Hoe ik ThetaOS bouw met AI — en hoe ik het robuust, schaalbaar en auditbaar houd
Snelle samenvatting:
In 500 uur en drie keer opnieuw beginnen ontdekte ik wat er nodig is om AI-gegenereerde code betrouwbaar te maken.
Ik ben geen programmeur, maar ik bouw inmiddels een compleet persoonlijk informatiesysteem: 153 tabellen, 165.000 records, 85 modules die samenwerken.
Dit artikel beschrijft die reis. Hoe een feedbacksessie met een ervaren developer mijn audit-score van 98% naar 42% deed kelderen, en hoe ik hem daarna opnieuw naar 98% bracht.
Welke vier lagen mijn auditsysteem nu heeft. En welke drie vragen elke organisatie zou moeten stellen aan teams die met AI code schrijven.
(het stuk is best lang, maar dat is zodat mensen die inhoudelijk het willen snappen ermee aan de slag kunnen)
Het narratief dat niet klopt
Vorige week publiceerde Concordia University het onderzoek Beyond Synthetic Benchmarks. Ik kwam het op het spoor via een post van Amir Sabirović. De conclusie is ontnuchterend: waar AI-modellen 84-89% scoren op kunstmatige testopgaven, halen ze slechts 25-34% op echte code uit echte projecten. De breekpunten zijn niet spectaculair. Het zijn verkeerde attributen, type-inconsistenties, logische missers. AttributeError, TypeError, AssertionError — samen goed voor 84% van alle fouten.
Sabirović schreef: "Het rapport leest als een wetenschappelijke roast met voetnoten. Wie denkt dat generatieve AI productiecode schrijft, neem vooral ook een brandblusser op je backlog."
De reacties bevestigden het beeld. Ervaren developers herkenden het patroon: AI die zelfverzekerd begint en eindigt in chaos. "Het lijkt alsof je met een liegende PhD werkt die niet kan luisteren," schreef iemand.
Ik snap dat sentiment. En toch klopt het niet helemaal.
AI is geen onbetrouwbare volwassene. AI is een kleuter. En kleuters moet je opvoeden. Je laat een kleuter niet los in een keuken met messen en zegt daarna: "Zie je wel, kinderen kun je niet vertrouwen." Je leert ze wat ze wel en niet mogen. Je houdt toezicht. Je corrigeert. En langzaam, met geduld en structuur, worden ze competent.
Dat is wat ik de afgelopen maanden in 500 uur heb gedaan.
Wat ik gebouwd heb
Ik ben geen programmeur. Ik heb geen technische achtergrond in software-ontwikkeling. Maar met Claude Code, de AI-tool van Anthropic die ik headless in mijn terminal draai op mijn Mac, bouw ik inmiddels een complete software-suite. iOS-apps die praten met een centrale database. 85 modules die samenwerken. Een persoonlijk informatiesysteem dat ik ThetaOS noem: 153 tabellen, ruim 165.000 records, 63 megabyte aan gestructureerde data over mijn leven. Dat is puur tekst en cijfers, zonder foto's of video's. Het equivalent van meer dan honderd boeken aan informatie.
Dit is geen hobbyproject dat volgende maand in een la verdwijnt. Het draait dagelijks, groeit mee met mijn leven, en breekt niet om de haverklap.
Dat ging echt niet vanzelf. Na drie keer helemaal opnieuw beginnen was ik het beu en besloot ik het heel gestructureerd aan te pakken. Mijn Common Pitfalls-document — de verzameling van fouten die we maakten en hoe we ze oplosten — telt inmiddels na 500 uur bouwen twintigduizend regels. Daarnaast heb ik meer dan honderdtwintig replicatiedocumenten. Ik doe dagelijkse audits, soms acht keer per dag.
Dit is geen "even snel iets maken met ChatGPT." Dit is puur discipline. Maar het is ook geen raketwetenschap. De dingen waar je rekening mee moet houden zijn niet moeilijk. Ze gaan alleen niet vanzelf. En omdat ik weet wat ik bouw en waarom, ben ik extreem gemotiveerd om dit heel goed te doen.
In de praktijk tik ik mijn instructies niet eens. Ik spreek ze in via de app Wispr Flow op mijn Mac, en die tekst verschijnt direct in Claude Code. Geen toetsenbord, alleen denken en praten. Dat maakt het razend snel.
De aanpak: beginnen bij het einde
Na drie keer opnieuw beginnen besloot ik het anders aan te pakken. Ik vroeg ChatGPT, Claude en Gemini om de belangrijkste principes voor een systeem zoals het mijne: SQLite, Node.js, JavaScript, CSS, HTML, met API's ertussen. Veel meer dan deze begrippen ken ik niet.
