這幾天在下班時間斷斷續續地做完一件事:把一篇 Deep Research 產的報告看完,製作對應的筆記,再整理成一份彙整文章。
我感覺這一套流程可以反覆使用,因此想趁著印象深刻把它記錄下來,也分享給大家。
---
步驟一:讓 ChatGPT o1 Pro 列研究問題,再讓 Deep Research 產製報告
我會輸入一個我感興趣的主題或問題,請 o1 Pro 幫我發散規劃可能相關的各種延伸問題,然後我再簡單手動編輯,去掉我不感興趣的,調整用詞,丟給 Deep Research。
---
步驟二:逐段閱讀 Deep Research 的報告,在 Heptabase 裡製作成原子卡片與心智圖
我會把 Deep Research 產出的報告貼到 Heptabase 裡面閱讀,邊閱讀邊製成原子卡片,中間我有請 ChatGPT o1 幫忙,有些段落我會直接丟給他請他產原子卡片,我再翻譯成中文,並且用我自己的理解改寫文字。
改寫時我也會簡單透過心智圖整理這些卡片(如下圖),並且把 Deep Research 的原文列在下方作為參考資料。
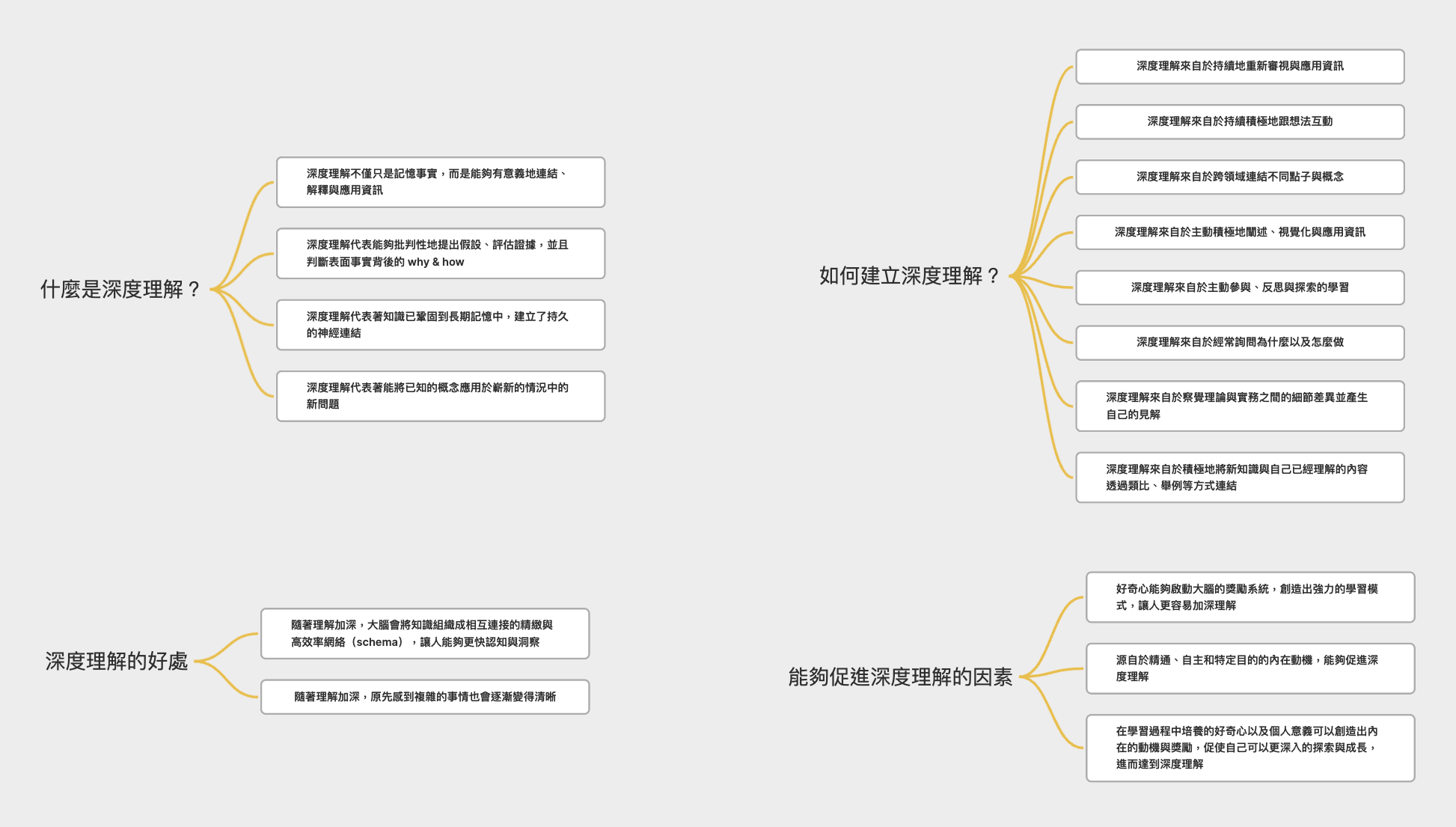
---
