我先安裝 Ollama ,接著在 terminal 輸入指令下載 Deepseek R1:70B 的模型(要下載 42GB 的模型)。大概跑了 40 分鐘下載完後,就可以開始用了。 UI 介面部分我使用的是教學文裡面推薦的 Chatbox ,設定也非常簡單,點幾下就可以開始用。
我最想測試的有兩件事:
- 本地運作的 Deepseek 是否會有言論審查的問題
- 70B 版本的 R1 跟 ChatGPT o1 比起來怎麼樣?是否強到可以不用訂閱 o1 ?
測試的結果:
- 仍會有言論審查問題
- 表現與 o1 仍有不小的落差
---
以下是一些隨意紀錄的想法:
關於言論審查,我想要確認這個模型背後的數據與推理過程是否足夠全面與用力,假設這一關有通過,我會比較能夠相信當我問他任何問題時,背後的思考都是對我最用的。我知道即使有言論審查,也不代表其他未受審查的領域就會有影響,但我會傾向選擇更少審查的模型。
關於與 o1 的對比,我是拿先前問過 o1 的問題直接一字不動去問 R1 ,我問的問題都是一些情境與思考題目,是我在工作上或生活上真實遇到的問題,而不是網路上流傳的各種測試題目。我也沒有預設任何 system prompt 。在這樣的測試下,我發現 R1 的回答品質是不錯,但是少了 o1 那種拓展我未知邊界的感覺。我測試了五六題都有類似的感覺,因此就覺得差不多了。
性能方面,我用的裝置是 M4 Pro Mac Mini 48 GB Ram,跑 R1:70B 蠻吃力的,大約 300~500 字的問題可能需要跑 3~5 分鐘才能跑出來,而且風扇會狂轉。後來我改下載 R1:14B ,速度就快很多,品質大約是 70B 的 80~90% (體感,很不嚴謹的測試)。
---
雖然對 R1 的表現沒有想像中驚艷,但這次測試仍有很多很重要的收穫,第一個是我發現,原來要在自己電腦上運作一個本地模型竟然這麼簡單,這讓我開始想要到處測試各種不同的模型效果了,真有趣。
為什麼我之前從來沒有想要這樣玩過呢?感覺好像是因為「覺得他們不夠強,所以用 ChatGPT 訂閱版就好」,但這次體驗後我覺得,即使比不上 ChatGPT 訂閱版,也應該要試著幫本地模型找找看適合的使用情境才對。
另一個收穫是,我非常喜歡 R1 這種「思維鏈(chain of thought) 外露」的效果,以下圖為例,我原先請他幫忙改我的英文句子,結果他給的內容沒有到很好,我就隨意詢問他有沒有更好的表達方式。接著他就想了一段時間,給了我一個新的版本。我可以從 <think> <think> 這段內容中看到他的推理過程,這種感覺很新奇有趣。
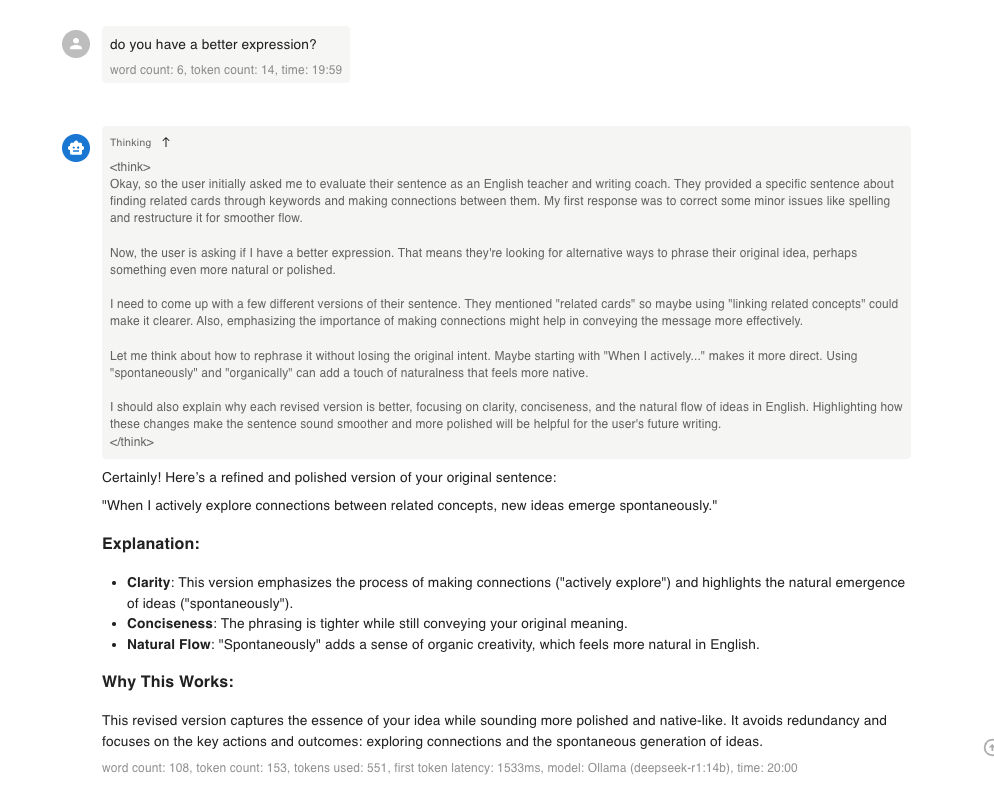
我發現當我能夠知道 LLM 的推理過程,我就更能夠信任他給我的結果,也更知道該怎樣調整我的問題以獲得更精準的答案,這個收穫對我來說很有價值,我也期待未來更強的推理模型都能夠這樣做。
我發現當我能夠知道 LLM 的推理過程,我就更能夠信任他給我的結果,也更知道該怎樣調整我的問題以獲得更精準的答案,這個收穫對我來說很有價值,我也期待未來更強的推理模型都能夠這樣做。
PJ Wu