Ik vertelde dat ik robuuste, flexibele, toekomstbestendige, bloedsnelle code wilde. Code voor een systeem dat uiteindelijk honderd keer groter zou worden en vijfduizend keer meer data aan zou moeten kunnen. Alsof ik de bouwtekeningen van het Pentagon gebruik voor een hutje in het bos.
Maar mezelf kennende zou ik nog wel een flinke tijd doorknutselen aan dit project. Dus begon ik met het einde in zicht en rekende ik terug welke fouten ik niet mocht maken om in de toekomst in de problemen te komen.
Mijn grote vondst was een compliance audit: een checklist met principes en regels die ik stelselmatig kon draaien om te checken of wat we maakten tot problemen kon leiden. Ik noemde het met een knipoog Eredivisie Light-architectuur. Zwaar overkill voor één gebruiker met persoonlijke software, maar omdat ik er serieuze dingen mee wil doen: better safe than sorry.
Elke keer als ik een nieuw blokje code had gemaakt dat werkte, ging ik niet achteroverleunen om ervan te genieten. Ik draaide acuut een audit om te kijken of er iets was gecreëerd wat niet aan onze afspraken voldeed, waardoor ik in de toekomst mogelijk in de problemen zou kunnen komen.
De architectuur in drie lagen
ThetaOS is een local-first systeem. Dat betekent dat ik niet afhankelijk wil zijn van een internetverbinding om zinnige dingen met mijn data te kunnen doen. Het systeem heeft een harde scheiding tussen data, logica en interface.
Data leeft in SQLite voor snelle queries en Markdown voor context die menselijk leesbaar blijft, ook over twintig jaar. Data mag nooit opgesloten zitten in één app. Apps komen en gaan; mijn waardevolle persoonlijke informatiekapitaal blijft van mij.
Logica zit op één plek, niet verstopt in schermen of knoppen. Als ik bepaal dat een bedrag altijd positief moet zijn, of dat een datum in een bepaald formaat moet staan, dan staat die regel in een service — niet verspreid over tien verschillende schermen. Zo kan ik het controleren en hergebruiken.
Interfaces — apps, widgets, dashboards — zijn de buitenkant. Die kan ik vervangen zonder iets kapot te maken. Vorige maand bouwde ik een nieuwe iPhone-app in een middag, omdat ik alleen de voorkant hoefde te maken. De data en regels bestonden al.
Waarom dit ertoe doet: als de AI code schrijft die deze scheiding doorbreekt, weet ik dat er iets mis is. De architectuur is het hek waarbinnen de AI mag spelen.
Mijn slimme vondst: emoji-ontologie
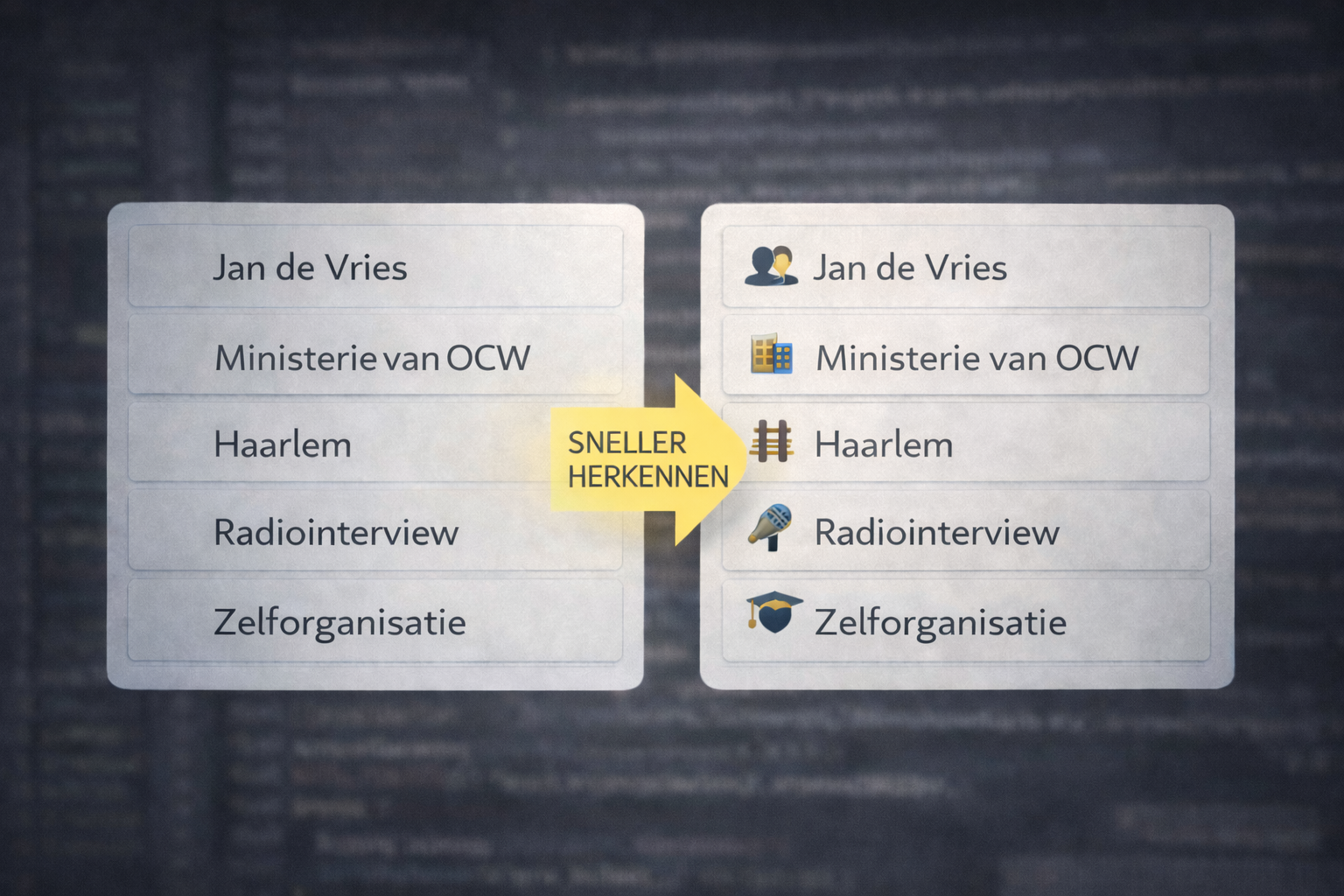
De magie van ThetaOS zit niet in de tabellen, maar in hoe alles verbonden is. En dat begint met iets onverwachts: emoji's.
