Mijn favoriete app gebruiken gaat nu 50x sneller door wat slimme inzichten
Wat ik al jaren roep: van de tien belangrijkste eigenschappen van software moeten voor mij 1 tot en met 9 snelheid zijn. Niet omdat alles maar snel moet, maar omdat ik weinig tolerantie heb voor technologische frictie die tussen wat ik wil doen en wat ik gedaan krijg zit.
Veel mensen vinden het prima om een kwartier te wachten tot een systeem zoals Citrix of een nieuwe update is opgestart om hun mail op te halen. Voor mij werkt dat niet. Ik was echt blij met Obsidian omdat het de snelste tool is waar ik tot op heden mee heb gewerkt. Al mijn notities in simpele tekstbestanden, mooi georganiseerd, doorzoekbaar. Maar elke keer als ik Obsidian opende om even snel iets op te zoeken — een telefoonnummer, een aantekening, wanneer ik ergens was — moest ik toch wachten. Een seconde of twee, en soms vijftien. Prima, maar ik vroeg me af of dat nog sneller kon, door mijn recente inzichten in het bouwen van mijn eigen Theta-systeem (dat een mix is tussen een snelle lokale database en markdownbestanden).
Het experiment
Ik ben al een tijdje bezig met een groot experiment over informatieliquiditeit. Een poging om mijn informatiekapitaal — iets wat ik behoorlijk serieus neem — beter te kunnen ontsluiten. Ik bouw aan een eigen systeem dat ik Theta noem, een soort persoonlijk command center dat lokaal op mijn computer draait.
En omdat alles in Markdown is, platte tekst, en ik toch bezig ben met een project over informatieautonomie in Markdown, vroeg ik me af: kan ik vanuit mijn eigen systeem, via de browser, ook mijn Obsidian-bestanden renderen? Tonen? En er bloedsnel in zoeken?
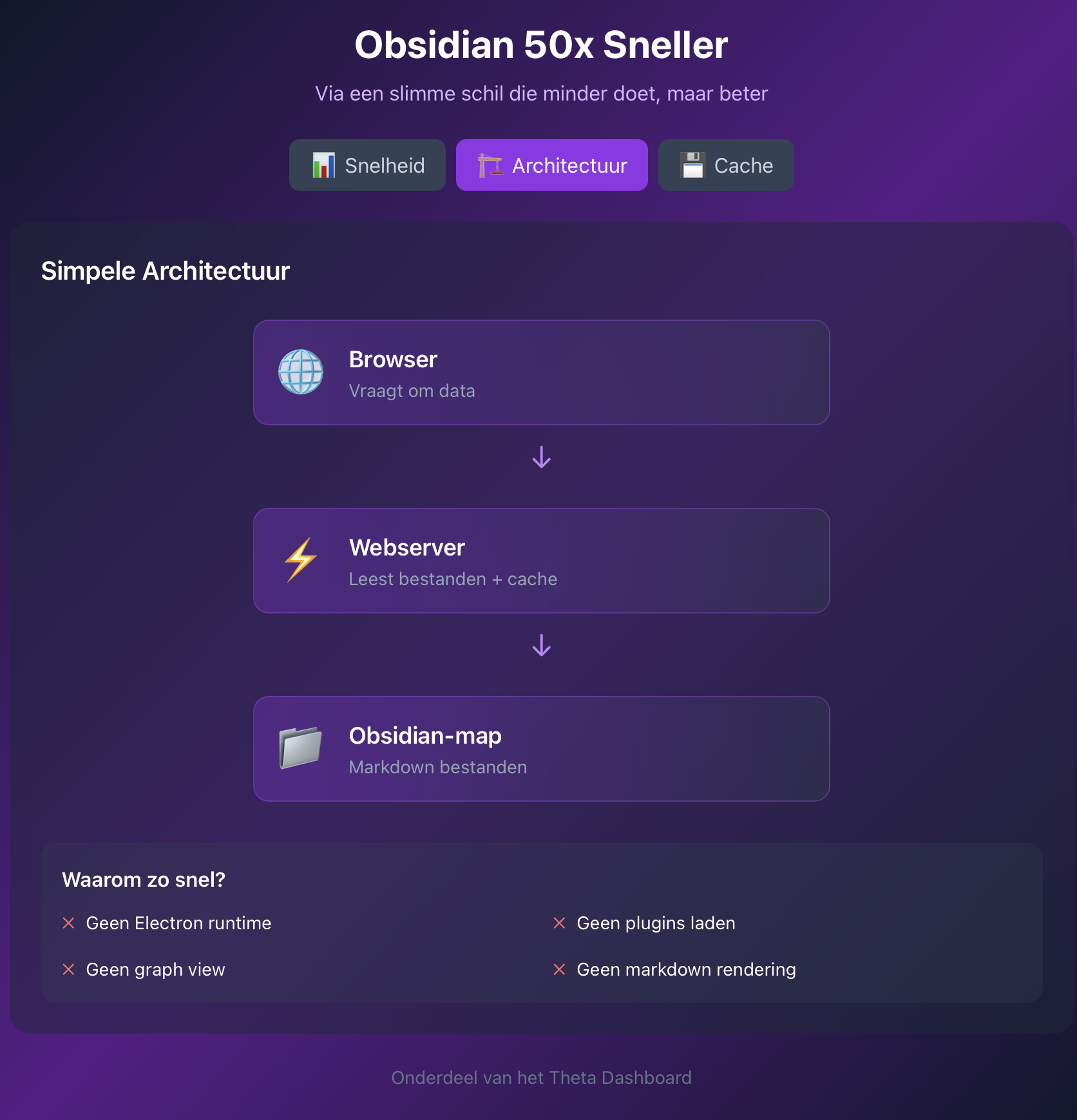
Computers zijn dol op platte tekst zoals Markdown. Ik ging ermee aan de slag en de architectuur is bijna gênant simpel:
Wat het doet
Het resultaat is een lokale webpagina die rechtstreeks mijn lokale Obsidian-bestanden leest. En dankzij het enorm open karakter van hoe Obsidian omgaat met data kun je code gewoon in de lokale Obsidian-map op je schijf laten kijken, bloedsnel.
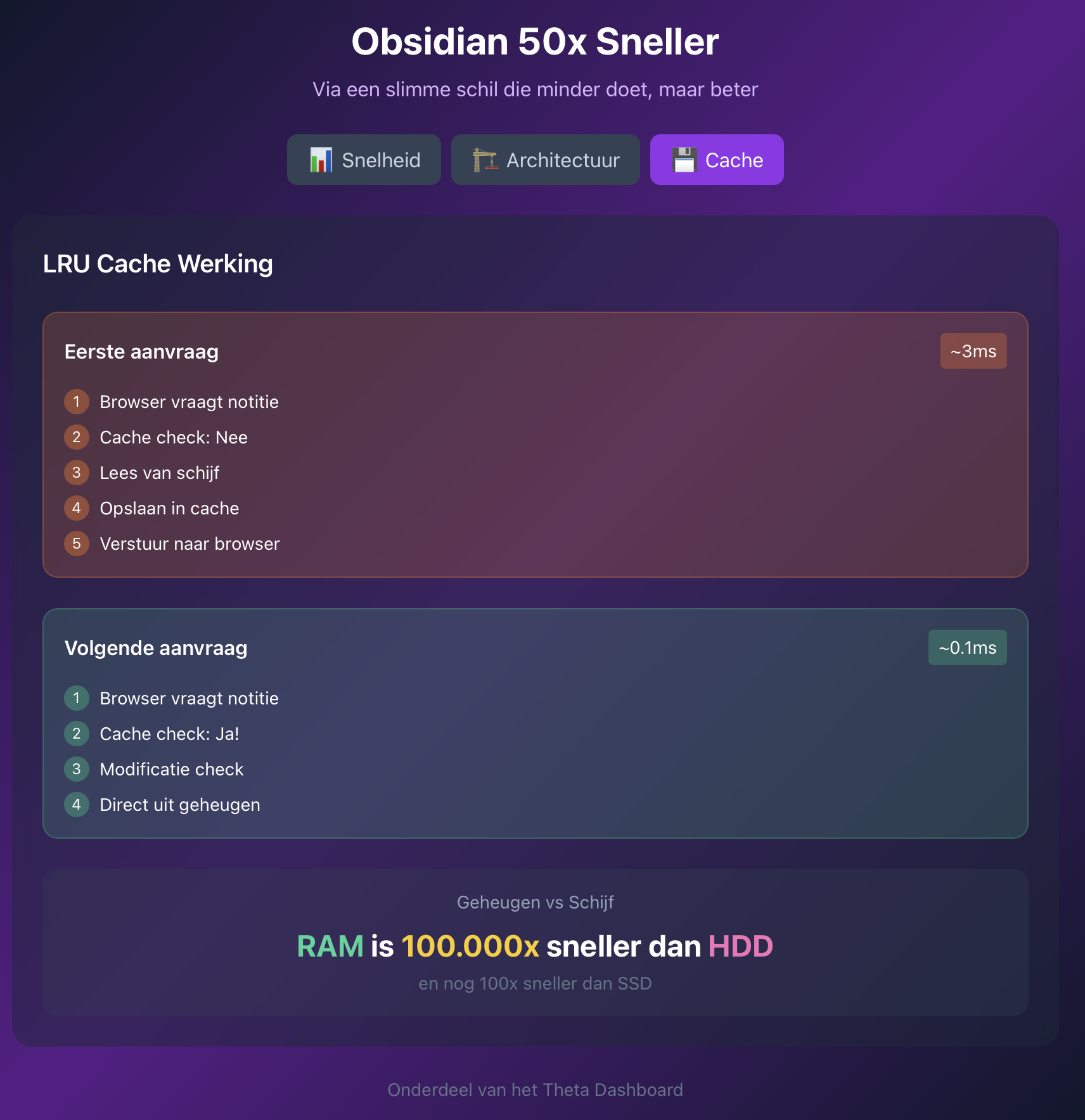
De truc zit in een technisch foefje dat caching heet. Stel je voor dat je een boek uit de kast pakt. De eerste keer moet je opstaan, naar de kast lopen, het boek zoeken. Maar als je het boek op je bureau legt, is de volgende keer pakken veel sneller. Mijn systeem doet precies dit. De eerste keer dat je een bestand opent, wordt het gelezen en onthouden. De volgende keer ligt het al klaar. En het checkt of het bestand ondertussen is veranderd — zo heb ik altijd de laatste versie, maar zonder vertraging. Kijk maar:
Het verschil tussen 3 milliseconden en 0.1 milliseconde klinkt abstract, maar je voelt het. Milliseconden lijken klein bier, maar opgeteld over een hele dag maken ze wel degelijk uit. Het doet me denken aan wat me wel eens overkomt als ik een Apple-product op het web heb gezien en het dan vasthou in de winkel. Soms moet je iets voelen om te snappen waar je naar kijkt. Dat je denkt: aha, dus dát is het! Dat geldt zeker voor dit verhaal over milliseconden. Voor de mensen die zich afvragen of ze dit ook nodig hebben: nee, ik heb hele specifieke informatie-behoeften en dit is voor de massa niet nodig. Maar voor mij maakt het flink uit.
