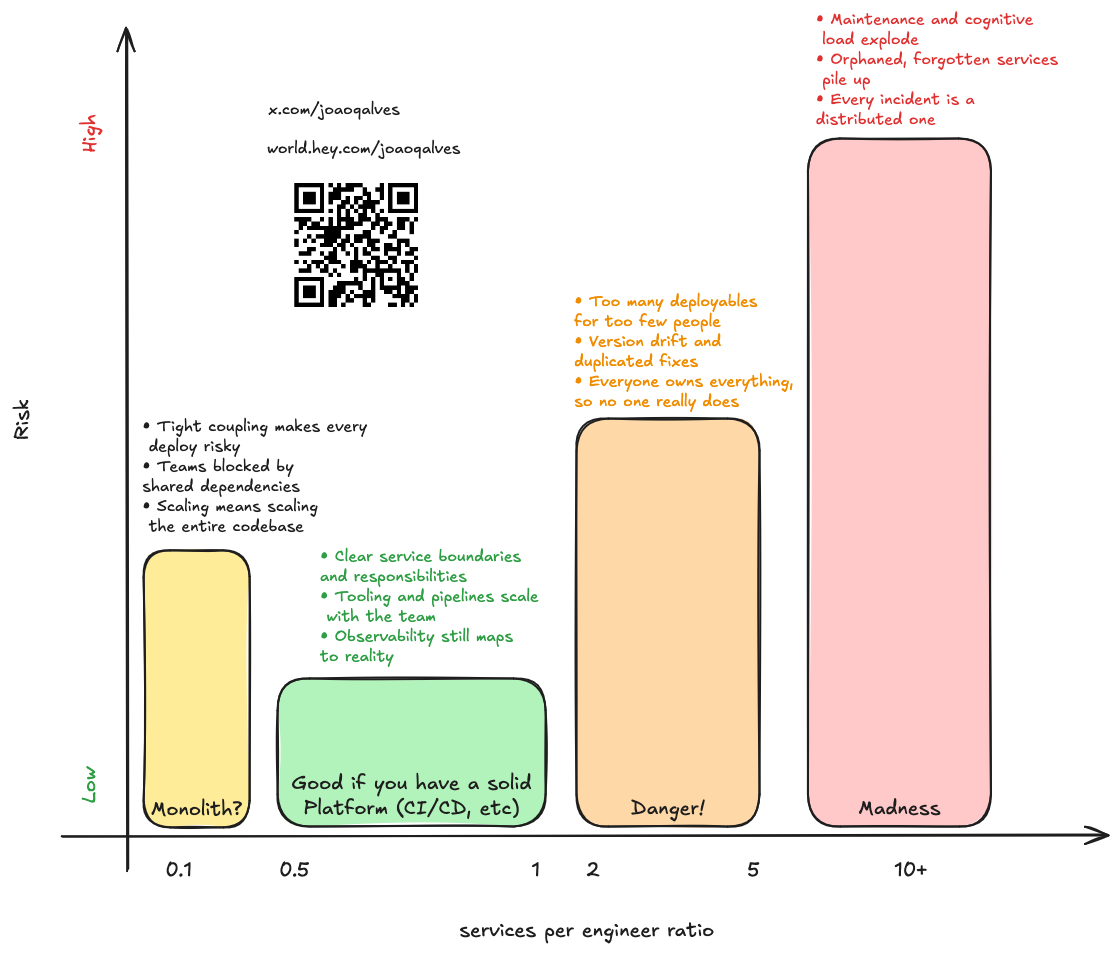
Disaster #7: more services than engineers
When I join a new team or domain, one of the first things I ask for is a walkthrough of the architecture. It's not just curiosity, it's survival. It helps me form a mental model of the feature set, complexity, technical debt, and the real boundaries of what's possible. It's also the best way to connect with Individual Contributors (ICs) and understand how they perceive the system.
Time and time again, I'm baffled by how many teams have more services than engineers. And I don't mean "slightly more". I'm talking about four or five services per person. It sounds impressive on a slide deck — "we've fully modularized our platform!" —, until you realize it means one human being is the de facto owner, operator, and incident responder for half a dozen distributed systems.
If you're Google, Uber, or any of the large tech companies with a world-class internal platform, you can get away with that. You have automatic dependency upgrades, standardized templates, CI/CD abstractions, service ownership dashboards, and well-staffed SRE teams. But most other companies? Even with good automation, this setup is a slow-motion disaster.
Each new service adds cognitive overhead. Think about new pipelines, dashboards, alerts, secrets, dependencies, and runtime contexts. Every change multiplies the blast radius. And when the team reorganizes (because they always do), those services become orphaned. No one remembers what they do, but everyone is too afraid to turn them off. They just keep running.
Disaster #8: the gateway to hell
One of the hardest things to get right in distributed systems is the gateway layer, the connective tissue between your frontends and microservices, or between services themselves. In theory, it's a clean abstraction. In practice, it's a pressure cooker for all the complexity we didn't want to deal with elsewhere.