Niet als versiering, maar als classificatiesysteem. Elke soort entiteit heeft een eigen prefix: 👤 voor personen, 🏢 voor organisaties, 🏣 voor locaties, 🎤 voor optredens, 📗 voor boeken. Als ik ergens schrijf [[👤 Jan de Vries]], wéét het systeem dat dit een persoon is. Automatisch. De backend herkent de emoji en zoekt in de juiste tabel.
Dit klinkt als een gimmick. Het is het tegenovergestelde.
Je visuele systeem verwerkt kleuren en vormen in 50 tot 250 milliseconden. Automatisch, zonder bewuste inspanning. Lezen moet door je prefrontale cortex, de grootste energievreter in je brein. Waar vormen en kleuren herkennen miljoenen jaren is geëvolueerd, is lezen een truc van de laatste paar duizend jaar. Je brein moet er hard voor werken. Als ik een lijst met honderd namen zie, moet ik ze allemaal lezen om te weten wat ze zijn. Maar als ik 👤 zie, weet mijn brein in een fractie van een seconde: dit is een persoon. Voordat ik ook maar één letter heb gelezen.
Na een paar weken zijn die emoji's zo ingesleten dat ik een pagina kan scannen en direct weet wat waar staat. Eén symbool dat geen cognitieve belasting kost en oneindig schaalt.
Mijn eureka-moment na drie keer helemaal opnieuw beginnen
Ik was al een tijdje lekker bezig en dacht dat ik dingen heel slim deed. Wat op zich klopte, maar na 400 uur en vele honderden audits kreeg ik nog wat sceptische vragen uit mijn omgeving over wat ik nou aan het doen was met die audits. Ik ging bij Mark Vletter langs, iemand die meer ervaring met frontend heeft dan ik. Hij keek even mee of er nog iets miste.
Hij opende de bestanden en begon te tellen.
Dezelfde CSS-class .form-group stond 273 keer gedefinieerd, verspreid over 34 bestanden. Niet verwijzingen naar één definitie — 273 aparte definities van dezelfde styling. Dezelfde functie handleSearch() was 26 keer opnieuw geschreven, telkens net iets anders. De functie escapeHtml() — drie regels code, cruciaal voor beveiliging — bestond in 109 verschillende versies door de hele codebase.
Eén JavaScript-bestand telde 7.199 regels. Zevenduizend regels in één bestand. Dat is geen code, dat is een roman. En overal lagen vergeten backup-bestanden: 468 stuks, verspreid door mappen waar ze niet hoorden. Allemaal zaken waar ik als leek echt geen verstand van heb en die mijn audit over het hoofd had gezien. Maar dat kon dus nog veel slimmer en handiger.
Oei! Werk aan de winkel. Maar wel met een belangrijke nuance: wat Mark zag lag binnen zijn expertisegebied, namelijk goed nadenken over de frontend en het hergebruik van elementen. Dat deed misschien iets met de snelheid van de code en de onderhoudbaarheid. Maar het zei in wezen niets over of mijn systeem zou kunnen breken.