Mijn totale verwondering zit in een paar details. Ik heb duizenden contactpersonen, en de 100 meest gebruikte worden als eerste geladen. Zodra ik begin te typen springen ze tevoorschijn — en dat geldt ook voor locaties, woonplaatsen, organisaties en boeken. Die snelle manier van namen opzoeken zorgt ervoor dat ik metadata bloedsnel op de juiste plek krijg.
Wat veel mensen zich onvoldoende realiseren is dat om informatie snel te kunnen vinden, je snel moet kunnen filteren. Het toevoegen van metadata aan je informatie — iets wat ik voortdurend doe met templates in Obsidian — maakt dat ik in tegenstelling tot veel anderen veel van mijn informatie razendsnel kan vinden. Het geheim van informatie kunnen vinden en filteren zit in slim omgaan met metadata, iets waar de meeste mensen nog nooit over nagedacht hebben.
Elke notitie in Obsidian heeft bovenaan een blokje met gegevens: wie erbij hoort, welk project, welke datum. Dit maakt dat je razendsnel kunt zoeken naar informatie, het is een routekaart voor informatie, en het voorkomt hallucinatie bij gebruik met AI. Normaal moet je dat handmatig invullen. Nu typ ik een paar letters, de juiste naam springt tevoorschijn, ik klik op enter en de naam verschijnt op de juiste plek. En met sneltoetsen gaat het nog vlotter — druk op "1" en je bent op de hoofdpagina, b voor boeken en p voor personen.
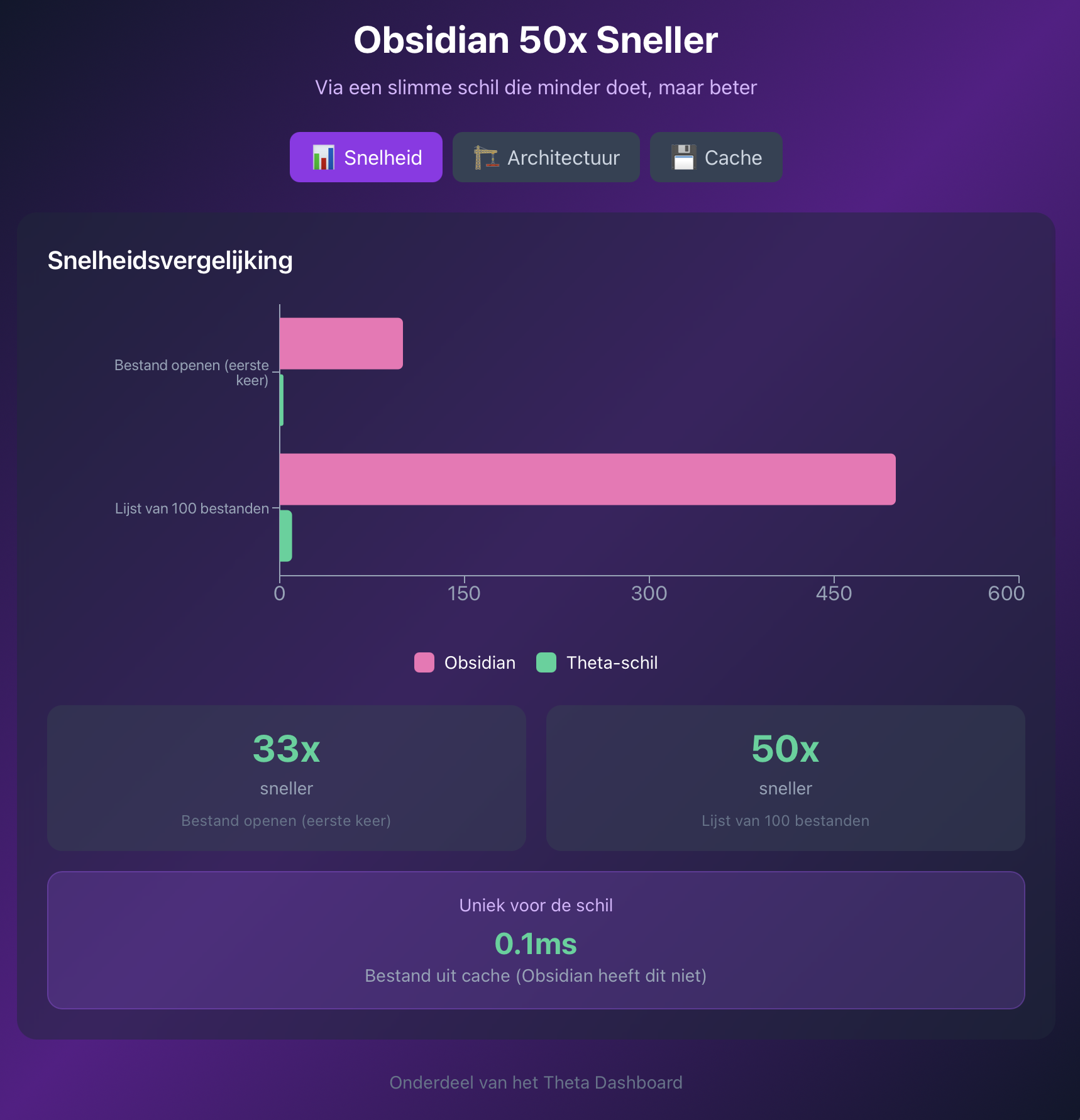
De cijfers Ik heb het niet wetenschappelijk gemeten, maar dit zijn realistische schattingen:
Bestand openen (eerste keer) | ~100ms | ~3ms Bestand openen (uit cache) | N.v.t. | ~0.1ms Lijst van 100 bestanden laden | ~500ms | ~10ms
In een grafiek wordt het verschil nog duidelijker:
Dat is 30 tot 50 keer sneller. En dat merk je. Die snelheid is ongekend, en deze cache-functie heeft Obsidian niet op deze manier.