Authentication and authorization are perfect examples. They sound simple until you need to combine multiple identity providers, fine-grained permissions, and multi-tenant scoping. All while remaining both secure and fast. Many teams underestimate how expensive those operations are, and worse, they overload their gateways with them. Suddenly, what was meant to be a lightweight routing layer becomes a CPU-bound monolith performing crypto operations and access checks for every request.
Then comes the other side of the coin: thread pools and I/O behavior. Gateways are typically the first and last hop in a request chain. If you don't understand whether your downstream services are CPU-bound or I/O-bound, you'll misconfigure your pools and timeouts. It's incredibly common to see gateways with default thread counts inherited from some Spring Boot starter or Node.js template, serving hundreds of concurrent connections. The result? Latency spikes, thread starvation, and cascading failures that ripple across the fleet.
Building reliable gateways requires more than YAML and good intentions. It demands understanding backpressure, circuit breakers, and how your runtime behaves under load. Most teams don't realize how fragile their setup is until a single misconfigured pool takes down the entire production environment.
Disaster #9: technology sprawl
Every company says they value "engineering autonomy." Few realize what that really means. Given enough time and freedom, engineers will pick every possible framework, runtime, and library known to humankind. Kotlin coroutines here, Vert.x there, Go services running next to a Rust API that only one person still understands. It's like visiting a theme park of ideas, until something breaks and no one remembers how to restart the ride.
This kind of technology sprawl doesn't happen because engineers are careless. It occurs because leadership allows — or even encourages it! — under the banner of innovation. But innovation without accountability leads to entropy. Every new stack is a new operational surface, a new security vector, a new onboarding cost. And when reorgs happen — spoiler: they always do! — these snowflake systems become landmines.
The only person who can fix them might have just left the company. Flight risk, in this context, isn't just a people problem; it's a systems problem. Each "unique" tech choice creates a dependency on a human being. Lose that person, and you lose that piece of the system's knowledge graph.
Fortunately, this is one area where things are getting better. AI-assisted code understanding tools, architecture reviews, and internal tech radars are helping teams regain visibility. They don't eliminate sprawl, but they make it more transparent. And sometimes, just seeing the mess clearly is the first step to cleaning it up.
Disaster #10: when the org chart becomes your architecture
This one is slightly related to Disaster #7, but with an organizational twist. I've talked about it countless times with Thibault. When teams start creating dozens of microservices, they often organize them by team ownership rather than by domain. So you end up with things like "Payments team", "Growth team", and so on. They deploy their services into their team's Kubernetes namespace, their Terraform stack lives in their team's AWS account, and all the dashboards and alarms are wired to the team's Slack channel.
It looks tidy on paper. Every team has clear ownership, autonomy, and a sandbox that the team can break without bothering others until the org chart changes. Because it constantly changes.
A new VP of Engineering brings fresh ideas for efficiency and alignment. A reorg happens. Suddenly, the "Payments team" that owned two bounded contexts — say, Payments and Subscriptions — is split into two. One team keeps Payments; another inherits Subscriptions. But all the infrastructure, namespaces, and IAM policies are still tangled under the old account. So now you have two options:
Share infrastructure, creating a new kind of dependency hell.
Migrate everything, which is just a fancy way of saying "congratulations, you've bought yourself a six-month migration project."
Neither option feels good. The first one slows teams down and creates confusion about ownership ("who fixes this alarm now?"). The second burns time and budget on work that delivers no user-facing value.
This problem goes deeper than just cloud accounts or namespaces. It's about coupling architecture to the org chart. When Conway's Law meets reorgs, you get architectural drift. Systems that once mirrored the team structure start to outlive it, and suddenly, your entire platform's topology reflects who reported to whom in 2021.
It's one of the most expensive kinds of technical debt. It's invisible until the (non-existent) reorg budget suddenly triples.
The new normal
Four years later, I'm still seeing the same patterns, just dressed in different frameworks, clouds, and YAML dialects. The tools evolved, but the fundamentals didn't: distributed systems remain distributed, humans remain human, and complexity remains undefeated.
What's coming next will make this even more interesting. We're now trying to build AI agents: autonomous, stateful systems that communicate with each other, make probabilistic decisions, and respond to unpredictable inputs. In other words: distributed systems with opinions. What could go wrong? The same fallacies apply, just at a different layer. Latency, consistency, observability, determinism. None of them magically disappears because the component now "thinks."
As an industry, we'll go through the same cycle again: early excitement, creative disasters, tooling booms, and eventually, a bit of humility.
Whether it's microservices or AI agents, the story doesn't really change. We're still trying to make chaotic systems behave predictably. And we're pretending we can fully control them.
The good news? We'll keep learning. The bad news? We'll probably learn it the hard way.
— João
PS: I'm building RotaHog, a lightweight tool for managing team rotation schedules (on-call, support shifts, release duties, etc.). Try it if you're tired of hacking spreadsheets or Slack threads together. I'd love your feedback!
If you enjoyed this article, consider subscribing to the newsletter and buying me a coffee.
About João Alves
Dad. Husband. Head of Engineering @Adevinta, and building rotahog.com. My main interest is to build and grow SaaS Products and Infrastructure teams. Twitter | LinkedIn | Mastodon