Mijn audit-score van 98% bleek een illusie. Ik had AI laten controleren of de code de regels volgde. Ik had niet gecontroleerd of de code goed was — want ik kan geen code lezen. De losse onderdelen voldeden aan de regels. Maar het geheel was een rommeltje, alsof elke steen in een muur recht ligt, maar de muur zelf scheef staat.
De eerlijke score, gemeten met een uitgebreider framework dat ook naar structuur en duplicatie keek: 42%.
Dat was was wel even schrikken. Niet alleen omdat het getal laag was, maar omdat ik het niet had gezien. Ik had honderden uren gebouwd, dagelijks geaudit, trots artikelen geschreven over mijn aanpak — en toch was de helft van wat ik maakte rommelig, dubbel, of onnodig complex. De AI had het niet gezien. Ik had het niet gezien. We hadden samen een probleem gemaakt en het samen gemist.
Dit is het moment waarop ik begreep dat mijn audit incompleet was. Niet dat de AI slechte code schreef — de code werkte prima. Maar ik had niet de kennis om te checken wat een ervaren frontend developer wel ziet: waar kun je slim hergebruiken, waar groeit iets uit de hand, waar schrijf je onnodig dingen dubbel. Mijn audit checkte of de regels gevolgd werden. Niet of het geheel slim in elkaar zat.
Het goede nieuws was dat ik gewapend met dit nieuwe inzicht vrij snel met hulp van Mark tot een fors verbeterde audit kon komen. De les van Mark bleek goud.
Wat ik daarna anders deed
Op de weg naar huis van Groningen naar Haarlem startte ik in de trein met een complete refactor van mijn hele systeem. Met de nieuwe kennis en inzichten moest ik heel veel migraties doen. In totaal ben ik zestien uur bezig geweest tot ik de volgende ochtend om half twaalf eindelijk kon checken of het gelukt was. Na een paar kleine simpele aanpassingen van een paar minuten draaide mijn systeem als een zonnetje, maar nu met nog robuustere code en met slim hergebruik van alle elementen die Mark had aangedragen.
Daarna herbouwde ik mijn auditsysteem van de grond af. Het probleem was niet dat ik niet controleerde — ik controleerde dagelijks. Het probleem was dat ik de verkeerde dingen controleerde.
Het nieuwe framework heeft vier lagen, elk met eigen focus en gewicht.
De eerste laag kijkt naar compliance: worden de basisregels gevolgd? Worden database-queries slim hergebruikt in plaats van elke keer opnieuw opgebouwd? Wordt data consistent opgeslagen in het juiste formaat? Worden klikacties op één centrale plek afgehandeld in plaats van verspreid door de hele interface? Wordt invoer gevalideerd voordat het de database in gaat? Dit zijn de hekken waarbinnen de AI mag spelen. Als hier iets mis is, maakt de rest niet uit.
De tweede laag kijkt naar hardening: zijn best practices toegepast? Worden fouten netjes opgevangen met duidelijke meldingen in plaats van dat het systeem crasht? Wordt bijgehouden wat er gebeurt zodat je problemen kunt terugvinden? Zijn er vangnetten ingebouwd voor als er iets misgaat? De dingen die niet strikt noodzakelijk zijn om te functioneren, maar wel om betrouwbaar te draaien.
De derde laag — en dit was de blinde vlek — kijkt naar architectuur. Is er duplicatie? Zijn bestanden te groot geworden? Wordt gedeelde code ook echt gedeeld, of heeft elke module zijn eigen kopie? Dit is waar de 273 keer gedefinieerde .form-group vandaan kwam. Dit is waar de 109 versies van escapeHtml() vandaan kwamen. Code die werkte, maar die een onderhoudsnachtmerrie was.
De vierde laag kijkt naar technische schuld. Sluipen er backup-bestanden de codebase in? Is er code die niet meer gebruikt wordt maar nog wel bestaat? Zijn er patronen die ooit logisch waren maar inmiddels achterhaald? Dit is het soort rommel dat langzaam opbouwt en pas pijn doet als je iets wilt veranderen.
Elke laag weegt mee in een totaalscore. De eerste en derde laag wegen het zwaarst, elk dertig procent. Je kunt niet meer 91% scoren door alleen de regels te volgen terwijl je architectuur een puinhoop is.
Na zestien uur doorlopende refactoring steeg de score van 42% naar 98%. Niet door nieuwe features te bouwen, maar door op te ruimen. Door de 109 versies van diezelfde drie regels code terug te brengen naar één, in een gedeeld bestand dat alle modules importeren. Door de 7.199 regels in dat ene bestand te verdelen over zes kleinere, elk met een duidelijke verantwoordelijkheid. En door de 468 backup-bestanden te verplaatsen naar een archief buiten de codebase.