Minder frictie maakt echt uit
Ineens kan ik veel sneller dan voorheen mijn informatie makkelijk voorzien van meer context en metadata. De losse informatie-elementen — mensen, organisaties, projecten, plaatsen, locaties, onderwerpen en boeken — raken steeds nauwer verbonden terwijl de hoeveelheid data nauwelijks groeit. Alle losse elementen worden superslim hergebruikt met weinig overhead. Dat maakt het systeem zo snel en robuust.
Ik hoop dat ik op enig moment de taal vind om dit aan organisaties duidelijk te maken. Alles wat ik al 8 jaar (of langer) vermoed over mappen en documenten wordt steeds meer bevestigd: het is een dure doodlopende weg.
Betere metadata geeft een enorme hefboom bij het gebruik van AI. AI zonder gestructureerde metadata is vragen om moeilijkheden en hallucinaties. Bij mij gebeurde het omgekeerde. Mijn informatiekapitaal — en de rente daarop — werd steeds waardevoller en krachtiger. En alles ging ook nog eens sneller.
Dit project leerde me iets: de snelste code is code die niet draait. Obsidian is niet traag omdat het slecht gebouwd is. Het is "traag" omdat het veel doet. Plugins laden, grafieken berekenen, markdown renderen — allemaal nuttige dingen. Maar als ik die dingen niet nodig heb, waarom zou ik erop wachten?
Mijn schil doet 5% van wat Obsidian doet. Maar voor mijn use case is die 5% voor 90% van mijn gevallen precies genoeg. Soms is de beste optimalisatie om gewoon minder te doen 🤣
Dit is onderdeel van mijn Theta Dashboard en mijn bredere experiment met informatieliquiditeit. Zelf met code klooien levert een hoop inzichten op. Blijmakend dit. Maar dat werken met mijn data in Obsidian zo snel zulke spectaculaire resultaten kan opleveren — want dat zijn het — had ik niet durven dromen. Ik kan niet wachten om er een demo over te geven op de 3e PKM Summit.