步驟三:把在 Heptabase 內架構完畢的原子卡片標題,交給 ChatGPT o1 Pro 產成一篇包含說明與案例的專文
透過前兩個步驟產出的原子卡片有點像是空有標題,但內容還不明確,為了讓現在與未來的我更容易理解,我就反過來丟給 o1 Pro 產介紹文章,這時他就會擴寫標題,並且提供對應的案例。最後,我會再回到原本的卡片,把 ChatGPT 產的說明與案例補充進去。這時我就有了一個有豐富內容的「卡片起點」,可以讓我未來持續擴寫、改寫與補充我自己的案例。

我應該會繼續用這套方法去處理其他更多 Deep Research 產的報告,我覺得很有效,因為卡片的標題都是我自己消化過的,所以後續的說明與案例也夠精準好懂,看過一次就很有印象了!
我感覺這一套流程可以反覆使用,因此想趁著印象深刻把它記錄下來,也分享給大家。
---
步驟一:讓 ChatGPT o1 Pro 列研究問題,再讓 Deep Research 產製報告
我會輸入一個我感興趣的主題或問題,請 o1 Pro 幫我發散規劃可能相關的各種延伸問題,然後我再簡單手動編輯,去掉我不感興趣的,調整用詞,丟給 Deep Research。
---
步驟二:逐段閱讀 Deep Research 的報告,在 Heptabase 裡製作成原子卡片與心智圖