98% compliant is zeldzaam, weet ik inmiddels. En echt ongekend voor een solo-project met mij als enige gebruiker. Maar voor minder doe ik het niet. Want ik wil keer op keer doorbouwen op iets dat robuust is en blijft. Mijn aanname is dat als ik niet voortdurend mijn codebase op 98% hou, ik wellicht brakke code op brakke code ga bouwen. En dat levert me in de toekomst een enorm probleem op.
Maar ik leerde een waardevolle les: je kunt compliant zijn én tegelijk een puinhoop hebben. Borging betekent meer dan regels volgen. En die borging wordt per dag beter!
De regels die niet onderhandelbaar zijn
Door trial-and-error ontstond een set van veertien principes waar alle code aan moet voldoen. Achter elke regel zit een verhaal van frustratie: een bug waar ik uren naar zocht, of een fout die bleef terugkomen tot ik het structureel aanpakte.
Backend:
Fat service, thin routes: logica hoort op één centrale plek en niet verspreid over tientallen bestanden, want anders wijzig je iets op één plek en vergeet je de andere negen.
Prepared statements met parameters: database-queries worden vooraf klaargezet met placeholders en niet ter plekke aan elkaar geplakt, wat fouten scheelt en de code sneller maakt.
Frontend:
Event delegation: klikacties worden centraal afgehandeld en niet per element, omdat nieuwe elementen die je later toevoegt anders niet meewerken.
Input escaping: alles wat een gebruiker invoert wordt eerst schoongemaakt voordat het op de pagina verschijnt, wat maar drie regels code kost maar waar je wel aan moet denken.
Database:
Indexen op filter- en sorteerkolommen: zonder index moet de database alles doorzoeken, terwijl hij met index direct het antwoord vindt. Bij tienduizenden rijen is dat het verschil tussen een halve seconde en tien milliseconden.
Deze regels staan in een document dat de AI leest aan het begin van elke sessie, waardoor hij de valkuilen kent en ze vermijdt. Meestal.
Een encyclopedie van gemaakte fouten (en de lessen daaruit)
Elke fout die de AI maakt komt in de pitfall-bibliotheek, die inmiddels twintigduizend regels telt. Elke entry volgt hetzelfde format: wat ging er mis, hoe ziet de foute code eruit, hoe ziet de correcte code eruit, hoe herken je het, hoe erg is het, en — cruciaal — waarom maakt de AI deze fout. Die laatste vraag is het belangrijkst, want het gaat niet alleen om de fout te documenteren maar om te begrijpen waarom hij steeds opnieuw gemaakt wordt. Pas dan kun je hem voorkomen.
Een voorbeeld. In code geef je namen aan stukjes informatie, zoiets als "noem dit getal X." Als je later een nieuw getal wilt opslaan, zeg je "X is nu dit andere getal." Maar de AI zegt graag "noem dit getal X" terwijl er al iets X heet. En dan crasht alles. In de echte wereld kunnen twee mensen allebei Jan heten, maar in code moet elke naam uniek zijn, anders weet het systeem niet welke je bedoelt. De AI maakt deze fout omdat hij elke regel code als losstaand behandelt. Hij ziet regel 400 niet in de context van regel 50, waardoor hij in een lang bestand vergeet wat hij eerder schreef.
Dit is precies wat het Concordia-onderzoek beschrijft: niet spectaculaire fouten, maar saaie, alledaagse breekpunten die een ervaren programmeur in dertig seconden ziet, maar waar ik als niet-programmeur uren naar kan zoeken. Het verschil is dat ik ze nu vang voordat ze schade aanrichten, omdat de pitfall gedocumenteerd staat, de AI hem leest, en ik het bij de audit zie als hij toch in de fout gaat.
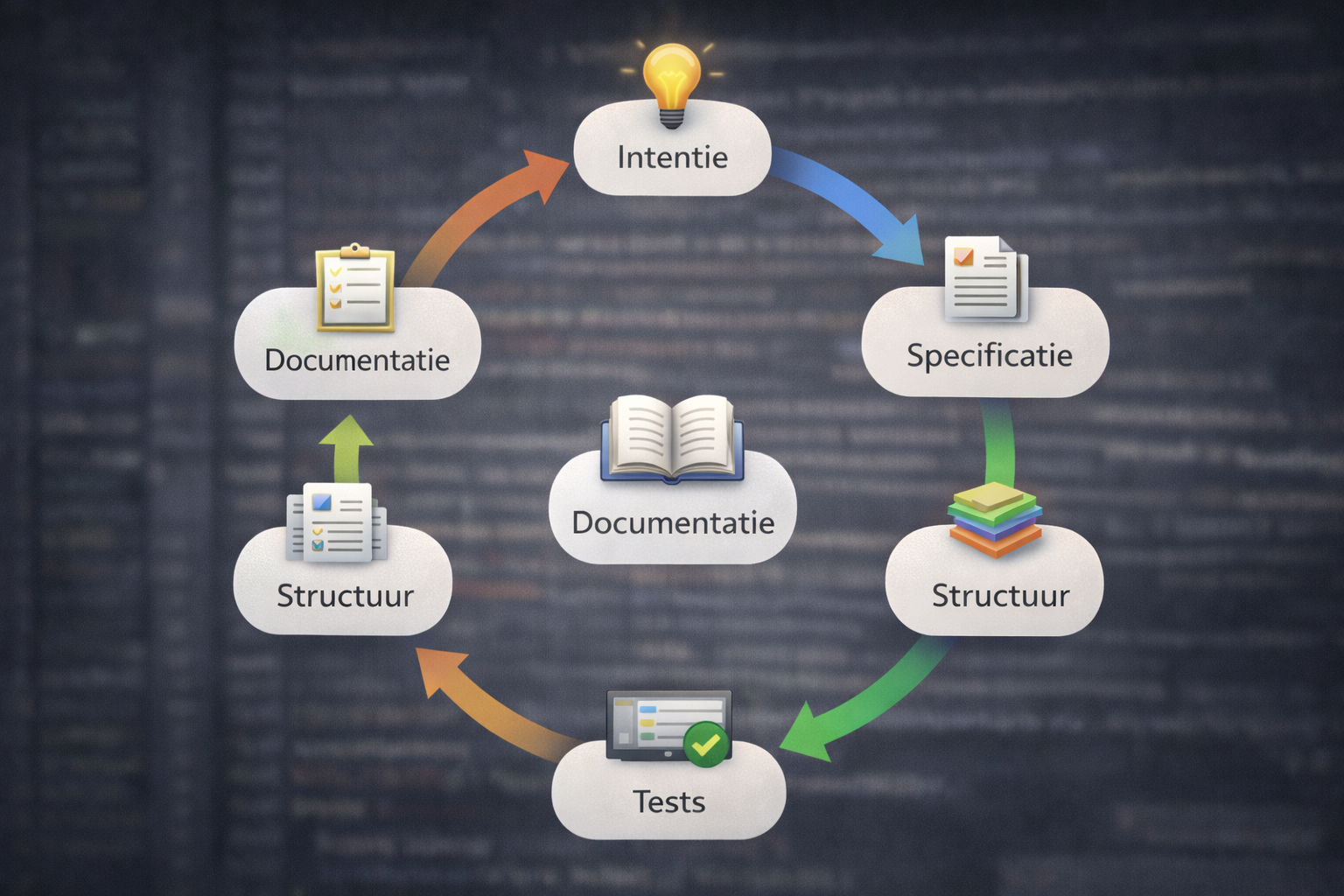
Van prompt tot bewijs
Elke nieuwe feature volgt hetzelfde pad. Niet omdat ik van bureaucratie houd, maar omdat ik geleerd heb wat er misgaat als je het niet doet.
Het begint met intentie. Niet "maak een app" maar "ik wil X kunnen doen, en dit is wanneer het goed werkt." Een concreet voorbeeld: niet "maak iets voor boodschappen" maar "ik wil snel items kunnen toevoegen aan een boodschappenlijst, ik wil frequent gekochte items zien, en ik wil dit ook als widget op mijn telefoon." Zonder die definitie is elke uitkomst acceptabel, ook de verkeerde. Dit is waar het meestal misgaat als mensen AI code laten schrijven: ze vragen om een feature en krijgen iets dat eruitziet als die feature. De AI levert wat je vraagt, maar als je niet precies vraagt krijg je niet precies wat je bedoelt.
Na de intentie komt de specificatie: wat hoort erbij en wat niet. Welke data moet worden opgeslagen — alleen de naam van het item, of ook waar ik het koop, of ook de prijs? Welke regels gelden altijd — een item moet een naam hebben, duplicaten worden samengevoegd. Wat gebeurt er als ik offline ben — werkt het dan nog? En welke tests bewijzen dat het werkt — als ik twee keer hetzelfde item toevoeg, staat het dan één keer in de lijst met een hogere telling?
Dan de structuur: een vaste indeling van bestanden en mappen, een document met afspraken. Dit klinkt als overhead, maar het voorkomt dat je na drie maanden niet meer weet waar iets staat.
Daarna de data-laag en logica, voordat je aan de interface begint. Eerst de database-tabel waar de informatie wordt opgeslagen, dan de service die regelt hoe items worden toegevoegd en opgehaald, en de validatie die checkt of de invoer klopt. Pas als dat allemaal werkt komen de schermen die de gebruiker ziet. De volgorde is belangrijk: als je begint met de interface is de verleiding groot om "even snel" logica in de schermcode te zetten, en dan zit het daar voor altijd — onzichtbaar, moeilijk te vinden, en onmogelijk te hergebruiken.