我會把 Deep Research 產出的報告貼到 Heptabase 裡面閱讀,邊閱讀邊製成原子卡片,中間我有請 ChatGPT o1 幫忙,有些段落我會直接丟給他請他產原子卡片,我再翻譯成中文,並且用我自己的理解改寫文字。
改寫時我也會簡單透過心智圖整理這些卡片(如下圖),並且把 Deep Research 的原文列在下方作為參考資料。
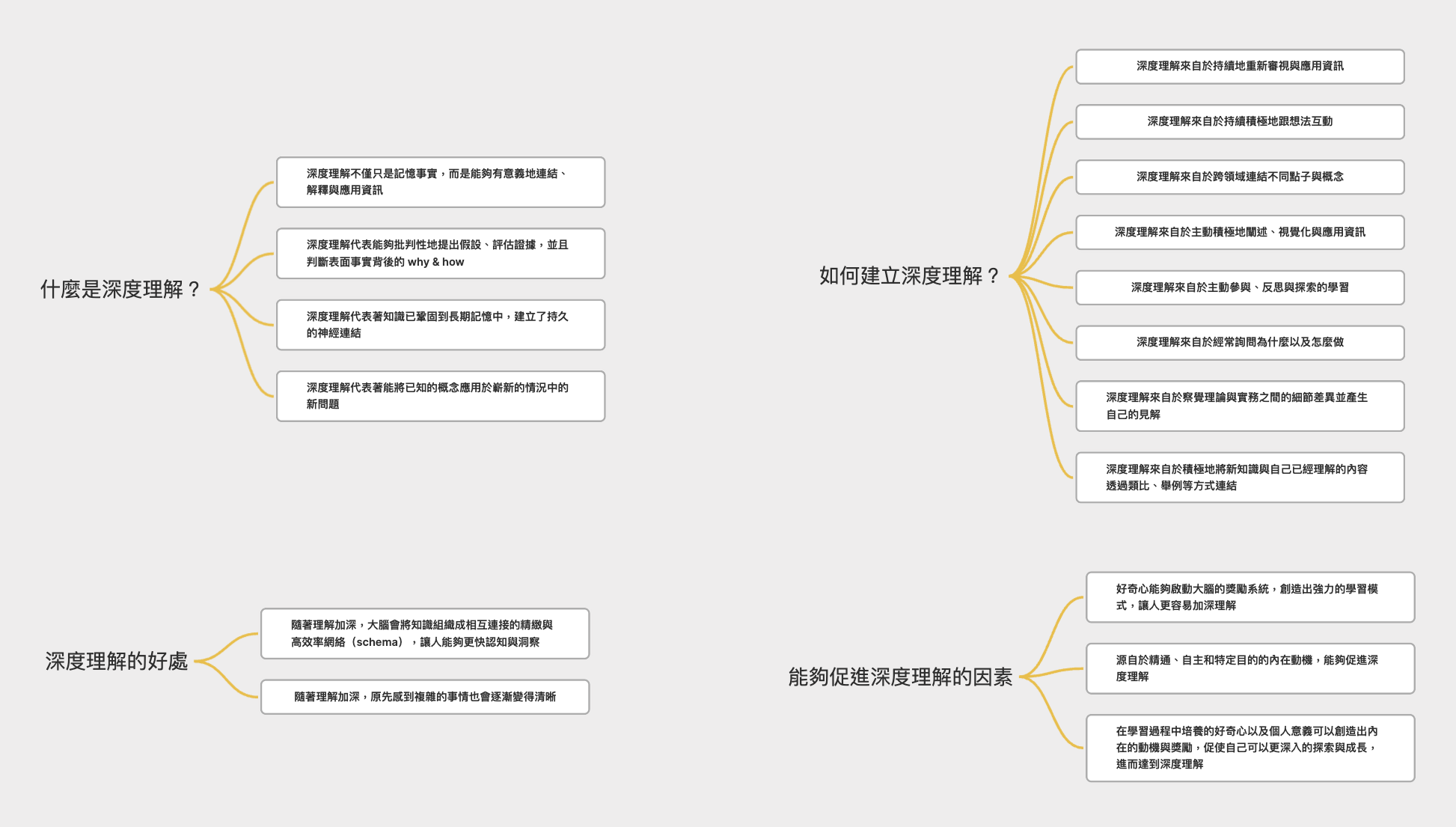
---
步驟三:把在 Heptabase 內架構完畢的原子卡片標題,交給 ChatGPT o1 Pro 產成一篇包含說明與案例的專文
透過前兩個步驟產出的原子卡片有點像是空有標題,但內容還不明確,為了讓現在與未來的我更容易理解,我就反過來丟給 o1 Pro 產介紹文章,這時他就會擴寫標題,並且提供對應的案例。最後,我會再回到原本的卡片,把 ChatGPT 產的說明與案例補充進去。這時我就有了一個有豐富內容的「卡片起點」,可以讓我未來持續擴寫、改寫與補充我自己的案例。

我應該會繼續用這套方法去處理其他更多 Deep Research 產的報告,我覺得很有效,因為卡片的標題都是我自己消化過的,所以後續的說明與案例也夠精準好懂,看過一次就很有印象了!
PJ Wu