Dan tests, voordat het er mooi uitziet. Niet uitgebreide testsuites — ik ben geen enterprise-ontwikkelaar — maar de kritieke paden. Voeg een item toe: staat het in de lijst? Voeg het nogmaals toe: is er nog steeds maar één? Verwijder het: is het weg? Dit zijn simpele checks, maar ze bewijzen dat het werkt in plaats van dat "het lijkt te werken."
Dan pas de implementatie van de interface, oftewel wat de gebruiker daadwerkelijk ziet en waar hij op klikt. De AI genereert varianten en ik kies niet de elegantste maar de meest voorspelbare — de variant die het makkelijkst te begrijpen en te repareren is.
En aan het eind: documentatie. Wat is er toegevoegd, welke beslissingen zijn genomen, welke fouten kwamen we tegen. Zodat de volgende sessie — of een andere AI — niet bij nul begint.
Wat het Concordia-onderzoek mist
Het onderzoek test AI in isolatie. Eén prompt, één stuk gegenereerde code, één test. Geen context, geen geschiedenis, geen geleerde lessen. Dat is wetenschappelijk zuiver, maar het is niet hoe mensen in de praktijk met AI werken.
In mijn wereld heeft de AI toegang tot zevenhonderd regels projectinstructies. Hij weet hoe dit specifieke project in elkaar zit, welke conventies gelden, welke bestanden waar staan. Hij heeft toegang tot twintigduizend regels aan eerdere fouten. Als hij een patroon schrijft dat in het verleden problemen gaf, kan hij dat weten. En hij heeft toegang tot honderdtwintig documenten over opgeloste uitdagingen — niet alleen wat de oplossing was, maar ook waarom andere oplossingen niet werkten.
De onderzoekers vonden dat voorbeelden meegeven vier tot zeven procent helpt. Dat klinkt marginaal. Maar zij gaven een paar voorbeelden. Ik geef de complete geschiedenis.
Er is nog iets wat het onderzoek mist, en wat Mark Vletter me hielp inzien. De bouwers van AI-tools denken in productiewaardige code, omdat dat hun wereld is. Enterprise-software, teams van developers, continuous integration. Wat ik doe, namelijk persoonlijke software bouwen met discipline maar zonder enterprise-eisen, is een usecase die ze niet goed kennen. Ze hebben deze richting niet helemaal gemist, maar het is ook niet waar hun aandacht ligt. En daardoor onderschatten ze hoeveel ruimte er is voor mensen zoals ik. En daar zijn er miljoenen van die aan het ontdekken zijn wat je met AI-gegenereerde code allemaal kunt.
Er is nog een verschil. Het onderzoek meet of AI in één poging correcte code genereert. Maar dat is niet hoe ik werk. Ik vraag de AI iets te maken, bekijk het resultaat, corrigeer wat niet klopt, vraag om aanpassingen, bekijk opnieuw. Het is een conversatie, geen examen. De vraag is niet of de eerste poging perfect is — dat is hij vrijwel nooit. De vraag is of het proces naar een goed resultaat leidt.
Ik testte dit door mijn documentatie aan een andere AI te geven — Gemini van Google, niet de AI waarmee ik bouw. Gemini las alles en vatte samen:
"Het systeem is een cyclus: bouwen, documenteren, controleren, fouten identificeren, oplossen, en de cyclus herhaalt zich."
Als een andere AI het kan lezen en begrijpen, is het repliceerbaar. En daarmee is het dus geen trucje dat alleen in mijn hoofd bestaat, maar een methode.
De grenzen van mijn claim
Dit is geen enterprise software. Ik bouw voor mezelf, niet voor duizenden gebruikers. De eisen zijn anders, de risico's zijn anders, de gevolgen van een bug zijn anders. Als mijn boodschappenlijst crasht, mis ik de kaas. Als een banksysteem crasht, missen mensen hun salaris.
Laat ik eerlijk zijn over de technische complexiteit: ThetaOS is op zich geen ingewikkelde applicatie. Het gaat van ruwe data naar informatie naar weergave. Dat is technisch niet complex. Ik bouw geen real-time systemen waar milliseconden tellen en geen zware algoritmes die wiskundige precisie vereisen. Mijn uitdaging zit niet in de techniek, maar in de discipline om het schoon en schaalbaar te houden.
Binnen die grenzen is er een enorme ruimte. En die is echt veel groter dan de meeste "AI-experts" zich bewust zijn. Persoonlijke tools, administratie, dashboards, workflows, automatisering. Ik ben overigens iets heel anders aan het bouwen, iets dat pas emergent wordt als je voorbij deze beperkende silo's kijkt. Dingen die je leven makkelijker maken zonder dat een fout catastrofaal is. Die ruimte benutten de meeste mensen niet, omdat ze zich niet bewust zijn of geloven dat het niet kan.
Drie vragen voor wie AI-code laat schrijven
AI-gegenereerde code is niet inherent onbetrouwbaar. Een team van menselijke developers overigens ook niet. AI-gegenereerde code zonder borging is onbetrouwbaar. Het verschil zit niet in de technologie, maar in de begrenzing.
De investering is reëel: vijfhonderd uur, twintigduizend regels foutdocumentatie, dagelijkse audits. Maar het resultaat is ook reëel: een systeem dat werkt, schaalt, en auditbaar is. Niet "het werkt op mijn machine" maar "hier is waarom het werkt en hoe je het controleert."
Wat betekent dit voor je organisatie? Stel drie vragen aan teams die met AI code schrijven.
Ten eerste: welke regels zijn niet onderhandelbaar, en hoe worden ze afgedwongen? Als het antwoord is "we vertrouwen op de ontwikkelaar" is er geen borging. Regels die niet gecontroleerd worden, zijn suggesties.
Ten tweede: hoe wordt gecontroleerd of de code niet alleen werkt, maar ook goed gestructureerd is? Code kan perfect functioneren en tegelijk een onderhoudsnachtmerrie zijn. Vraag naar duplicatie, naar bestandsgrootte, naar technische schuld. Als niemand dat meet, weet niemand hoe erg het is.
Ten derde: waar worden fouten gedocumenteerd, en hoe wordt voorkomen dat ze zich herhalen? Als elke ontwikkelaar dezelfde fouten opnieuw maakt, is er geen leerproces. De AI leert niet tussen sessies. Als niemand de fouten documenteert, begint elke sessie weer bij nul.
Als de antwoorden vaag zijn, is de code dat waarschijnlijk ook.
Voor wie zelf bouwt met AI
Sceptici hebben gelijk dat snelheid zonder borging gevaarlijk is. Maar hun reflex — dan moet het zwaar en centraal — is niet de enige oplossing.
Snel bouwen én controleerbaar blijven kan prima, maar het vraagt discipline: afspraken maken en checken of je je eraan houdt. AI maakt je niet beter, AI maakt je sneller. En sneller zonder structuur is sneller in de problemen.
De eerste stap is niet een framework kiezen of een tool installeren. De eerste stap is beslissen welke regels niet onderhandelbaar zijn. Dat hoef je niet zelf te bedenken — vraag het aan de AI. "Wat zijn de belangrijkste principes voor een systeem zoals dit? Welke fouten moet ik absoluut vermijden?" Wat ik deed was de output van dat gesprek door meerdere AI's laten valideren en cross-checken. Begin met drie regels. De drie dingen die, als ze misgaan, de meeste schade veroorzaken. En controleer bij elke sessie of ze gevolgd zijn.
Dan groeit het vanzelf. De vierde regel ontstaat als je een fout maakt die je niet wilt herhalen. De vijfde als je een patroon ziet dat steeds terugkomt. De pitfall-bibliotheek begint niet met twintigduizend regels — die begint met één fout die je twee keer maakte en dacht: dit nooit meer.
Wie geen systeem heeft, heeft aan AI alleen maar een snellere manier om rommel te maken. De snelheid werkt pas voor je als je weet wat je wilt bouwen, hoe je het wilt organiseren, en welke fouten je niet wilt maken. Zonder dat fundament blijf je dweilen met de kraan open.
Het kan vast nog veel beter, maar dit is wat ik tot dusver leerde
Ik weet zeker dat er fouten in mijn aanpak zitten die ik nog niet zie. Maar ik denk dat het delen van dit proces met anderen waardevol is, en dat het delen nieuwe inzichten, feedback en begrippen op mijn radar zet die ik dan snel kan implementeren om mijn codebase te verbeteren.
De scheiding tussen data, logica en interface kan waarschijnlijk nog strakker. En mijn auditsysteem is pas een 2 maanden oud, dus dat wordt steeds verder verfijnd. Dat is geen zwakte, dat is het punt: ik bouw een lerend systeem, geen afgerond product.
Ik nodig je uit om gaten te schieten. Vertel me waar ik dingen mis. De scherpste kritiek komt van mensen die het zelf doen, en dat is hoe dit beter wordt.
Voor wie dieper wil duiken: ik schrijf regelmatig over persoonlijk kennismanagement en de PKM Summit is de plek waar deze gesprekken plaatsvinden.
Ik schreef dit artikel mét AI (niet door AI). Vooral voor research en structuur, de ideeën zijn van mij, net als 85% van de tekst. Dat doe ik vooral bij technisch lastige teksten die ik een experts én leken wil uitleggen.